Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation de l'importation de données à partir de données Amazon S3
Pour importer des données S3 dans Aurora PostgreSQL
Tout d'abord, rassemblez les informations que vous devez fournir à la fonction. Il s'agit notamment du nom de la table sur l'instance de votre cluster de base de données Aurora PostgreSQL, de votre instance de Amazon S3 sont stockées. Pour de plus amples informations, veuillez consulter View an object (Afficher un objet) dans le Guide de l'utilisateur Amazon Simple Storage Service.
Note
L'importation de données partitionnées depuis Amazon S3 n'est pas prise en charge actuellement.
Obtenez le nom de la table dans laquelle la fonction
aws_s3.table_import_from_s3doit importer les données. À titre d'exemple, la commande suivante crée une tablet1qui peut être utilisée dans les étapes suivantes.postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));Obtenez les détails sur le compartiment Amazon S3 et les données à importer. Pour ce faire, ouvrez la console Amazon S3 à l'adresse https://console.aws.amazon.com/s3/
, puis choisissez Buckets. Trouvez le compartiment contenant vos données dans la liste. Sélectionnez le compartiment, ouvrez sa page Object overview (Présentation des objets), puis choisissez Properties (Propriétés). Notez le nom du compartiment, le chemin Région AWS, le et le type de fichier. Vous aurez besoin du nom Amazon Resource Name (ARN) pour configurer l'accès à Amazon S3 via un rôle IAM. Pour obtenir plus d'informations, consultez Configuration de l'accès à un compartiment Amazon S3. L'image suivante montre un exemple.
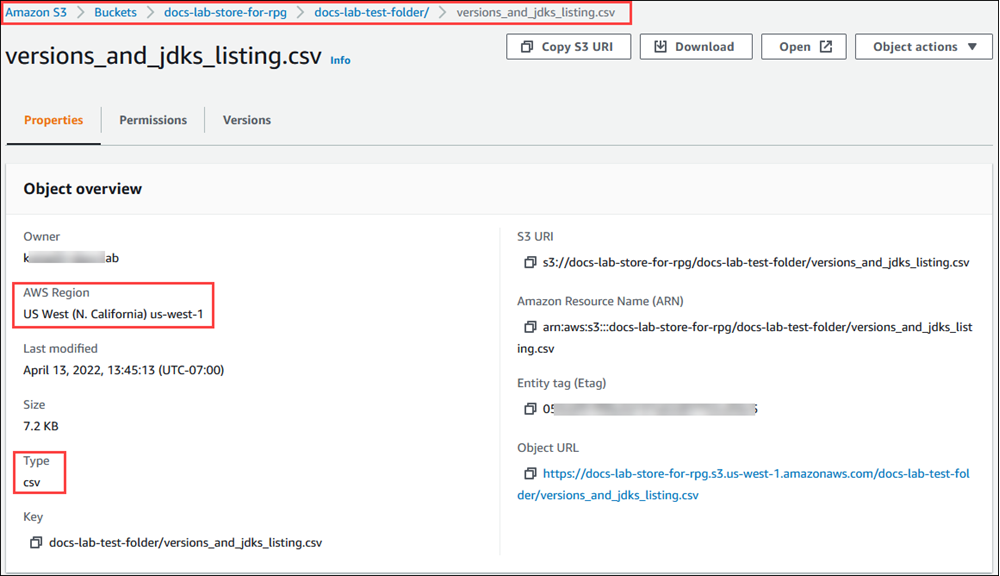
Vous pouvez vérifier le chemin d'accès aux données du compartiment Amazon S3 à l'aide de la AWS CLI commande
aws s3 cp. Si les informations sont correctes, cette commande télécharge une copie du fichier Amazon S3.aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
Configurez les autorisations sur votre cluster de base de données Aurora PostgreSQL pour permettre l'accès au fichier sur le compartiment Amazon S3. Pour ce faire, vous devez utiliser un rôle AWS Identity and Access Management (IAM) ou des informations d'identification de sécurité. Pour de plus amples informations, veuillez consulter Configuration de l'accès à un compartiment Amazon S3.
Fournissez le chemin et les autres détails de l'objet Amazon S3 recueillis (voir l'étape 2) à la fonction
create_s3_uripour construire un objet URI Amazon S3. Pour en savoir plus sur cette fonction, consultez aws_commons.create_s3_uri. Voici un exemple de construction de cet objet pendant une session psql.postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gsetDans l'étape suivante, vous transmettez cet objet (
aws_commons._s3_uri_1) à la fonctionaws_s3.table_import_from_s3pour importer les données dans la table.-
Appelez la fonction
aws_s3.table_import_from_s3pour importer les données d'Amazon S3 dans votre table. Pour obtenir des informations de référence, consultez aws_s3.table_import_from_s3. Pour obtenir des exemples, consultez Importation de données d'Amazon S3 vers votre cluster de base de données Aurora PostgreSQL.
