Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques pour l'interrogation et l'analyse de données
Cette section présente certaines bonnes pratiques d'utilisation d'opérations Query et Scan dans Amazon DynamoDB.
Considérations relatives aux performances pour les analyses
D'une manière générale, les opérations Scan sont moins efficaces que d'autres opérations dans DynamoDB. Une opération Scan analyse toujours la table entière ou un index secondaire. Elle filtre ensuite les valeurs pour fournir le résultat souhaité, essentiellement en ajoutant l'étape supplémentaire de suppression des données de l'ensemble de résultats.
Si possible, il est recommandé d'éviter d'utiliser une opération Scan sur une table ou un index volumineux avec un filtre qui supprime de nombreux résultats. En outre, à mesure qu'une table ou un index augmente, l'opération Scan ralentit. L'opération Scan examine chaque élément en lien avec les valeurs demandées, et peut utiliser le débit approvisionné pour une table ou un index volumineux en une seule opération. Pour des temps de réponse plus rapides, concevez vos tables et index de façon que vos applications puissent utiliser Query au lieu de Scan. (Pour les tables, vous pouvez également envisager d'utiliser les API GetItem et BatchGetItem.)
Vous pouvez également concevoir votre application pour qu'elle utilise les opérations Scan de manière à minimiser l'impact sur votre débit de demandes. Cela peut inclure la modélisation lorsqu'il peut être plus efficace d'utiliser un index secondaire global plutôt qu'une opération Scan. Vous trouverez plus d'informations sur ce processus dans la vidéo suivante.
Contournement les pics soudains dans l'activité de lecture
Lorsque vous créez une table, vous définissez ses exigences en termes d'unités de capacité de lecture et d'écriture. Pour les lectures, les unités de capacité sont exprimées en nombre de demandes de lecture de données de 4 Ko fortement cohérentes par seconde. Pour des lectures éventuellement cohérentes, une unité de capacité de lecture correspond à deux demandes de lecture de 4 Ko par seconde. Une opération Scan effectue des lectures éventuellement cohérentes par défaut, et peut renvoyer jusqu'à 1 Mo (une page) de données. Par conséquent, une seule demande Scan peut consommer (1 Mo de taille de page / 4 Ko de taille d'élément) / 2 (lectures éventuellement cohérentes) = 128 opérations de lecture. Si vous demandez des lectures fortement cohérentes à la place, l'opération Scan consomme deux fois plus de débit approvisionné, soit 256 opérations de lecture.
Cela représente un pic soudain d'utilisation par rapport à la capacité de lecture configurée pour la table. Cette utilisation des unités de capacité par une analyse empêche d'autres demandes potentiellement plus importantes pour la même table d'utiliser les unités de capacité disponibles. Par conséquent, il est probable que vous obteniez une exception ProvisionedThroughputExceeded pour ces demandes.
Le problème n'est pas seulement l'augmentation soudaine des unités de capacité que l'opération Scan utilise. Il est également probable que l'analyse consomme toutes les unités de capacité de la même partition, car elle demande la lecture d'éléments qui se jouxtent sur la partition. Cela signifie que la demande touche la même partition, entraînant la consommation de toutes ses unités de capacité et la limitation des autres demandes adressées à cette partition. Si la demande de lecture des données est répartie sur plusieurs partitions, l'opération n'a pas pour effet de limiter une partition spécifique.
Le diagramme suivant illustre l'impact d'un pic soudain d'utilisation d'unités de capacité par des opérations Query et Scan, et son incidence sur vos autres demandes par rapport à la même table.
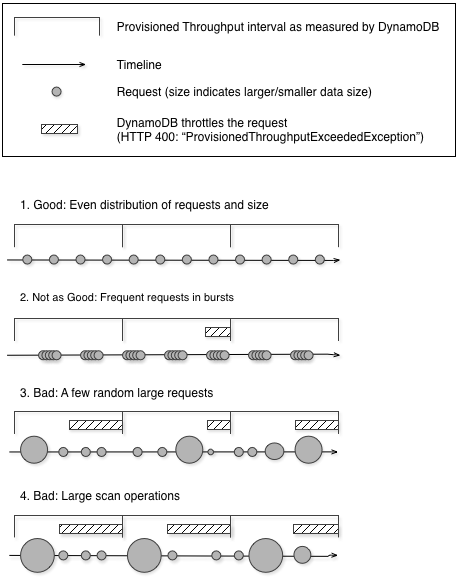
Comme illustré ici, le pic d'utilisation peut avoir un impact sur le débit approvisionné de la table de plusieurs façons :
-
Bon : répartition uniforme des demandes et de la taille
-
Pas très bon : demandes fréquentes en rafales
-
Mauvais : quelques demandes de grande taille aléatoires
-
Mauvais : opérations d'analyse de grande taille
Au lieu d'utiliser une opération Scan de grande taille, vous pouvez utiliser les techniques suivantes pour réduire l'impact d'une analyse sur le débit approvisionné d'une table.
-
Réduire la taille de page
Étant donné qu'une opération d'analyse lit une page entière (par défaut, 1 Mo), vous pouvez réduire l'impact de l'opération de numérisation en définissant une taille de page plus petite. L'opération
Scanfournit un paramètre, Limit, que vous pouvez utiliser pour définir la taille de page pour votre demande. Chaque demandeQueryouScanportant sur une taille de page plus petite utilise moins d'opérations de lecture et ménage une « pause » entre chaque demande. Par exemple, supposons que chaque élément a une taille de 4 Ko et que vous définissez la taille de page sur 40 éléments. Une demandeQueryne consomme alors que 20 opérations de lecture éventuellement cohérente ou 40 opérations de lecture fortement cohérente. Un plus grand nombre d'opérationsQueryouScande plus petite taille permettrait à vos autres demandes critiques d'aboutir sans limitation. -
Isoler les opérations d'analyse
DynamoDB est conçu pour faciliter le mise à l'échelle. Par conséquent, une application peut créer des tables à des fins distinctes, voire dupliquer du contenu sur plusieurs tables. Vous souhaitez effectuer des analyses sur une table qui ne prend pas de trafic « stratégique ». Certaines applications gèrent cette charge en opérant une rotation horaire du trafic entre deux tables, l'une pour le trafic critique, et l'autre pour la comptabilisation. D'autres applications peuvent faire cela en effectuant chaque écriture sur deux tables : une table « stratégique » et une table « alternative ».
Configurez votre application pour qu'elle relance toute demande recevant un code de réponse indiquant que vous avez dépassé votre débit approvisionné. Ou augmentez le débit approvisionné pour votre table à l'aide de l'opération UpdateTable. Si votre charge de travail comporte des pics temporaires qui ont pour effet que votre débit dépasse parfois le niveau approvisionné, relancez la demande avec un backoff exponentiel. Pour plus d'informations sur l'implémentation d'un backoff exponentiel, consultez Nouvelles tentatives après erreur et backoff exponentiel.
Tirer parti des analyses parallèles
De nombreuses applications peuvent bénéficier de l'utilisation d'opérations Scan parallèles au lieu d'analyses séquentielles. Par exemple, une application qui traite une table de données historiques de grande taille peut effectuer une analyse parallèle beaucoup plus rapidement qu'une application séquentielle. Plusieurs unités d’exécution de travail dans un processus de « balayage » en arrière-plan pourraient analyser une table à un faible niveau de priorité sans que cela affecte le trafic de production. Dans chacun de ces exemples, une opération Scan parallèle est utilisée de façon à ne pas priver d'autres applications de ressources de débit approvisionné.
Bien que des analyses parallèles puissent être bénéfiques, elles peuvent imposer une forte demande sur le débit approvisionné. Avec une analyse parallèle, votre application dispose de plusieurs unités d’exécution de travail qui exécutent tous des opérations Scan simultanément. Cela peut rapidement consommer toute la capacité de lecture approvisionnée de votre table. Dans ce cas, d'autres applications qui doivent accéder à la table risquent d'être limitées.
Une analyse parallèle peut être le bon choix si les conditions suivantes sont réunies :
La taille de la table est de 20 Go ou plus.
Le débit de lecture approvisionné de la table n'est pas entièrement utilisé.
Les opérations
Scanséquentielles sont trop lentes.
Choisir TotalSegments
Le paramétrage optimal pour TotalSegments dépend de vos données spécifiques, des paramètres de débit approvisionné de la table et de vos exigences en matière de performances. Il se peut que vous deviez expérimenter différents paramétrages pour trouver le bon. Nous vous recommandons de commencer par un ratio simple, tel qu'un segment par 2 Go de données. Par exemple, pour une table de 30 Go, vous pouvez définir TotalSegments sur 15 (30 Go / 2 Go). Votre application utiliserait alors 15 unités d’exécution de travail, chacun analysant un segment différent.
Vous pouvez également choisir pour TotalSegments une valeur basée sur les ressources du client. Vous pouvez définir TotalSegments sur n'importe quelle valeur de 1 à 1 000 000, et DynamoDB vous permet d'analyser ce nombre de segments. Par exemple, si votre client limite le nombre d’unités d’exécution pouvant s'exécuter simultanément, vous pouvez augmenter TotalSegments progressivement jusqu'à obtenir des performances de Scan optimales avec votre application.
Surveillez vos analyses parallèles pour optimiser votre utilisation du débit approvisionné, tout en vous veillant à ce que vos autres applications ne sont pas privées de ressources. Augmentez la valeur de TotalSegments si vous ne consommez pas tout votre débit approvisionné mais rencontrez toujours une limitation de vos demandes Scan. Réduisez la valeur de TotalSegments si les demandes Scan consomment plus de débit approvisionné que souhaité.
