Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolveurs
Dans les sections précédentes, vous avez découvert les composants du schéma et de la source de données. Nous devons maintenant examiner la manière dont le schéma et les sources de données interagissent. Tout commence par le résolveur.
Un résolveur est une unité de code qui gère la manière dont les données de ce champ seront résolues lorsqu'une demande est envoyée au service. Les résolveurs sont attachés à des champs spécifiques au sein de vos types dans votre schéma. Ils sont le plus souvent utilisés pour implémenter les opérations de changement d'état pour vos opérations de terrain de requête, de mutation et d'abonnement. Le résolveur traitera la demande d'un client, puis renverra le résultat, qui peut être un groupe de types de sortie tels que des objets ou des scalaires :

Temps d'exécution du résolveur
Dans AWS AppSync, vous devez d'abord spécifier un environnement d'exécution pour votre résolveur. Un environnement d'exécution d'un résolveur indique l'environnement dans lequel un résolveur est exécuté. Il dicte également la langue dans laquelle vos résolveurs seront écrits. AWS AppSync supporte actuellement APPSYNC_JS pour JavaScript et Velocity Template Language (VTL). Consultez les fonctionnalités JavaScript d'exécution pour les résolveurs et les fonctions JavaScript ou la référence de l'utilitaire de modèle de mappage Resolver pour VTL.
Structure du résolveur
Du point de vue du code, les résolveurs peuvent être structurés de plusieurs manières. Il existe des résolveurs d'unités et de pipelines.
Résolveurs d'unités
Un résolveur d'unités est composé d'un code qui définit un seul gestionnaire de demandes et de réponses exécuté sur une source de données. Le gestionnaire de demandes prend un objet de contexte comme argument et renvoie la charge utile de la demande utilisée pour appeler votre source de données. Le gestionnaire de réponses reçoit une charge utile en retour de la source de données avec le résultat de la demande exécutée. Le gestionnaire de réponse transforme la charge utile en réponse GraphQL pour résoudre le champ GraphQL.

Résolveurs de pipelines
Lors de la mise en œuvre de résolveurs de pipeline, ils suivent une structure générale :
-
Avant l'étape : lorsqu'une demande est faite par le client, les données de la demande sont transmises aux résolveurs des champs de schéma utilisés (généralement vos requêtes, mutations, abonnements). Le résolveur commencera à traiter les données de la demande à l'aide d'un gestionnaire avant étape, qui permet d'effectuer certaines opérations de prétraitement avant que les données ne passent par le résolveur.
-
Fonction (s) : Une fois l'étape précédente exécutée, la demande est transmise à la liste des fonctions. La première fonction de la liste s'exécutera sur la source de données. Une fonction est un sous-ensemble du code de votre résolveur contenant son propre gestionnaire de requêtes et de réponses. Un gestionnaire de demandes prendra les données de la demande et effectuera des opérations sur la source de données. Le gestionnaire de réponses traitera la réponse de la source de données avant de la renvoyer à la liste. S'il existe plusieurs fonctions, les données de la demande seront envoyées à la fonction suivante de la liste à exécuter. Les fonctions de la liste seront exécutées en série dans l'ordre défini par le développeur. Une fois que toutes les fonctions ont été exécutées, le résultat final est transmis à l'étape suivante.
-
Étape suivante : L'étape suivante est une fonction de gestion qui vous permet d'effectuer certaines opérations finales sur la réponse de la fonction finale avant de la transmettre à la réponse GraphQL.

Structure du gestionnaire du résolveur
Les gestionnaires sont généralement des fonctions appelées Request et Response :
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
Dans un résolveur d'unités, il n'y aura qu'un seul ensemble de ces fonctions. Dans un résolveur de pipeline, il y en aura un ensemble pour les étapes avant et après et un ensemble supplémentaire par fonction. Pour visualiser à quoi cela pourrait ressembler, examinons un Query type simple :
type Query { helloWorld: String! }
Il s'agit d'une requête simple avec un champ appelé helloWorld typeString. Supposons que nous voulions toujours que ce champ renvoie la chaîne « Hello World ». Pour implémenter ce comportement, nous devons ajouter le résolveur dans ce champ. Dans un résolveur d'unités, nous pourrions ajouter quelque chose comme ceci :
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
requestVous pouvez simplement laisser ce champ vide car nous ne demandons ni ne traitons de données. Nous pouvons également supposer que notre source de données l'estNone, ce qui indique que ce code n'a pas besoin d'effectuer d'invocations. La réponse renvoie simplement « Hello World ». Pour tester ce résolveur, nous devons faire une demande en utilisant le type de requête :
query helloWorldTest { helloWorld }
Il s'agit d'une requête appelée helloWorldTest qui renvoie le helloWorld champ. Lorsqu'il est exécuté, le résolveur de helloWorld champs exécute et renvoie également la réponse :
{ "data": { "helloWorld": "Hello World" } }
Renvoyer des constantes comme celle-ci est la chose la plus simple que vous puissiez faire. En réalité, vous allez renvoyer des entrées, des listes, etc. Voici un exemple plus complexe :
type Book { id: ID! title: String } type Query { getBooks: [Book] }
Nous renvoyons ici une liste deBooks. Supposons que nous utilisions une table DynamoDB pour stocker les données d'un livre. Nos gestionnaires peuvent ressembler à ceci :
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
Notre demande a utilisé une opération de numérisation intégrée pour rechercher toutes les entrées de la table, a stocké les résultats dans le contexte, puis les a transmis à la réponse. La réponse a pris les éléments du résultat et les a renvoyés dans la réponse :
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
Contexte du résolveur
Dans un résolveur, chaque étape de la chaîne de gestionnaires doit connaître l'état des données des étapes précédentes. Le résultat d'un gestionnaire peut être stocké et transmis à un autre en tant qu'argument. GraphQL définit quatre arguments de base du résolveur :
| Arguments de base du résolveur | Description |
|---|---|
obj, root, parent, etc. |
Le résultat du parent. |
args |
Les arguments fournis au champ dans la requête GraphQL. |
context |
Une valeur qui est fournie à chaque résolveur et contient des informations contextuelles importantes telles que l'utilisateur actuellement connecté ou l'accès à une base de données. |
info |
Une valeur qui contient des informations spécifiques au champ pertinentes pour la requête en cours ainsi que les détails du schéma. |
Dans AWS AppSync, l'argument context (ctx) peut contenir toutes les données mentionnées ci-dessus. Il s'agit d'un objet créé par demande et qui contient des données telles que les informations d'identification d'autorisation, les données de résultats, les erreurs, les métadonnées des demandes, etc. Le contexte est un moyen facile pour les programmeurs de manipuler les données provenant d'autres parties de la requête. Reprenez cet extrait :
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
La requête reçoit le contexte (ctx) comme argument ; il s'agit de l'état de la demande. Il effectue une analyse de tous les éléments d'un tableau, puis stocke le résultat dans le contexte dansresult. Le contexte est ensuite transmis à l'argument de réponse, qui accède au result et renvoie son contenu.
Requêtes et analyse syntaxique
Lorsque vous envoyez une requête à votre service GraphQL, celle-ci doit passer par un processus d'analyse et de validation avant d'être exécutée. Votre demande sera analysée et traduite dans un arbre syntaxique abstrait. Le contenu de l'arborescence est validé en exécutant plusieurs algorithmes de validation par rapport à votre schéma. Après l'étape de validation, les nœuds de l'arbre sont parcourus et traités. Les résolveurs sont appelés, les résultats sont stockés dans le contexte et la réponse est renvoyée. Prenons, par exemple, cette requête :
query { Person { //object type name //scalar age //scalar } }
Nous revenons Person avec un name et des age champs. Lors de l'exécution de cette requête, l'arborescence ressemblera à ceci :
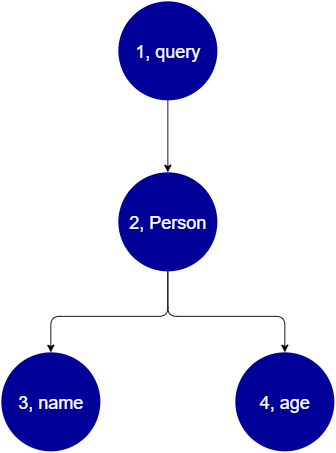
D'après l'arborescence, il apparaît que cette demande recherchera la racine Query dans le schéma. À l'intérieur de la requête, le Person champ sera résolu. D'après les exemples précédents, nous savons qu'il peut s'agir d'une entrée de l'utilisateur, d'une liste de valeurs, etc. Elle Person est très probablement liée à un type d'objet contenant les champs dont nous avons besoin (nameetage). Une fois que ces deux champs enfants sont trouvés, ils sont résolus dans l'ordre indiqué (namesuivi deage). Une fois que l'arbre est complètement résolu, la demande est terminée et sera renvoyée au client.
