Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données Hive
Pour déployer un connecteur de source de données Athena pour Hive, vous pouvez utiliser le AWS Serverless Application Repository
Pour utiliser le AWS Serverless Application Repository pour déployer un connecteur de source de données pour Hive sur votre compte
-
Connectez-vous au référentiel d'applications sans serveur AWS Management Console et ouvrez-le.
-
Dans le volet de navigation, choisissez Applications.
-
Sélectionnez l'option Show apps that create custom IAM roles or resource policies (Afficher les applications qui créent des rôles IAM ou des politiques de ressources personnalisés).
-
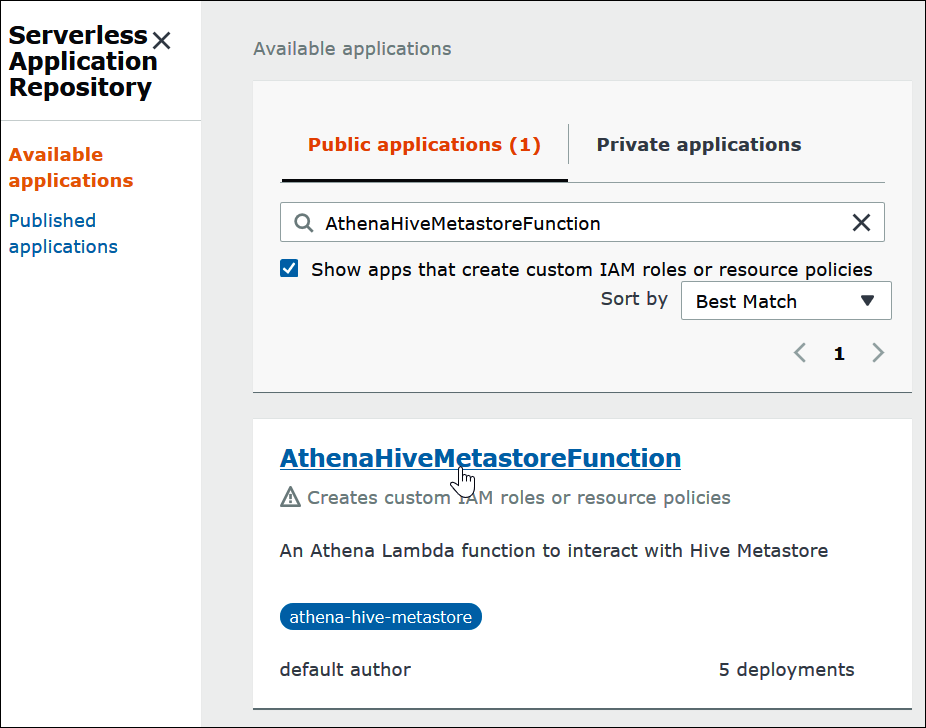
Dans la zone de recherche, saisissez
Hive. Les connecteurs qui apparaissent incluent les deux connecteurs suivants :-
AthenaHiveMetastoreFunction – Fichier
.jarde fonction Lambda uber. -
AthenaHiveMetastoreFunctionWithLayer – Couche Lambda et fichier
.jarde fonction Lambda mince.
Les deux applications ont les mêmes fonctionnalités et ne diffèrent que par leur implémentation. Vous pouvez utiliser l'une de ces deux méthodes pour créer une fonction Lambda qui connecte Athena à votre métastore Hive.
-
-
Choisissez le nom du connecteur que vous souhaitez utiliser. Ce tutoriel utilise AthenaHiveMetastoreFunction.
Sous Application settings (Paramètres de l'application), saisissez les paramètres de votre fonction Lambda.
-
LambdaFuncName— Donnez un nom à la fonction. Par exemple, myHiveMetastore.
-
SpillLocation— Spécifiez un emplacement Amazon S3 dans ce compte pour stocker les métadonnées dérivées si la taille de réponse de la fonction Lambda dépasse 4 Mo.
-
HMSUris— Entrez l'URI de votre hôte de métastore Hive qui utilise le protocole Thrift sur le port 9083. Utilisez la syntaxe
thrift://<host_name>:9083. -
LambdaMemory— Spécifiez une valeur comprise entre 128 Mo et 3 008 Mo. La fonction Lambda se voit allouer des cycles d'UC proportionnels à la quantité de mémoire que vous configurez. La valeur par défaut est 1024.
-
LambdaTimeout— Spécifiez le temps d'exécution d'appel Lambda maximal autorisé en secondes, de 1 à 900 (900 secondes correspondent à 15 minutes). La valeur par défaut est de 300 secondes (5 minutes).
-
VPCSecurityGroupIds— Entrez une liste de groupes de sécurité VPC séparés par des virgules IDs pour le métastore Hive.
-
VPCSubnetIds — Entrez une liste de IDs sous-réseaux VPC séparés par des virgules pour le métastore Hive.
-
-
En bas à droite de la page Application details (Détails de l'application), sélectionnez I acknowledge that this app creates custom IAM roles (Je reconnais que cette application crée des rôles IAM personnalisés), puis choisissez Deploy (Déployer).
À ce stade, vous pouvez configurer le service Athena pour qu'il utilise votre fonction Lambda afin de se connecter à votre métastore Hive. Pour les étapes, consultez Configuration d'Athena pour utiliser un connecteur de métastore Hive déployé.
