Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Index locaux secondaires
Certaines applications doivent uniquement interroger les données à l’aide de la clé primaire de la table de base. Cependant, il peut y avoir des situations où une clé de tri alternative serait utile. Pour donner à votre application un choix de clés de tri, vous pouvez créer un ou plusieurs index secondaires locaux sur une table Amazon DynamoDB, et émettre des demandes Query ou Scan par rapport à ces index.
Rubriques
Étape 6 : Utilisation d’un index secondaire local
À titre d’exemple, considérez la table Thread. Cette table est utile pour une application telle que les Forums de discussion AWS
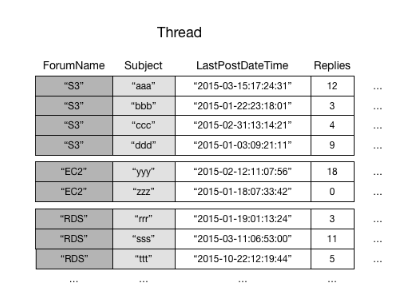
DynamoDB stocke tous les éléments ayant la même valeur de clé de partition de manière continue. Dans cet exemple, étant donné un ForumName particulier, une opération Query pourrait localiser immédiatement toutes les unités d’exécution pour ce forum. Dans un groupe d’éléments ayant la même valeur de clé de partition, les éléments sont triés par valeur de clé de tri. Si la clé de tri (Subject) est également fournie dans la requête, DynamoDB peut réduire les résultats renvoyés, par exemple, en renvoyant toutes les unités d’exécution du forum « S3 » qui ont un Subject commençant par la lettre « a ».
Certaines demandes peuvent nécessiter des modèles d’accès aux données plus complexes. Par exemple :
-
Quelles unités d’exécution de forum obtiennent le plus de vues et de réponses ?
-
Quelle unité d’exécution dans un forum particulier a le plus grand nombre de messages ?
-
Combien d’unités d’exécution ont été publiées dans un forum particulier au cours d’une période donnée ?
Pour répondre à ces questions, l’action Query ne serait pas suffisante. Au lieu de cela, vous devriez effectuer une opération Scan sur la table toute entière. Pour une table contenant des millions d’éléments, cette opération utiliserait une grande quantité de débit de lecture approvisionné et prendrait beaucoup de temps.
En revanche, vous pouvez spécifier un ou plusieurs index secondaires locaux sur des attributs autres que de clé, tels que Replies ou LastPostDateTime.
A index secondaire local gère une clé de tri alternative pour une valeur de clé de partition donnée. Un index secondaire local contient également une copie de tout ou partie des attributs de sa table de base. Vous spécifiez quels attributs sont projetés dans l’index secondaire local lorsque vous créez la table. Les données dans un index secondaire local sont organisées avec la même clé de partition que la table de base, mais une clé de tri différente. Cela vous permet d’accéder efficacement aux éléments de données dans cette dimension différente. Pour bénéficier d’une plus grande flexibilité de requête ou d’analyse, vous pouvez créer jusqu’à cinq index secondaires locaux par table.
Supposons qu’une application ait besoin de trouver toutes les discussions publiées au cours des trois derniers mois dans un forum particulier. A défaut d’index secondaire local, l’application devrait effectuer une opération Scan sur la table Thread toute entière, et écarter les publications ne d’inscrivant pas dans la période spécifiée. Avec un index secondaire local, une opération Query pourrait utiliser LastPostDateTime comme clé de tri et trouver les données rapidement.
Le diagramme suivant illustre un index secondaire local nommé LastPostIndex. Notez que la clé de partition est la même que celle de la table Thread, mais la clé de tri est LastPostDateTime.
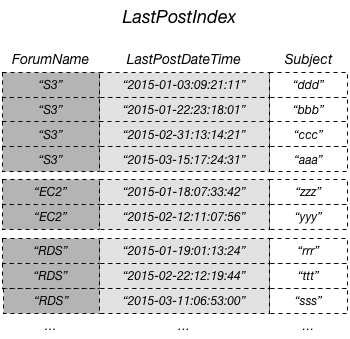
Chaque index secondaire local doit remplir les conditions suivantes :
-
La clé de partition est la même que celle de sa table de base.
-
La clé de tri se compose exactement d’un attribut scalaire.
-
La clé de tri de la table de base est projetée dans l’index, où elle agit comme un attribut autre que de clé.
Dans cet exemple, la clé de partition est ForumName et la clé de tri de l’index secondaire local est LastPostDateTime. En outre, la valeur de clé de tri de la table de base (dans cet exemple, Subject) est projetée dans l’index, mais ne fait pas partie de la clé d’index. Si une application a besoin d’une liste basée sur ForumName et LastPostDateTime, elle peut émettre une demande Query par rapport à LastPostIndex. Les résultats de la requête sont triés par LastPostDateTime, et peuvent être renvoyés dans un ordre croissant ou décroissant. La requête peut également appliquer des conditions de clé, telles que renvoyer uniquement les éléments qui ont une valeur LastPostDateTime s’inscrivant dans une période particulière.
Chaque index secondaire local contient automatiquement les clés de partition et de tri de sa table de base. Vous pouvez éventuellement projeter des attributs autres que de clé dans l’index. Lorsque vous interrogez l’index, DynamoDB peut extraire ces attributs projetés de façon efficace. Quand vous interrogez un index secondaire local, la requête peut également extraire des attributs qui ne sont pas projetés dans l’index. DynamoDB extrait automatiquement ces attributs de la table de base, mais moyennant une latence et des coûts de débit approvisionné plus élevés.
Pour tout index secondaire local, vous pouvez stocker jusqu’à 10 Go de données par valeur de clé de partition. Cette figure inclut tous les éléments de la table de base, ainsi que tous les éléments des index, qui ont la même valeur de clé de partition. Pour de plus amples informations, veuillez consulter Collections d’articles dans les index secondaires locaux.
Projections d’attribut
Avec LastPostIndex, une application pourrait utiliser ForumName et LastPostDateTime en tant que critères de requête. Toutefois, pour récupérer des attributs supplémentaires, DynamoDB doit effectuer des opérations de lecture supplémentaires par rapport à la table Thread. Ces lectures supplémentaires appelées extractions peuvent augmenter le volume total de débit approvisionné requis pour une requête.
Supposons que vous souhaitiez remplir une page Web avec une liste de tous les sujets de « S3 » et le nombre de réponses pour chaque fil, triés selon la dernière réponse en date/time commençant par la réponse la plus récente. Pour remplir cette liste, vous avez besoin des attributs suivants :
-
Subject -
Replies -
LastPostDateTime
La manière la plus efficace d’interroger ces données et d’éviter les opérations d’extraction serait de projeter l’attribut Replies de la table vers l’index secondaire local, comme illustré dans ce diagramme.
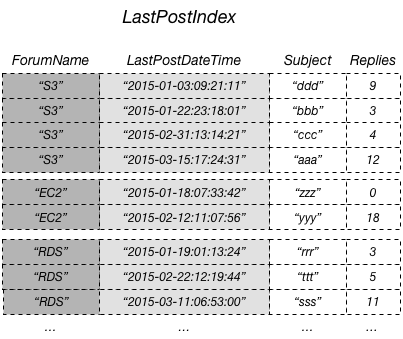
Une projection est l’ensemble d’attributs copié à partir d’une table dans un index secondaire. Les clés de partition et de tri de la table sont toujours projetées dans l’index. Vous pouvez projeter d’autres attributs en fonction des exigences de requête de votre application. Lorsque vous interrogez un index, Amazon DynamoDB peut accéder à n’importe quel attribut dans la projection, comme s’il se trouvait dans une table.
Lorsque vous créez un index secondaire, vous devez spécifier les attributs qui seront projetés dans celui-ci. Pour cela, DynamoDB propose trois options :
-
KEYS_ONLY – Chaque élément de l’index se compose uniquement des valeurs de clé de partition et de tri de la table, ainsi que des valeurs de clé d’index. L’option
KEYS_ONLYproduit l’index secondaire le plus petit possible. -
INCLUDE – En plus des attributs décrits dans
KEYS_ONLY, l’index secondaire inclut des attributs autres que de clé, que vous spécifiez. -
ALL – L’index secondaire inclut tous les attributs de la table source. Toutes les données de la table étant dupliquées dans l’index, une projection
ALLproduit l’index secondaire le plus grand possible.
Dans le diagramme précédent, l’attribut autre que de clé Replies est projeté dans LastPostIndex. Une application peut interroger LastPostIndex au lieu de la table Thread toute entière pour remplir une page avec des sujets (Subject), réponses (Replies) et horodatages de dernière publication LastPostDateTime. Si d’autres attributs autres que de clé sont demandés, DynamoDB doit les extraire de la table Thread.
Du point de vue d’une application, l’extraction d’attributs supplémentaires à partir de la table de base est automatique et transparente. Il n’est donc pas nécessaire de réécrire une logique d’application. Cependant, une telle récupération peut réduire considérablement l’avantage en termes de performances de l’utilisation d’un index secondaire local.
Lorsque vous choisissez les attributs à projeter sur un index secondaire local, vous devez prendre en compte le compromis entre les coûts de débit approvisionné et les coûts de stockage :
-
Si vous n’avez besoin d’accéder qu’à quelques attributs avec la plus faible latence possible, envisagez de projeter ces seuls attributs dans un index secondaire local. Plus l’index est petit, moins les coûts d’écriture et de stockage sont élevés. S’il existe des attributs que vous devez extraire occasionnellement, le coût du débit approvisionné risque d’être supérieur au coût à plus long terme du stockage de ces attributs.
-
Si votre application accède fréquemment à certains attributs autres que de clé, vous devez envisager de projeter ces attributs dans un index secondaire local. Les coûts de stockage supplémentaires de l’index secondaire local compensent le coût d’exécution d’analyses de table fréquentes.
-
Si vous avez besoin d’accéder fréquemment à la plupart des attributs autres que de clé, vous pouvez projeter ceux-ci (voire la table de base toute entière) dans un index secondaire local. Vous bénéficiez ainsi d’une flexibilité maximale et d’une consommation de débit approvisionné minimale, car aucune extraction n’est requise. Cependant, vos coûts de stockage augmentent, voire doublent, si vous projetez tous les attributs.
-
Si votre application doit interroger une table peu fréquemment, mais doit effectuer un grand nombre d’écritures ou de mises à jour de données dans la table, pensez à projeter KEYS_ONLY. L’index secondaire local sera d’une taille minimum, mais continuera d’être disponible chaque fois que ce sera nécessaire pour une activité de requête.
Création d’un index secondaire local
Pour créer un ou plusieurs index secondaires locaux sur une table, utilisez le paramètre LocalSecondaryIndexes de l’opération CreateTable. Des index secondaires locaux sur une table sont créés lors de la création de celle-ci. Lorsque vous supprimez une table, tous les index secondaires globaux sur celle-ci sont également supprimés.
Vous devez spécifier un attribut autre que de clé pour agir en tant que clé de tri de l’index secondaire local. L’attribut que vous choisissez doit être un scalaire String, Number ou Binary. Les autres types scalaires, types de document et types d’ensemble ne sont pas autorisés. Pour obtenir la liste complète des types de données, consultez Types de données.
Important
Pour les tables avec des index secondaires locaux, il existe une limite de taille de 10 Go par valeur de clé de partition. Une table avec des index secondaires locaux peut stocker n’importe quel nombre d’éléments, à condition qu’aucune valeur de clé de partition n’ait une taille supérieure à 10 Go. Pour de plus amples informations, veuillez consulter Taille limite de collection d’éléments.
Vous pouvez projeter des attributs de tout type de données dans un index secondaire local. Celui-ci inclut des scalaires, des documents et des ensembles. Pour obtenir la liste complète des types de données, consultez Types de données.
Lecture de données à partir d’un index secondaire local
Vous pouvez extraire des éléments d’un index secondaire local à l’aide des opérations Query et Scan. Vous ne pouvez pas utiliser les opérations GetItem et BatchGetItem sur un index secondaire local.
Interrogation d’un index secondaire local
Dans une table DynamoDB, les valeurs combinées des clés de partition et de tri pour chaque élément doivent être uniques. Cependant, dans un index secondaire local, la valeur de clé de tri n’a pas besoin d’être unique pour une valeur de clé de partition donnée. Si plusieurs éléments dans l’index secondaire local ont la même valeur de clé de tri, une opération Query renvoie tous les éléments ayant la même valeur de clé de partition. Dans la réponse, les éléments correspondants ne sont pas renvoyés dans un ordre particulier.
Vous pouvez interroger un index secondaire local en utilisant des lectures éventuellement ou fortement cohérentes. Pour spécifier le type de cohérence que vous souhaitez, utilisez le paramètre ConsistentRead de l’opération Query. Une lecture fortement cohérente d’un index secondaire local renvoie toujours les dernières valeurs mises à jour. Si la requête doit extraire des attributs supplémentaires de la table de base, ces attributs sont cohérents par rapport à l’index.
Exemple
Considérez les données suivantes renvoyées par une opération Query qui demande des données des unités d’exécution de discussion dans un forum particulier.
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
Dans cette requête :
-
DynamoDB accède à
LastPostIndexen utilisant la clé de partitionForumNameafin de localiser les éléments d’index pour « EC2 ». Tous les éléments d’index avec cette clé sont stockés les uns à côté des autres pour une récupération rapide. -
Dans ce forum, DynamoDB utilise l’index pour rechercher les clés correspondant à la condition
LastPostDateTimespécifiée. -
L’attribut
Repliesétant projeté dans l’index, DynamoDB peut extraire cet attribut sans utiliser de débit approvisionné supplémentaire. -
L’attribut
Tagsn’étant pas projeté dans l’index, DynamoDB doit accéder à la tableThreadpour l’en extraire. -
Les résultats sont renvoyés, triés par
LastPostDateTime. Les entrées d’index sont triées par valeur de clé de partition, puis par valeur de clé de tri, etQueryles renvoie dans l’ordre de leur stockage (vous pouvez utiliser le paramètreScanIndexForwardpour renvoyer les résultats dans l’ordre décroissant).
L’attribut Tags n’étant pas projeté dans l’index secondaire local, DynamoDB doit utiliser des unités de capacité de lecture supplémentaires pour l’extraire de la table de base. Si vous devez exécuter cette requête souvent, nous vous recommandons de projeter Tags dans LastPostIndex pour éviter une extraction à partir de la table de base. Toutefois, si vous n’avez besoin d’accéder à Tags qu’occasionnellement, il se peut que le coût de stockage supplémentaire lié à la projection de Tags dans l’index n’en vaille pas la peine.
Analyse d’un index secondaire local
Vous pouvez utiliser l’opération Scan pour extraire toutes les données d’un index secondaire local. Vous devez fournir le nom de la table de base et le nom de l’index dans la demande. Avec une opération Scan, DynamoDB lit toutes les données de l’index et les renvoie à l’application. Vous pouvez également demander que seules quelques données soient retournées, et que les données restantes soient ignorées. Pour ce faire, utilisez le paramètre FilterExpression de l’API Scan. Pour de plus amples informations, veuillez consulter Filtrer les expressions à des fins d’analyse.
Écritures d’élément et index secondaires locaux
DynamoDB conserve automatiquement tous les index secondaires locaux synchronisés avec leurs tables de base respectives. Les applications n’écrivent jamais directement sur un index. Cependant, il est important de comprendre les implications de la façon dont DynamoDB gère ces index.
Lorsque vous créez un index secondaire local, vous spécifiez un attribut qui servira de clé de tri pour l’index. Vous spécifiez également un type de données pour cet attribut. Cela signifie que, chaque fois que vous écrivez un élément dans la table de base, si l’élément définit un attribut de clé d’index, son type doit correspondre au type de données du schéma de clé d’index. Dans le cas de LastPostIndex, la clé de tri LastPostDateTime dans l’index est définie comme un type de données String. Si vous essayez d’ajouter un élément à la table Thread et spécifiez un type de données différent pour LastPostDateTime (par exemple, Number), DynamoDB renvoie une ValidationException en raison de la discordance des types de données.
Il n'est pas nécessaire d' one-to-oneétablir une relation entre les éléments d'une table de base et ceux d'un index secondaire local. En fait, ce comportement peut être avantageux pour de nombreuses applications.
Une table avec de nombreux index secondaires locaux s’expose à des coûts plus élevés pour l’activité d’écriture qu’une table ayant moins d’index. Pour de plus amples informations, veuillez consulter Considérations relatives au débit alloué pour les index secondaires locaux.
Important
Pour les tables avec des index secondaires locaux, il existe une limite de taille de 10 Go par valeur de clé de partition. Une table avec des index secondaires locaux peut stocker n’importe quel nombre d’éléments, à condition qu’aucune valeur de clé de partition n’ait une taille supérieure à 10 Go. Pour de plus amples informations, veuillez consulter Taille limite de collection d’éléments.
Considérations relatives au débit alloué pour les index secondaires locaux
Lorsque vous créez une table dans DynamoDB, vous approvisionnez des unités de capacité de lecture et d’écriture pour la charge de travail prévue de la table. Cette charge de travail inclut l’activité de lecture et d’écriture sur les index secondaires locaux de la table.
Pour voir les prix actuels de capacité de débit approvisionnée, consultez Tarification Amazon DynamoDB
Unités de capacité de lecture
Lorsque vous interrogez un index secondaire local, le nombre d’unités de capacité de lecture consommées dépend du mode d’accès aux données.
Comme une interrogation de table, une interrogation d’index peut utiliser des lectures éventuellement ou fortement cohérentes en fonction de la valeur de ConsistentRead. Une lecture fortement cohérente utilise une unité de capacité de lecture ; une lecture éventuellement cohérente n’en utilise que la moitié. Ainsi, en choisissant des lectures éventuellement cohérentes, vous pouvez réduire vos coûts d’unités de capacité de lecture.
Pour les interrogations d’index qui demandent uniquement des clés d’index et des attributs projetés, DynamoDB calcule l’activité de lecture approvisionnée de la même façon que pour des requêtes sur des tables. La seule différence est que le calcul est basé sur les tailles des entrées d’index, plutôt que sur la taille de l’élément de la table de base. Le nombre d’unités de capacité de lecture est la somme des tailles de tous les attributs projetés de tous les éléments renvoyés. Le résultat est ensuite arrondi à la limite de 4 Ko suivante. Pour plus d’informations sur la façon dont DynamoDB calcule l’utilisation du débit approvisionné, consultez Mode de capacité provisionnée DynamoDB.
Pour les interrogations d’index qui lisent des attributs qui ne sont pas projetés dans l’index secondaire local, DynamoDB doit extraire ces attributs de la table de base, en plus de lire les attributs projetés à partir de l’index. Ces extractions se produisent lorsque vous incluez des attributs non projetés dans les paramètres Select ou ProjectionExpression de l’opération Query. L’extraction entraîne une latence supplémentaire des réponses aux requêtes, ainsi qu’un surcoût de débit approvisionné. En plus des lectures de l’index secondaire local décrites précédemment, vous êtes facturé pour les unités de capacité de lecture utilisées pour extraire chaque élément de la table de base. Ces frais ont trait à la lecture de chaque élément entier de la table, pas seulement des attributs demandés.
La taille maximum des résultats renvoyés par une opération Query est de 1 Mo. Cela inclut les tailles de tous les noms et valeurs d’attribut à travers l’ensemble des éléments retournés. Toutefois, si une requête sur un index secondaire local amène DynamoDB à extraire des attributs d’élément de la table de base, la taille maximum des données dans les résultats peut être inférieure. Dans ce cas, la taille du résultat est la somme de :
-
La taille des éléments correspondants dans l’index, arrondie à la limite de 4 Ko suivante.
-
La taille de chaque élément correspondant dans la table de base, chaque élément étant arrondi individuellement à la limite de 4 Ko suivante.
Avec cette formule, la taille maximum des résultats renvoyés par une opération Query est toujours de 1 Mo.
Par exemple, considérons une table où la taille de chaque élément est de 300 octets. Il existe un index secondaire local sur cette table, mais seuls 200 octets de chaque élément sont projetés dans l’index. Supposons à présent que vous effectuez une opération Query sur cet index, que la requête nécessite une extraction de table pour chaque élément, et que la requête renvoie 4 éléments. DynamoDB additionne les valeurs suivantes :
-
La taille des éléments correspondants dans l’index : 200 octets × 4 éléments = 800 octets, valeur ensuite arrondie à 4 Ko.
-
La taille de chaque élément correspondant dans la table de base : (300 octets, arrondis à 4 Ko) × 4 éléments = 16 Ko.
La taille totale des données dans le résultat est donc de 20 Ko.
Unités de capacité d’écriture
Quand un élément d’une table est ajouté, mis à jour ou supprimé, la mise à jour des index secondaires locaux utilise des unités de capacité d’écriture approvisionnée pour la table. Le coût total du débit alloué pour une écriture est la somme des unités de capacité d’écriture consommées par l’écriture dans la table de base, et de celles consommées par la mise à jour des index secondaires locaux.
Le coût d’écriture d’un élément dans un index secondaire local dépend de plusieurs facteurs :
-
Si vous écrivez un nouvel élément sur la table qui définit un attribut indexé, ou que vous mettez à jour un élément existant pour définir un attribut indexé précédemment non défini, une opération d’écriture est nécessaire pour insérer l’élément dans l’index.
-
Si une mise à jour de la table change la valeur d’un attribut de clé indexé (de A en B), deux écritures sont requises, une pour supprimer l’élément précédent de l’index et une autre pour insérer le nouvel élément dans l’index.
-
Si un élément était présent dans l’index, mais qu’une écriture sur la table a entraîné la suppression de l’attribut indexé, une écriture est nécessaire pour supprimer de l’index la projection de l’ancien élément.
-
Si un élément n’est pas présent dans l’index avant ou après la mise à jour de l’élément, il n’y a aucun coût d’écriture supplémentaire pour l’index.
Tous ces facteurs partent du principe que la taille de chaque élément dans l’index est inférieure ou égale à la taille d’élément de 1 Ko pour le calcul des unités de capacité d’écriture. Les plus grandes entrées d’index nécessitent des unités de capacité en écriture supplémentaires. Vous pouvez réduire vos coûts d’écriture en considérant les attributs que vos requêtes ont besoin de renvoyer et en projetant uniquement ces attributs dans l’index.
Considérations relatives au stockage pour les index secondaires locaux
Quand une application écrit un élément dans une table, DynamoDB copie automatiquement le sous-ensemble approprié d’attributs vers les index secondaires locaux où ces attributs doivent apparaître. Votre AWS compte est débité pour le stockage de l'article dans la table de base ainsi que pour le stockage des attributs dans les index secondaires locaux de cette table.
La quantité d’espace utilisée par un élément de l’index est la somme des éléments suivants :
-
La taille en octets de la clé primaire de la table de base (clé de partition et clé de tri)
-
La taille en octets de l’attribut de clé d’index
-
La taille en octets des attributs projetés (le cas échéant)
-
100 octets de surcharge par élément d’index
Pour estimer les besoins en stockage d’un index secondaire local, vous pouvez estimer la taille moyenne d’un élément de l’index, puis multiplier cette valeur par le nombre d’éléments présents dans l’index.
Si une table contient un élément dans lequel un attribut particulier n’est pas défini, tandis que cet attribut est défini en tant que clé de tri d’index, DynamoDB n’écrit aucune donnée pour cet élément dans l’index.
Collections d’articles dans les index secondaires locaux
Note
Cette section concerne uniquement les tables qui ont des index secondaires locaux.
Dans DynamoDB, une collection d’éléments est un groupe quelconque d’éléments ayant la même valeur de clé de partition dans une table, ainsi que de tous leurs index secondaires locaux. Dans les exemples utilisés tout au long de cette section, la clé de partition pour la table Thread est ForumName, et la clé de partition pour LastPostIndex est également ForumName. Tous les éléments de table et d’index ayant le même ForumName font partie de la même collection d’éléments. Par exemple, la table Thread et l’index secondaire local LastPostIndex contiennent une collection d’éléments pour le forum EC2, et une autre pour le forum RDS.
Le diagramme suivant illustre la collection d’éléments pour le forum S3.
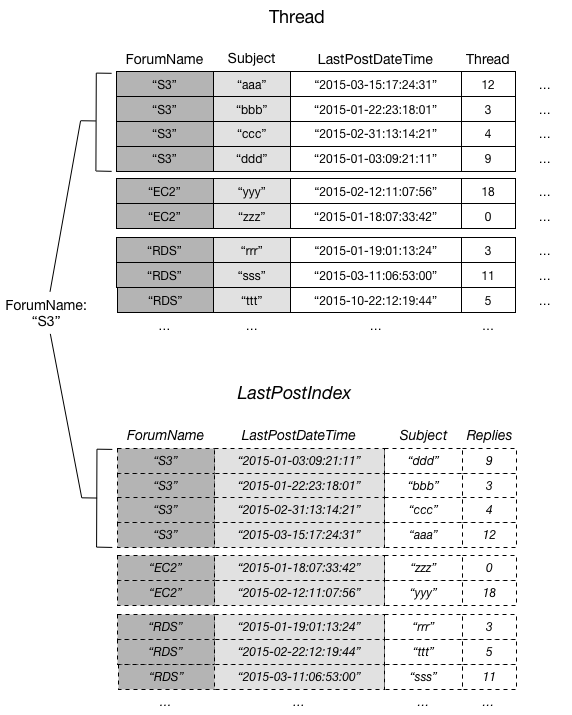
Dans ce diagramme, la collection d’éléments se compose de tous les éléments figurant dans Thread et LastPostIndex, où la valeur de clé de partition ForumName est « S3 ». S’il y avait d’autres index secondaires locaux sur la table, tous les éléments dans ces index dont la valeur de ForumName est « S3 » feraient également partie de la collection d’éléments.
Vous pouvez utiliser n’importe laquelle des opérations suivantes dans DynamoDB pour renvoyer des informations sur les collections d’éléments :
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
Chacune de ces opérations prend en charge le paramètre ReturnItemCollectionMetrics. Lorsque vous définissez ce paramètre sur SIZE, vous pouvez afficher des informations sur la taille de chaque collection d’éléments dans l’index.
Exemple
Voici un exemple de sortie d’une opération UpdateItem sur la table Thread, avec la valeur ReturnItemCollectionMetrics définie sur SIZE. L’élément mis à jour avait une valeur ForumName de « EC2 », de sorte que la sortie inclut des informations sur cette collection d’éléments.
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
L’objet SizeEstimateRangeGB montre que la taille de cette collection d’éléments est comprise entre 0 et 1 Go. DynamoDB mettant régulièrement à jour cette estimation de taille, les nombres pourraient être différents lors de la prochaine modification de l’élément.
Taille limite de collection d’éléments
La taille maximale de toute collection d’éléments pour une table possédant un ou plusieurs index secondaires locaux est de 10 Go. Cela ne s’applique pas aux collections d’éléments des tables sans index secondaires locaux, ni aux collections d’éléments dans des index secondaires globaux. Seules les tables ayant un ou plusieurs index secondaires locaux sont concernées.
Si une collection d'articles dépasse la limite de 10 Go, DynamoDB peut renvoyer ItemCollectionSizeLimitExceededException un, et vous ne pourrez peut-être pas ajouter d'autres articles à la collection d'articles ou augmenter la taille des éléments qui se trouvent dans la collection d'articles. (les opérations de lecture et d’écriture qui réduisent la taille de la collection d’éléments restent autorisées). Vous pouvez toujours ajouter des éléments à d’autres collections d’éléments.
Pour réduire la taille d’une collection d’éléments, vous pouvez effectuer l’une des opérations suivantes :
-
Supprimer tous les éléments inutiles avec la valeur de clé de partition en question. Lorsque vous supprimez ces éléments de la table de base, DynamoDB supprime également toutes les entrées d’index ayant la même valeur de clé de partition.
-
Mettre à jour les éléments en supprimant des attributs ou en réduisant la taille des attributs. Si ces attributs sont projetés dans des index secondaires locaux, DynamoDB réduit également la taille des entrées d’index correspondantes.
-
Créer une table avec les mêmes clés de partition et de tri, puis déplacer les éléments de l’ancienne table vers la nouvelle. Cela peut être une bonne approche si une table contient des données historiques rarement utilisées. Vous pouvez également envisager d’archiver ces données historiques sur Amazon Simple Storage Service (Amazon S3).
Lorsque la taille totale de la collection d’éléments passe sous le seuil de 10 Go, vous pouvez à nouveau ajouter des éléments avec la même valeur de clé de partition.
En guise de bonne pratique, nous vous recommandons d’instrumenter votre application pour contrôler les tailles de vos collections d’éléments. Une façon de le faire consiste à définir le paramètre ReturnItemCollectionMetrics sur SIZE chaque fois que vous utilisez BatchWriteItem, DeleteItem, PutItem ou UpdateItem. Votre application doit examiner l’objet ReturnItemCollectionMetrics dans la sortie et journaliser un message d’erreur chaque fois qu’une collection d’éléments dépasse une limite de taille définie par l’utilisateur (par exemple, 8 Go). Définir une limite inférieure à 10 Go fournirait un système d’avertissement précoce qui vous permettrait de savoir qu’une collection d’éléments approche de la limite dans le temps pour faire quelque chose à ce sujet.
Collections et partitions d’éléments
Dans une table avec un ou plusieurs index secondaires locaux, chaque collection d’éléments est stockée dans une partition. La taille totale d’une collection d’éléments de ce type est limitée à la capacité de cette partition, soit 10 Go. Pour une application dans laquelle le modèle de données inclut des collections d’éléments de taille illimitée, ou dans laquelle vous pouvez raisonnablement vous attendre à ce que certaines collections d’éléments dépassent 10 Go à l’avenir, envisagez plutôt d’utiliser un index secondaire global.
Vous devez concevoir vos applications de sorte que les données de table soient réparties uniformément entre des valeurs de clé de partition distinctes. Pour les tables avec des index secondaires locaux, vos applications ne doivent pas créer de « points chauds » d’activité de lecture et d’écriture au sein d’une seule collection d’éléments sur une seule partition.
