Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de la base de données mondiale Amazon Aurora
Avec la fonctionnalité Amazon Aurora Global Database, vous pouvez configurer plusieurs clusters de base de données Aurora répartis sur plusieurs Régions AWS. Aurora synchronise automatiquement toutes les modifications apportées dans le cluster de base de données principal avec un ou plusieurs clusters secondaires. Une base de données globale Aurora possède un cluster de base de données principal dans une région et jusqu'à 10 clusters de bases de données secondaires dans différentes régions. Cette configuration multirégionale permet une reprise rapide après une panne rare susceptible de toucher un ensemble Région AWS. Le fait de disposer d'une copie complète de toutes vos données dans plusieurs emplacements géographiques permet également d'effectuer des opérations de lecture à faible latence pour les applications qui se connectent depuis des emplacements très éloignés dans le monde entier.
Rubriques
Commencer à utiliser la base de données mondiale Amazon Aurora
Utilisation du transfert d'écriture dans une base de données globale Amazon Aurora
Utilisation du basculement ou du basculement dans la base de données globale Amazon Aurora
Utilisation des bases de données globales Amazon Aurora avec d'autres services AWS
Présentation de la base de données mondiale Amazon Aurora
En utilisant la fonctionnalité de base de données globale Amazon Aurora, vous pouvez exécuter vos applications distribuées dans le monde entier à l'aide d'une seule base de données Aurora qui couvre plusieurs Régions AWS bases de données.
Une base de données globale Aurora se compose d'une base de données principale Région AWS dans laquelle vos données sont écrites et d'un maximum de 10 bases secondaires en lecture seule. Régions AWS Vous effectuez des opérations d'écriture sur le cluster de base de données principal dans le cluster principal Région AWS. La méthode la plus pratique consiste à se connecter au point de terminaison Aurora Global Database Writer, qui pointe toujours vers le cluster de base de données principal, même après un basculement ou un basculement vers un autre. Région AWS Après chaque opération d'écriture, Aurora réplique les données vers le secondaire à l' Régions AWS aide d'une infrastructure dédiée, avec une latence généralement inférieure à une seconde.
Dans le schéma suivant, vous pouvez trouver un exemple de base de données globale Aurora qui s'étend sur deux Régions AWS.
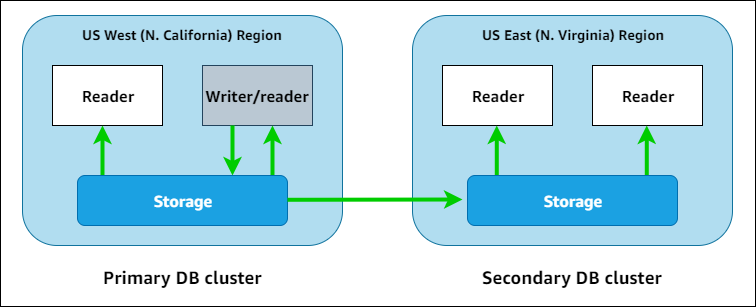
Vous pouvez étendre chaque cluster secondaire indépendamment, en ajoutant une ou plusieurs instances de lecteur Aurora pour traiter les charges de travail en lecture seule. Vous pouvez utiliser des Aurora Serverless v2 instances de lecteur pour une mise à l'échelle encore plus granulaire et flexible.
Seul le cluster principal exécute les opérations d'écriture. Les clients qui effectuent des opérations d'écriture se connectent au point de terminaison du rédacteur de la base de données globale Aurora, qui pointe toujours vers l'instance de base de données d'écriture du cluster principal. Comme le montre le schéma, Aurora utilise le volume de stockage du cluster et non le moteur de base de données pour une réplication rapide et peu coûteuse. Pour en savoir plus, veuillez consulter la section Présentation du stockage Amazon Aurora.
La base de données mondiale Aurora est conçue pour les applications présentes dans le monde entier. Les clusters de base de données secondaires en lecture seule répartis en plusieurs Régions AWS permettent d'optimiser les opérations de lecture au plus près des utilisateurs de l'application. En utilisant la fonctionnalité de transfert d'écriture, vous pouvez également configurer votre base de données globale afin que les clusters secondaires envoient des demandes d'écriture au cluster principal. Pour de plus amples informations, veuillez consulter Utilisation du transfert d'écriture dans une base de données globale Amazon Aurora.
Aurora Global Database prend en charge deux opérations différentes pour modifier la région de votre cluster de base de données principal, selon le scénario : le basculement de base de données Aurora Global et le basculement de base de données Aurora Global Database.
-
Pour les procédures opérationnelles planifiées telles que la rotation régionale, utilisez le mécanisme de basculement (précédemment appelé « basculement planifié géré »). Grâce à cette fonctionnalité, vous pouvez déplacer le cluster principal d'une base de données globale Aurora saine vers l'une de ses régions secondaires sans perte de données. Pour en savoir plus, veuillez consulter la section Réalisation de commutations pour les bases de données globales Amazon Aurora.
-
Pour récupérer votre base de données globale Aurora après une panne dans la région principale, utilisez le mécanisme de basculement. Avec cette fonctionnalité, vous effectuez un basculement de votre cluster de base de données principal vers une autre région (basculement entre régions). Pour en savoir plus, veuillez consulter la section Réalisation de basculements gérés pour les bases de données globales Aurora.
Avantages de la base de données mondiale Amazon Aurora
En utilisant la base de données globale Aurora, vous pouvez bénéficier des avantages suivants :
Lectures globales avec latence locale — Si vous avez des bureaux dans le monde entier, vous pouvez utiliser la base de données mondiale Aurora pour maintenir vos principales sources d'informations à jour au niveau principal Région AWS. Les bureaux de vos autres régions peuvent accéder aux informations dans leur propre région, avec une latence locale.
Clusters de base de données Aurora secondaires évolutifs : vous pouvez dimensionner vos clusters secondaires en ajoutant davantage d'instances en lecture seule à un cluster secondaire. Région AWS Le cluster secondaire est en lecture seule, il peut donc prendre en charge jusqu'à 16 instances de base de données en lecture seule au lieu de la limite habituelle de 15 pour un seul cluster Aurora.
Réplication rapide des clusters de base de données Aurora principaux vers les clusters de base de données Aurora secondaires : la réplication effectuée par Aurora Global Database a peu d'impact sur les performances du cluster de base de données principal. Les ressources des instances de base de données sont entièrement dévouées aux charges de travail d'application en lecture et en écriture.
Restauration après des pannes à l'échelle de la région : les clusters secondaires vous permettent de rendre une base de données globale Aurora disponible dans un nouveau serveur principal Région AWS plus rapidement (RTO inférieur) et avec moins de pertes de données (RPO inférieur) que les solutions de réplication traditionnelles.
Disponibilité des régions et des versions
La disponibilité et la prise en charge des fonctionnalités varient selon les versions spécifiques de chaque moteur de base de données Aurora, et selon les Régions AWS. Pour plus d'informations sur la disponibilité des versions et des régions avec la base de données mondiale Aurora, consultezRégions et moteurs de base de données pris en charge pour les bases de données mondiales Aurora.
Limites de la base de données mondiale Amazon Aurora
Les limitations suivantes s'appliquent actuellement à la base de données globale Aurora :
La base de données globale Aurora est disponible dans certaines versions Régions AWS et pour des versions spécifiques d'Aurora MySQL et d'Aurora PostgreSQL. Pour de plus amples informations, veuillez consulter Régions et moteurs de base de données pris en charge pour les bases de données mondiales Aurora.
La base de données globale Aurora a des exigences de configuration spécifiques pour les classes d'instances de base de données Aurora prises en charge Régions AWS, le nombre maximum de, etc. Pour de plus amples informations, veuillez consulter Configuration requise pour une base de données Amazon Aurora globale.
Pour assurer la compatibilité entre Aurora MySQL et MySQL 5.7, les commutations de bases de données globales Aurora nécessitent la version 2.09.1 ou une version mineure supérieure.
-
Vous pouvez effectuer des commutations ou des basculements interrégionaux gérés avec Aurora Global Database uniquement si les clusters de base de données principal et secondaire possèdent les mêmes versions de moteur majeures et secondaires. Selon le moteur et les versions du moteur, les niveaux de correctifs peuvent devoir être identiques ou les niveaux de correctif peuvent être différents. Pour obtenir la liste des moteurs et des versions de moteurs qui autorisent ces opérations entre les clusters principaux et secondaires avec différents niveaux de correctif, consultezCompatibilité des niveaux de correctif pour les commutations ou basculements entre régions gérés. Si les versions de votre moteur nécessitent des niveaux de correctifs identiques, vous pouvez effectuer le basculement manuellement en suivant les étapes décrites dansRéalisation de basculements manuels pour les bases de données globales Aurora.
La base de données globale Aurora ne prend actuellement pas en charge les fonctionnalités Aurora suivantes :
-
Aurora Serverless v1
-
Retour sur trace dans Aurora
-
Pour connaître les limites liées à l'utilisation de la fonctionnalité de proxy RDS avec la base de données globale Aurora, consultezLimites pour le proxy RDS avec les bases de données globales.
La mise à niveau automatique des versions mineures ne s'applique pas aux clusters Aurora MySQL et Aurora PostgreSQL qui font partie d'une base de données globale. Notez que vous pouvez spécifier ce paramètre pour une instance de base de données faisant partie d'un cluster de base de données globale, mais ce paramètre est sans effet.
Aurora Global Database ne prend actuellement pas en charge Aurora Auto Scaling pour les clusters de bases de données secondaires.
Pour utiliser les flux d'activité de base de données (DAS) sur une base de données globale Aurora exécutant Aurora MySQL 5.7, la version du moteur doit être la version 2.08 ou supérieure. Pour plus d'informations sur le DAS, consultezSurveillance d'Amazon Aurora à l'aide des flux d'activité de base de données.
-
Les limitations suivantes s'appliquent actuellement à la mise à niveau de la base de données globale Aurora :
Vous ne pouvez pas appliquer un groupe de paramètres personnalisés au cluster de base de données globale pendant que vous effectuez une mise à niveau majeure de la version de cette base de données globale Aurora. Vous créez vos groupes de paramètres personnalisés dans chaque région du cluster global et vous les appliquez manuellement aux clusters régionaux après la mise à niveau.
-
Avec une base de données globale Aurora basée sur Aurora MySQL, vous ne pouvez pas effectuer une mise à niveau sur place d'Aurora MySQL version 2 vers la version 3 si le paramètre
lower_case_table_namesest activé. Pour plus d'informations sur les méthodes que vous pouvez utiliser, consultez Mises à niveau de version majeure.. Avec Aurora Global Database, vous ne pouvez pas effectuer de mise à niveau de version majeure du moteur de base de données Aurora PostgreSQL si la fonctionnalité RPO (Recovery Point Objective) est activée. Pour en savoir plus sur la fonction RPO, veuillez consulter Gestion des bases RPOs de données globales basées sur Aurora PostgreSQL.
Avec une base de données globale Aurora, vous ne pouvez pas effectuer de mise à niveau de version mineure d'Aurora MySQL version 3.01 ou 3.02 vers la version 3.03 ou supérieure en utilisant le processus standard. Pour plus d'informations sur ce processus, consultez Mise à niveau d'Aurora MySQL par modification de la version du moteur.
Pour plus d'informations sur la mise à niveau de la base de données globale Aurora, consultezCréation d'une Amazon Aurora Global Database.
Vous ne pouvez pas arrêter ou démarrer les clusters de base de données Aurora individuellement dans votre base de données globale. Pour en savoir plus, veuillez consulter la section Arrêt et démarrage d'un cluster de bases de données Amazon Aurora.
Les instances de base de données Aurora Reader attachées au cluster de base de données Aurora secondaire peuvent redémarrer dans certaines circonstances. Si l'instance de base Région AWS de données d'écriture du serveur principal est redémarrée ou basculée, les instances de base de données de lecture des régions secondaires redémarrent également. Le cluster secondaire est alors indisponible jusqu'à ce que toutes les instances de base de données de lecture soient à nouveau synchronisées avec l'instance d'écriture du cluster de base de données principal. Le comportement du cluster principal lors du redémarrage ou d'un basculement est le même que pour un cluster de base de données unique et non global. Pour de plus amples informations, veuillez consulter Réplication avec Amazon Aurora.
Assurez-vous de bien comprendre les impacts qu'elles auront sur votre base de données globale avant d'apporter des modifications à votre cluster de base de données principal. Pour en savoir plus, veuillez consulter la section Reprise d'une base de données Amazon Aurora globale à partir d'une panne non planifiée.
La base de données globale Aurora ne prend actuellement pas en charge le
inaccessible-encryption-credentials-recoverablestatut lorsqu'Amazon Aurora perd l'accès à la AWS KMS clé du cluster de bases de données. Dans ce cas, le cluster de base de données chiffré passe directement à l'étatinaccessible-encryption-credentialsterminal. Pour plus d'informations sur les états, consultez Affichage du statut du cluster de base de données.-
Secrets Manager ne prend pas en charge la base de données globale Aurora. Lorsque vous ajoutez une région à une base de données globale, vous devez d'abord désactiver l'intégration de Secrets Manager pour l'instance de base de données.
-
Les clusters de base de données basés sur Aurora PostgreSQL qui utilisent la base de données globale Aurora présentent les limites suivantes :
La gestion du cache de cluster n'est pas prise en charge pour les clusters de bases de données secondaires Aurora PostgreSQL qui font partie des bases de données globales Aurora.
-
Si le cluster de base de données principal de votre base de données globale est basé sur une réplique d'une instance Amazon RDS PostgreSQL, vous ne pouvez pas créer de cluster secondaire. N'essayez pas de créer un secondaire à partir de ce cluster à l' AWS Management Console aide de l'opération AWS CLI, de ou de l'
CreateDBClusterAPI. Vos tentatives expireront et le cluster secondaire ne sera pas créé.
Nous vous recommandons de créer des clusters de base de données secondaires pour vos bases de données globales en utilisant la même version du moteur de base de données Aurora que le principal. Pour de plus amples informations, veuillez consulter Création d'une base de données Amazon Aurora globale.
