Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques de gestion des données de séries temporelles dans DynamoDB
Les principes de conception généraux dans Amazon DynamoDB recommandent d'utiliser un nombre minimum de tables. Pour la plupart des applications, une seule table est suffisante. Cependant, pour les données chronologiques, il sera souvent préférable d'utiliser une table par application et par période.
Modèle de création des données de séries temporelles
Prenons l'exemple d'un scénario classique avec des données chronologiques, dans lequel vous voulez suivre un grand nombre d'événements. Votre modèle d'accès en écriture se résume au fait que tous les événements enregistrés ont la date du jour. Votre modèle d'accès en lecture se résume comme suit : la lecture des événements du jour est la lecture effectuée le plus fréquemment, la lecture des événements d'hier étant effectuée un peu moins fréquemment et celle des événements des jours suivants étant effectuée très rarement. Un moyen de le faire est d'intégrer la date et l'heure actuelles dans la clé primaire.
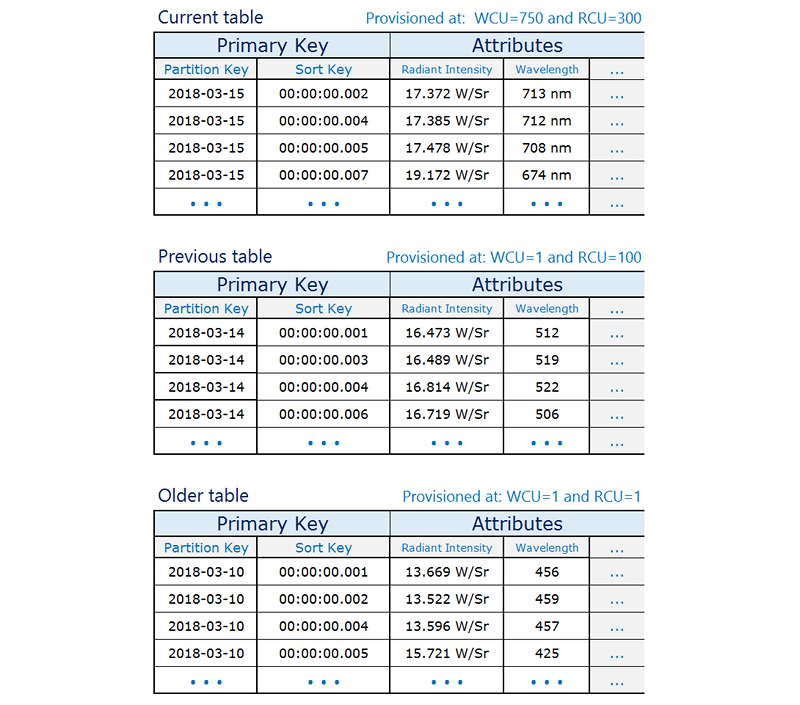
Le modèle de création suivant permet souvent de gérer de façon efficace ce scénario :
-
Créez une table par période, à laquelle vous allouez la capacité en lecture et écriture requise et les index nécessaires.
-
Avant la fin de chaque période, générez à l'avance la table pour la période suivante. Lorsque la période en cours se termine, dirigez le trafic d'événements vers la nouvelle table. Vous pouvez affecter à ces tables des noms indiquant les périodes auxquelles elles sont associées.
-
Dès qu'une table ne fait plus l'objet d'écritures, réduisez sa capacité en écriture allouée (par exemple 1 WCU) et allouez la capacité en lecture appropriée. Réduisez la capacité en lecture allouée aux tables plus anciennes à mesure qu'elles vieillissent. Vous pouvez choisir d'archiver ou de supprimer les tables dont le contenu est rarement ou jamais nécessaire.
L'idée est d'allouer les ressources nécessaires pour la période en cours, qui présente le plus haut volume de trafic, et de réduire la capacité allouée aux anciennes tables, qui ne sont pas utilisées activement, de manière à économiser de l'argent. En fonction des besoins de votre entreprise, vous devrez peut-être envisager d'écrire le partitionnement de manière à répartir le trafic uniformément selon la clé de partition logique. Pour de plus amples informations, veuillez consulter Utilisation du partitionnement d'écriture pour répartir les charges de travail de manière uniforme dans votre table DynamoDB.
Exemples de tableaux de séries chronologiques
Voici un exemple de série chronologique dans lequel la table actuelle est provisionnée à une read/write capacité supérieure et les anciennes tables sont réduites car elles sont rarement consultées.