Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Ajouter des données à une source (cluster Aurora DB) et les interroger
Pour terminer la création d'une intégration zéro ETL qui réplique les données d' vers Amazon Redshift, vous devez créer une base de données dans la destination cible.
Pour les connexions avec Amazon Redshift, connectez-vous à votre cluster ou groupe de travail Amazon Redshift et créez une base de données avec une référence à votre identifiant d'intégration. Vous pouvez ensuite ajouter des données à votre cluster de Aurora DB source et les voir répliquées dans Amazon Redshift ou. Amazon SageMaker
Rubriques
Création d'une base de données cible
Avant de pouvoir commencer à répliquer des données dans Amazon Redshift, après avoir créé une intégration, vous devez créer une base de données dans votre entrepôt de données cible. Cette base de données doit inclure une référence à l'identifiant d'intégration. Vous pouvez utiliser la console Amazon Redshift ou l'éditeur de requête v2 pour créer la base de données.
Pour obtenir des instructions sur la création d'une base de données de destination, consultez Création d'une base de données de destination dans Amazon Redshift.
Ajout de données au cluster source
Après avoir configuré votre intégration, vous pouvez remplir le cluster de base de données DB source avec les données que vous souhaitez répliquer dans votre entrepôt de données.
Note
Il existe des différences entre les types de données dans , Amazon Aurora et dans l'entrepôt d'analyse cible. Pour un tableau des mappages de types de données, consultez Différences de type de données entre les bases de données Aurora et Amazon Redshift.
Connectez-vous d'abord au cluster de source à l'aide du client MySQL ou PostgreSQL de votre choix. Pour obtenir des instructions, veuillez consulter Connexion à un cluster de bases de données Amazon Aurora.
Ensuite, créez une table et insérez une ligne d'exemples de données.
Important
Assurez-vous que la table possède une clé primaire. Sinon, elle ne peut pas être répliquée vers l'entrepôt de données cible.
Les utilitaires PostgreSQL pg_dump et pg_restore créent d'abord des tables sans clé primaire, puis les ajoutent par la suite. Si vous utilisez l'un de ces utilitaires, nous vous recommandons de créer d'abord un schéma, puis de charger les données dans une commande distincte.
MySQL MySQL
L'exemple suivant utilise l'utilitaire MySQL Workbench
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
PostgreSQL
L'exemple suivant utilise le terminal psql interactif PostgreSQL. Lorsque vous vous connectez au cluster, incluez la base de données nommée que vous avez spécifiée lors de la création de l'intégration.
psql -hmycluster.cluster-123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Interrogation de vos données dans Amazon Redshift
Une fois que vous avez ajouté des données au cluster Aurora DB de la , celles-ci sont répliquées dans la base de données de destination et sont prêtes à être interrogées.
Pour interroger les données répliquées
-
Accédez à la console Amazon Redshift et choisissez Éditeur de requête v2 dans le panneau de navigation de gauche.
-
Connectez-vous à votre cluster ou groupe de travail et choisissez votre base de données de destination (que vous avez créée à partir de l'intégration) dans le menu déroulant (destination_database dans cet exemple). Pour obtenir des instructions sur la création d'une base de données de destination, consultez Création d'une base de données de destination dans Amazon Redshift.
-
Utilisez une instruction SELECT pour interroger vos données. Dans cet exemple, vous pouvez exécuter la commande suivante pour sélectionner toutes les données de la table que vous avez créée dans le cluster Aurora DB de la source :
SELECT * frommy_db."books_table";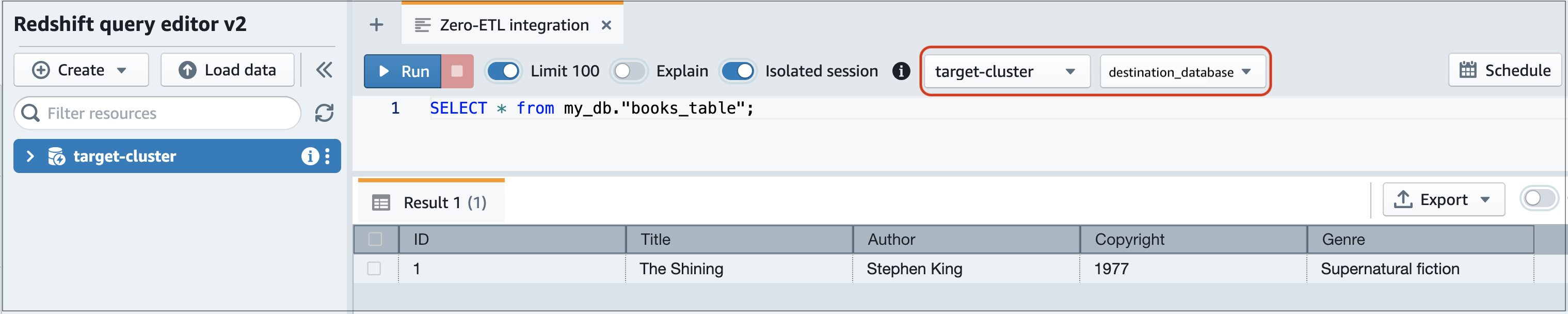
-
my_db -
books_table
-
Vous pouvez également interroger les données à l'aide d'un client de ligne de commande. Par exemple :
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
Note
Pour appliquer la sensibilité à la casse, utilisez des guillemets doubles (« ») pour les noms de schéma, de table et de colonne. Pour plus d'informations, consultez enable_case_sensitive_identifier.
Différences de type de données entre les bases de données Aurora et Amazon Redshift
Les Aurora PostgreSQL avec les types de données de destination correspondants. Amazon Aurora ne prend actuellement en charge que ces types de données pour les intégrations sans ETL.
Si une table du cluster de base de données de votre de données source inclut un type de données non pris en charge, la table est désynchronisée et n'est pas consommable par la cible de destination. Le streaming de la source vers la cible se poursuit, mais le tableau contenant le type de données non pris en charge n'est pas disponible. Pour corriger le tableau et le rendre disponible dans la destination cible, vous devez annuler manuellement la modification la plus importante, puis actualiser l'intégration en exécutantALTER DATABASE...INTEGRATION
REFRESH.
Note
Vous ne pouvez pas actualiser les intégrations Zero-ETL avec un Amazon SageMaker Lakehouse. Supprimez plutôt l'intégration et réessayez de la créer.
| Type de données Aurora MySQL | Type de données cible | Description | Limites |
|---|---|---|---|
| INT | INTEGER | Entier signé sur quatre octets | Aucun |
| SMALLINT | SMALLINT | Entier signé sur deux octets | Aucun |
| TINYINT | SMALLINT | Entier signé sur deux octets | Aucun |
| MEDIUMINT | INTEGER | Entier signé sur quatre octets | Aucun |
| BIGINT | BIGINT | Entier signé sur huit octets | Aucun |
| INT UNSIGNED | BIGINT | Entier signé sur huit octets | Aucun |
| TINYINT UNSIGNED | SMALLINT | Entier signé sur deux octets | Aucun |
| MEDIUMINT UNSIGNED | INTEGER | Entier signé sur quatre octets | Aucun |
| BIGINT UNSIGNED | DECIMAL(20,0) | Valeur numérique exacte avec précision sélectionnable | Aucun |
| DÉCIMAL (p, s) = NUMÉRIQUE (p, s) | DECIMAL(p,s) | Valeur numérique exacte avec précision sélectionnable |
La précision supérieure à 38 et l'échelle supérieure à 37 ne sont pas prises en charge |
| DÉCIMAL (p, s) NON SIGNÉ = NUMÉRIQUE (p, s) NON SIGNÉ | DECIMAL(p,s) | Valeur numérique exacte avec précision sélectionnable |
La précision supérieure à 38 et l'échelle supérieure à 37 ne sont pas prises en charge |
| FLOAT4/RÉEL | REAL | Nombre à virgule flottante simple précision | Aucun |
| FLOAT4/REAL NON SIGNÉ | REAL | Nombre à virgule flottante simple précision | Aucun |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Nombre à virgule flottante de double précision | Aucun |
| DOUBLE/REAL/FLOAT8 NON SIGNÉ | DOUBLE PRECISION | Nombre à virgule flottante de double précision | Aucun |
| BIT (n) | VARBYTE(8) | Valeur binaire de longueur variable | Aucun |
| BINAIRE (n) | VARBYTE (n) | Valeur binaire de longueur variable | Aucun |
| VARBINAIRE (n) | VARBYTE (n) | Valeur binaire de longueur variable | Aucun |
| CHAR(n) | VARCHAR(n) | Valeur de chaîne de longueur variable | Aucun |
| VARCHAR(n) | VARCHAR(n) | Valeur de chaîne de longueur variable | Aucun |
| TEXT | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| TINYTEXT | VARCHAR(255) | Valeur de chaîne de longueur variable jusqu'à 255 caractères | Aucun |
| MEDIUMTEXT | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| LONGTEXT | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| ENUM | VARCHAR(1020) | Valeur de chaîne de longueur variable jusqu'à 1 020 caractères | Aucun |
| SET | VARCHAR(1020) | Valeur de chaîne de longueur variable jusqu'à 1 020 caractères | Aucun |
| DATE | DATE | Date calendaire (année, mois, jour) | Aucun |
| DATETIME | TIMESTAMP | Date et heure (sans fuseau horaire) | Aucun |
| HORODATAGE (p) | TIMESTAMP | Date et heure (sans fuseau horaire) | Aucun |
| TIME | VARCHAR(18) | Valeur de chaîne de longueur variable jusqu'à 18 caractères | Aucun |
| YEAR | VARCHAR(4) | Valeur de chaîne de longueur variable jusqu'à 4 caractères | Aucun |
| JSON | SUPER | Données ou documents semi-structurés sous forme de valeurs | Aucun |
Intégrations sans ETL pour ne prend pas en charge les types de données personnalisés ni les types de données créés par des extensions.
| Type de données | Type de données Amazon Redshift | Description | Limites |
|---|---|---|---|
| array | SUPER | Données ou documents semi-structurés sous forme de valeurs | Aucun |
| bigint | BIGINT | Entier signé sur huit octets | Aucun |
| grande série | BIGINT | Entier signé sur huit octets | Aucun |
| bit variable (n) | VARBYTE (n) | Valeur binaire de longueur variable jusqu'à 16 777 216 octets | Aucun |
| bit (n) | VARBYTE (n) | Valeur binaire de longueur variable jusqu'à 16 777 216 octets | Aucun |
| un peu, un peu variable | VARBYTE (16777216) | Valeur binaire de longueur variable jusqu'à 16 777 216 octets | Aucun |
| boolean | BOOLEAN | Booléen logique (vrai/faux) | Aucun |
| par le thé | VARBYTE (16777216) | Valeur binaire de longueur variable jusqu'à 16 777 216 octets | Aucun |
| chaise (n) | CHAR(n) | Valeur de chaîne de caractères de longueur fixe jusqu'à 65 535 octets | Aucun |
| caractère variable (n) | VARCHAR(65535) | Valeur de chaîne de caractères de longueur variable jusqu'à 65 535 caractères | Aucun |
| cid | BIGINT |
Entier signé sur huit octets |
Aucun |
| cidr |
GUERRE (19) |
Valeur de chaîne de longueur variable jusqu'à 19 caractères |
Aucun |
| date | DATE | Date calendaire (année, mois, jour) |
Les valeurs supérieures à 294 276 après Jésus-Christ ne sont pas prises en charge |
| double precision | DOUBLE PRECISION | Chiffres à virgule flottante à double précision | Les valeurs inférieures à la normale ne sont pas entièrement prises en charge |
|
vecteur gts |
VARCHAR(65535) |
Valeur de chaîne de longueur variable jusqu'à 65 535 caractères |
Aucun |
| inet |
GUERRE (19) |
Valeur de chaîne de longueur variable jusqu'à 19 caractères |
Aucun |
| entier | INTEGER | Entier signé sur quatre octets | Aucun |
|
vecteur int2 |
SUPER | Données ou documents semi-structurés sous forme de valeurs. | Aucun |
| interval | INTERVAL | Durée du temps | Seuls les types INTERVAL qui spécifient un qualificatif annuel par mois ou un qualificatif journalier par seconde sont pris en charge. |
| json | SUPER | Données ou documents semi-structurés sous forme de valeurs | Aucun |
| jsonb | SUPER | Données ou documents semi-structurés sous forme de valeurs | Aucun |
| chemin json | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
|
macaddr |
GUERRE (17) | Valeur de chaîne de longueur variable jusqu'à 17 caractères | Aucun |
|
macaddr8 |
GUERRE (23) | Valeur de chaîne de longueur variable jusqu'à 23 caractères | Aucun |
| money | DÉCIMAL (20,3) | Montant en devise | Aucun |
| name | GUERRE (64) | Valeur de chaîne de longueur variable jusqu'à 64 caractères | Aucun |
| numeric(p,s) | DECIMAL(p,s) | Valeur de précision fixe définie par l'utilisateur |
|
| oid | BIGINT | Entier signé sur huit octets | Aucun |
| vecteur oid | SUPER | Données ou documents semi-structurés sous forme de valeurs. | Aucun |
| pg_brin_bloom_summary | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| pg_dependencies | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| pg_lsn | GUERRE (17) | Valeur de chaîne de longueur variable jusqu'à 17 caractères | Aucun |
| pg_mcv_list | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| pg_ndistinct | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| pg_node_tree | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| pg_snapshot | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| real | REAL | Nombre à virgule flottante simple précision | Les valeurs inférieures à la normale ne sont pas entièrement prises en charge |
| récurseur | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| smallint | SMALLINT | Entier signé sur deux octets | Aucun |
| petite série | SMALLINT | Entier signé sur deux octets | Aucun |
| serial | INTEGER | Entier signé sur quatre octets | Aucun |
| text | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| tid | GUERRE (23) | Valeur de chaîne de longueur variable jusqu'à 23 caractères | Aucun |
| heure [(p)] sans fuseau horaire | GUERRE (19) | Valeur de chaîne de longueur variable jusqu'à 19 caractères | Infinityet -Infinity valeurs non prises en charge |
| heure [(p)] avec fuseau horaire | GUERRE (22) | Valeur de chaîne de longueur variable jusqu'à 22 caractères | Infinityet -Infinity valeurs non prises en charge |
| horodatage [(p)] sans fuseau horaire | TIMESTAMP | Date et heure (sans fuseau horaire) |
|
| horodatage [(p)] avec fuseau horaire | TIMESTAMPTZ | Date et heure (avec fuseau horaire) |
|
| tsquery | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| vecteur ts | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| txid_instantané | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
| uuid | GUERRE (36) | Chaîne de 36 caractères de longueur variable | Aucun |
| xid | BIGINT | Entier signé sur huit octets | Aucun |
| xid8 | DÉCIMAL (20, 0) | Décimal à précision fixe | Aucun |
| xml | VARCHAR(65535) | Valeur de chaîne de longueur variable jusqu'à 65 535 caractères | Aucun |
Opérations DDL pour
Amazon Redshift est dérivé de PostgreSQL. Il partage donc plusieurs fonctionnalités avec RDS pour PostgreSQL . Les intégrations Zero-ETL tirent parti de ces similitudes pour rationaliser la réplication des données de vers Amazon Redshift, en mappant les bases de données par nom et en utilisant la base de données, le schéma et la structure de table partagés.
Tenez compte des points suivants lors de la gestion des :
-
L'isolation est gérée au niveau de la base de données.
-
La réplication s'effectue au niveau de la base de données.
-
sont mappées aux bases de données Amazon Redshift par leur nom, les données étant transmises à la base de données Redshift renommée correspondante si l'original est renommé.
Malgré leurs similitudes, Amazon Redshift et . Les sections suivantes décrivent les réponses du système Amazon Redshift pour les opérations DDL courantes.
Opérations sur les bases
Le tableau suivant indique les réponses du système pour les opérations DDL de base de données.
| Fonctionnement DDL | Réponse du système Redshift |
|---|---|
CREATE DATABASE |
Aucune opération |
DROP DATABASE |
Amazon Redshift supprime toutes les données de la base de données Redshift cible. |
RENAME DATABASE |
Amazon Redshift supprime toutes les données de la base de données cible d'origine et resynchronise les données de la nouvelle base de données cible. Si la nouvelle base de données n'existe pas, vous devez la créer manuellement. Pour obtenir des instructions, consultez Créer une base de données de destination dans Amazon Redshift. |
Opérations sur le schéma
Le tableau suivant indique les réponses du système pour les opérations DDL du schéma.
| Fonctionnement DDL | Réponse du système Redshift |
|---|---|
CREATE SCHEMA |
Aucune opération |
DROP SCHEMA |
Amazon Redshift supprime le schéma d'origine. |
RENAME SCHEMA |
Amazon Redshift supprime le schéma d'origine puis resynchronise les données dans le nouveau schéma. |
Opérations de table
Le tableau suivant indique les réponses du système pour les opérations DDL dans les tables.
| Fonctionnement DDL | Réponse du système Redshift |
|---|---|
CREATE TABLE |
Amazon Redshift crée le tableau. Certaines opérations entraînent l'échec de la création de tables, telles que la création d'une table sans clé primaire ou le partitionnement déclaratif. Pour plus d’informations, consultez Limites et Résolution des problèmes liés aux Aurora Zero-ETL. |
DROP TABLE |
Amazon Redshift abandonne la tendance. |
TRUNCATE TABLE |
Amazon Redshift tronque le tableau. |
ALTER TABLE
(RENAME...) |
Amazon Redshift renomme la table ou la colonne. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift supprime la table dans le schéma d'origine et resynchronise la table dans le nouveau schéma. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift ajoute une clé primaire et resynchronise le tableau. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift ajoute une colonne au tableau. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift supprime la colonne s'il ne s'agit pas d'une colonne de clé primaire. Dans le cas contraire, il resynchronise le tableau. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
Si vous remplacez la table par log, Amazon Redshift la resynchronise. Si vous définissez le tableau sur Unlogged, Amazon Redshift le supprime. |
