Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture Babelfish
Lorsque vous créez un cluster Aurora PostgreSQL dans lequel Babelfish est activé, Aurora approvisionne ce cluster avec une base de données PostgreSQL nommée babelfish_db. Cette base de données héberge l'ensemble des objets et structures SQL Server migrés.
Note
Dans un cluster Aurora PostgreSQL, le nom de base de données babelfish_db est réservé à Babelfish. La création de votre propre base de données « babelfish_db » sur un cluster de bases de données Babelfish empêche Aurora d'allouer Babelfish.
Lorsque vous vous connectez au port TDS, la session est placée dans la base de données babelfish_db. Depuis T-SQL, la structure ressemble à celle d'une connexion à une instance SQL Server. Vous pouvez consulter les bases de données master, msdb et tempdb ainsi que le catalogue sys.databases. Vous pouvez créer des bases de données utilisateur supplémentaires et passer d'une base de données à l'autre à l'aide de l'instruction USE. Lorsque vous créez une base de données utilisateur SQL Server, celle-ci est mise à plat dans la base de données PostgreSQL babelfish_db. Votre base de données conserve une syntaxe et une sémantique inter-bases de données identiques ou semblables à celles fournies par SQL Server.
Utilisation de Babelfish avec une ou plusieurs bases de données
Lorsque vous créez un cluster Aurora PostgreSQL à utiliser avec Babelfish, vous pouvez choisir d'utiliser une base de données SQL Server individuellement ou plusieurs bases de données SQL Server ensemble. Votre choix détermine la façon dont les noms des schémas SQL Server contenus dans la base de données babelfish_db apparaissent à partir d'Aurora PostgreSQL. Le mode de migration est stocké dans le paramètre migration_mode. Vous ne devez pas modifier ce paramètre après avoir créé votre cluster car vous pourriez perdre l'accès à tous vos objets SQL précédemment créés.
En mode single-db, les noms des schémas de la base de données SQL Server restent les mêmes dans la base de données babelfish_db de PostgreSQL. Si vous choisissez de ne migrer qu'une seule base de données, les noms de schémas de la base de données utilisateur migrée peuvent être référencés dans PostgreSQL avec les mêmes noms que ceux utilisés dans SQL Server. Par exemple, les schémas dbo et smith résident dans la base de données dbA.
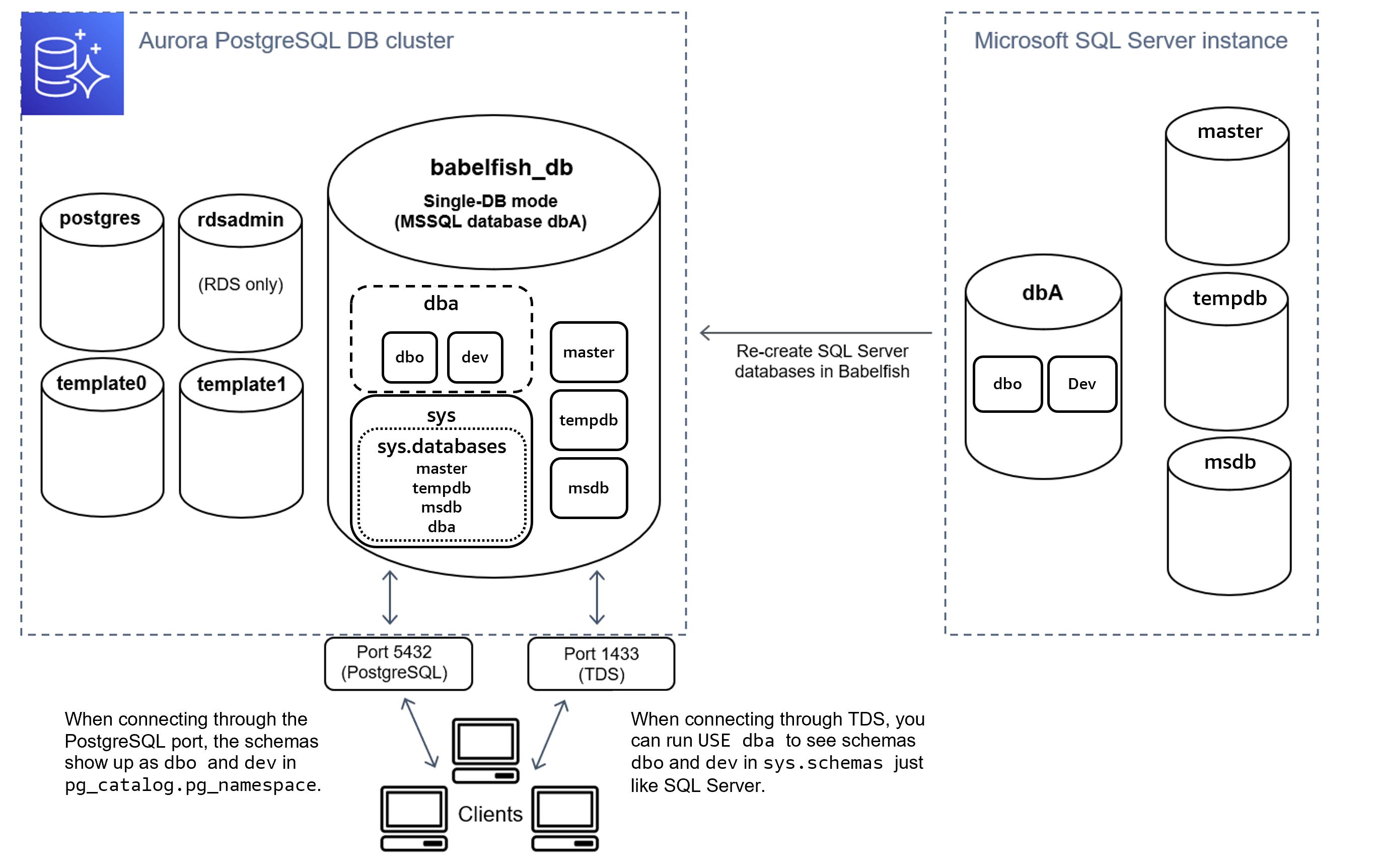
Lorsque vous vous connectez via TDS, vous pouvez exécuter USE dba pour voir les schémas dbo et dev depuis T-SQL, comme vous le feriez dans SQL Server. Les noms de schémas inchangés sont également visibles depuis PostgreSQL.
En mode à plusieurs bases de données, les noms de schémas des bases de données utilisateur deviennent dbname_schemaname lorsqu'ils font l'objet d'un accès depuis PostgreSQL. Les noms de schémas restent les mêmes lorsqu'ils font l'objet d'un accès depuis T-SQL.
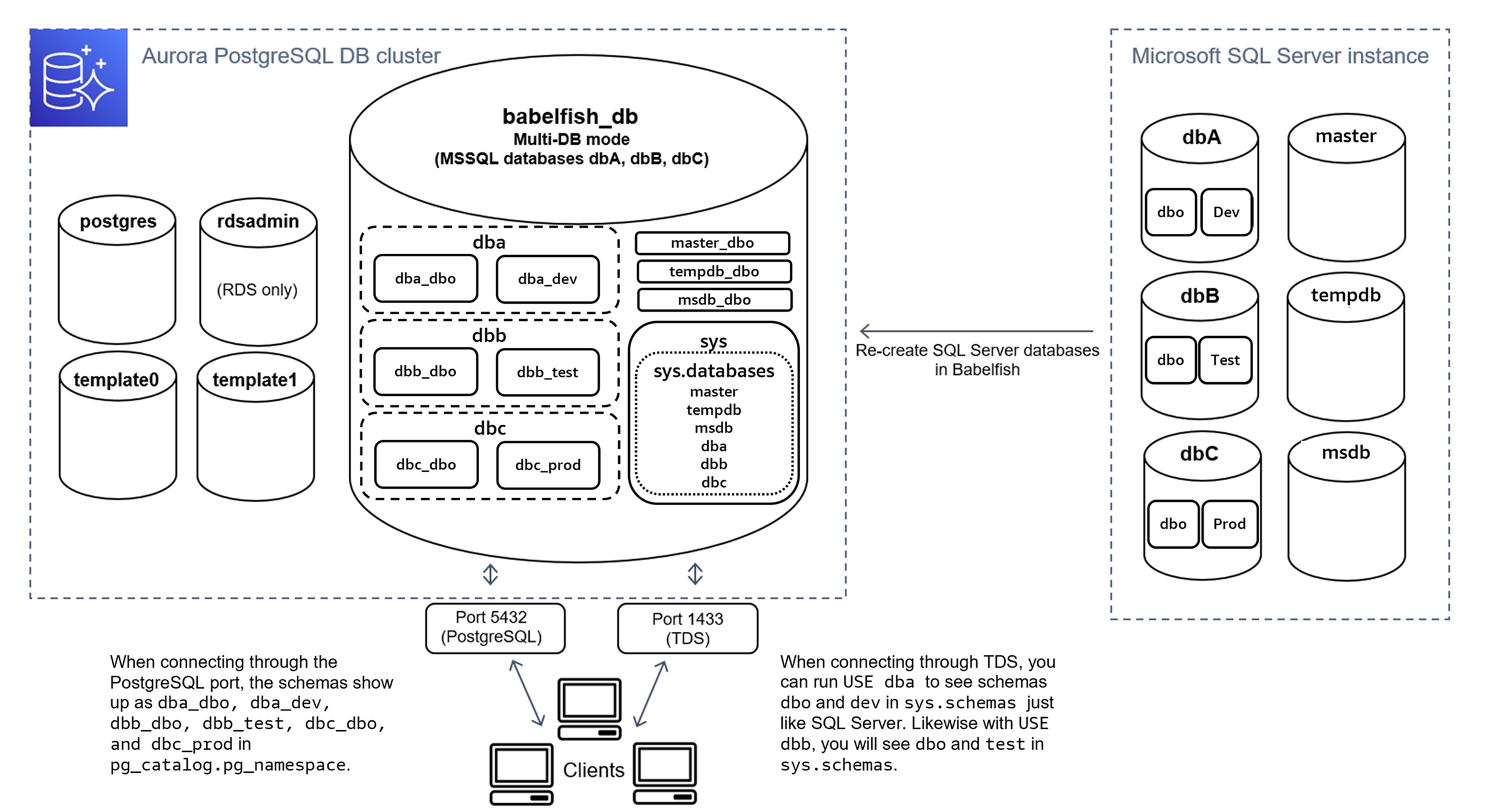
Comme le montre l'image, le mode à une base de données et le mode à plusieurs bases de données sont identiques à la procédure de connexion via le port TDS et d'utilisation de T-SQL dans SQL Server. Par exemple, USE dbA répertorie les schémas dbo et dev comme dans SQL Server. Les noms de schémas mappés, tels que dba_dbo et dba_dev, sont visibles depuis PostgreSQL.
Vos schémas sont toujours contenus dans chacune des bases de données. Le nom de chaque base de données précède le nom du schéma SQL Server, avec un trait de soulignement comme délimiteur. Par exemple :
-
dbacontientdba_dboetdba_dev. -
dbbcontientdbb_dboetdbb_test. -
dbccontientdbc_dboetdbc_prod.
Dans la base de données babelfish_db, l'utilisateur T-SQL doit toujours exécuter USE
dbname pour modifier le contexte de la base de données, afin que la présentation reste semblable à celle de SQL Server.
Choix d'un mode de migration
Chaque mode de migration présente des avantages et des inconvénients. Choisissez votre mode de migration en fonction du nombre de bases de données utilisateur dont vous disposez et de vos plans de migration. Après avoir créé un cluster à utiliser avec Babelfish, vous ne devez pas changer le mode de migration car vous pourriez perdre l'accès à tous vos objets SQL précédemment créés. Lorsque vous choisissez un mode de migration, tenez compte des exigences de vos bases de données utilisateur et de vos clients.
Lorsque vous créez un cluster à utiliser avec Babelfish, Aurora PostgreSQL crée les bases de données système, master et tempdb. Si vous avez créé ou modifié des objets dans les bases de données système (master ou tempdb), veillez à recréer ces objets dans votre nouveau cluster. Contrairement à SQL Server, Babelfish ne se réinitialise pas tempdb après le redémarrage d'un cluster.
Utilisez le mode de migration d'une base de données individuelle dans les cas suivants :
-
Si vous migrez une base de données SQL Server individuelle. En mode Base de données individuelle, les noms des schémas migrés, lorsqu'ils font l'objet d'un accès depuis PostgreSQL, sont identiques aux noms des schémas SQL Server d'origine. Cela permet de réduire les modifications de code apportées aux requêtes SQL existantes si vous souhaitez les optimiser pour les exécuter avec une connexion PostgreSQL.
-
Si votre objectif final est une migration complète vers l'instance native d'Aurora PostgreSQL. Avant toute migration, regroupez vos schémas en un seul (
dbo), puis procédez à une migration vers un seul cluster pour limiter les modifications nécessaires.
Utilisez le mode de migration de plusieurs bases de données dans les cas suivants :
-
Si vous souhaitez bénéficier de l'expérience SQL Server par défaut avec plusieurs bases de données utilisateur dans la même instance.
-
Si plusieurs bases de données utilisateur doivent être migrées ensemble.
