Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Téléchargement de fichiers pour la première fois
Vous pouvez utiliser la fonction d' AWS Supply Chain association automatique pour télécharger vos données brutes et les associer automatiquement au modèle de AWS Supply Chain données. Vous pouvez également afficher les colonnes et les tableaux requis pour chaque AWS Supply Chain module dans l'application AWS Supply Chain Web.
Pour une brève démonstration du fonctionnement de l'auto-association, regardez la vidéo suivante :
Note
Vous ne pouvez charger des fichiers CSV sur Amazon S3 que lorsque vous utilisez l'association automatique.
Une fois que les colonnes source de votre jeu de données sont associées aux colonnes de destination, la recette SQL AWS Supply Chain sera automatiquement générée.
Note
AWS Supply Chain utilise Amazon Bedrock pour l'association automatique, qui n'est pas prise en charge dans toutes les AWS AWS Supply Chain régions et régions disponibles. Par conséquent, AWS Supply Chain vous appellerez le point de terminaison Amazon Bedrock depuis la région disponible la plus proche, à savoir la région Europe (Irlande) — Europe (Francfort) et la région Asie-Pacifique (Sydney) — USA Ouest (Oregon).
Note
L'association automatique à l'aide des grands modèles linguistiques (LLM) n'est prise en charge que lorsque les données sont ingérées via Amazon S3.
-
Sur le AWS Supply Chain tableau de bord, dans le volet de navigation de gauche, choisissez Data Lake, puis l'onglet Data Ingestion.
La page Ingestion des données s'affiche.
Choisissez Ajouter une nouvelle source.
La page Sélectionnez votre source de données apparaît.
Sur la page Sélectionnez votre source de données, choisissez Charger des fichiers.
Choisissez Continuer.

Sur la page Quelles fonctionnalités souhaitez-vous exécuter, choisissez les AWS Supply Chain modules que vous souhaitez utiliser. Vous pouvez choisir plusieurs modules.
Dans la section Charger vos fichiers source, ajoutez un suffixe au nom du système source. Par exemple, oracle_test.
Pour télécharger votre jeu de données source, choisissez des fichiers ou glissez-déposez des fichiers.
Les tables sources avec le nom et le statut sont affichées.
Choisissez Upload to S3. L'état du téléchargement changera pour afficher le statut.
Sous Vérifier les exigences en matière de données, passez en revue toutes les entités de données et colonnes requises pour la AWS Supply Chain fonctionnalité sélectionnée. Toutes les clés primaires et étrangères requises sont affichées.
Choisissez Continuer.
Sous Gérer vos tables sources, les tables sources suivantes et les colonnes répertoriées seront associées automatiquement et importées dans le lac de données.
Choisissez Supprimer la table pour supprimer toutes les tables sources avant de les importer dans le lac de données.
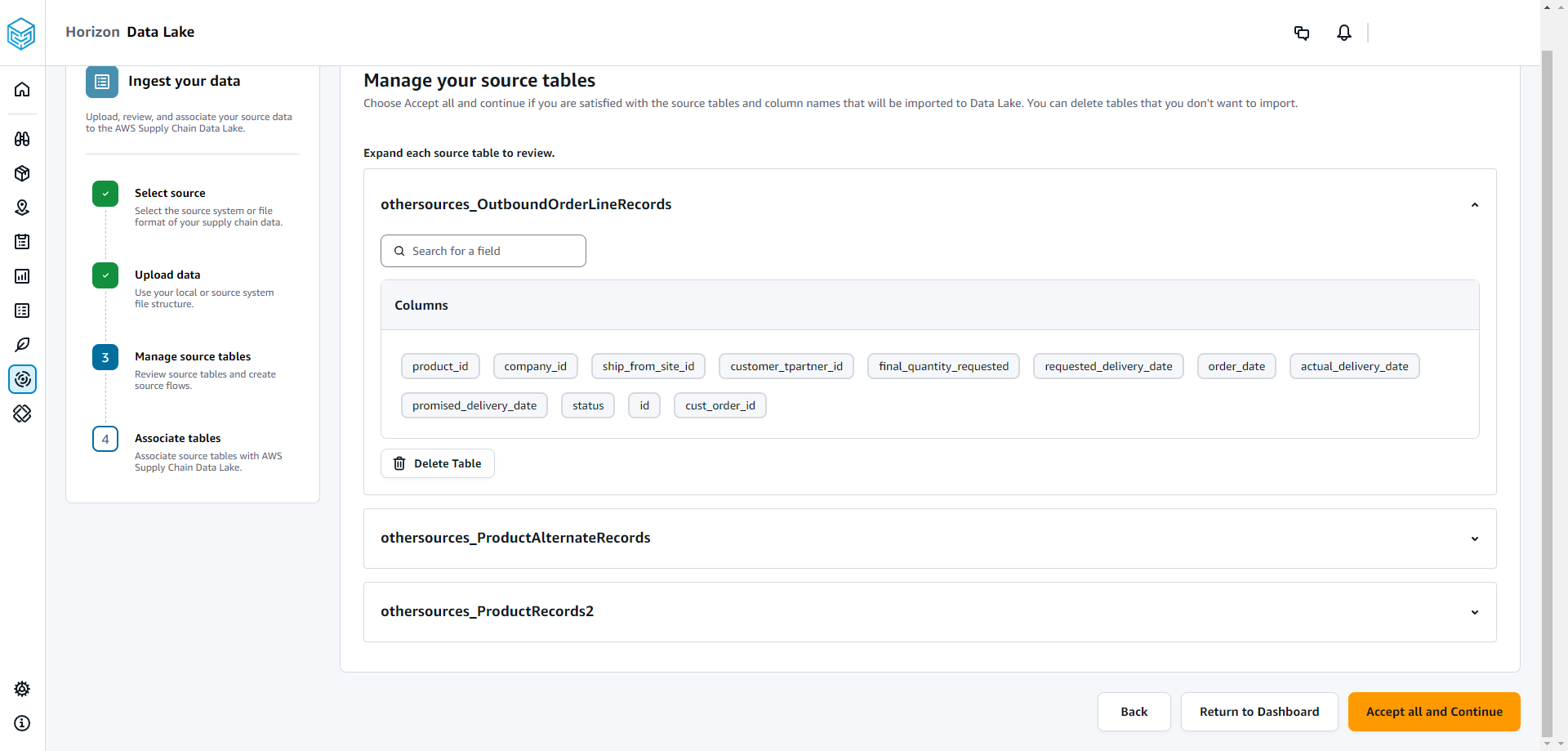
Choisissez Tout accepter et continuer.
Un message sur l'association automatique de vos tables au lac de AWS Supply Chain données s'affiche.
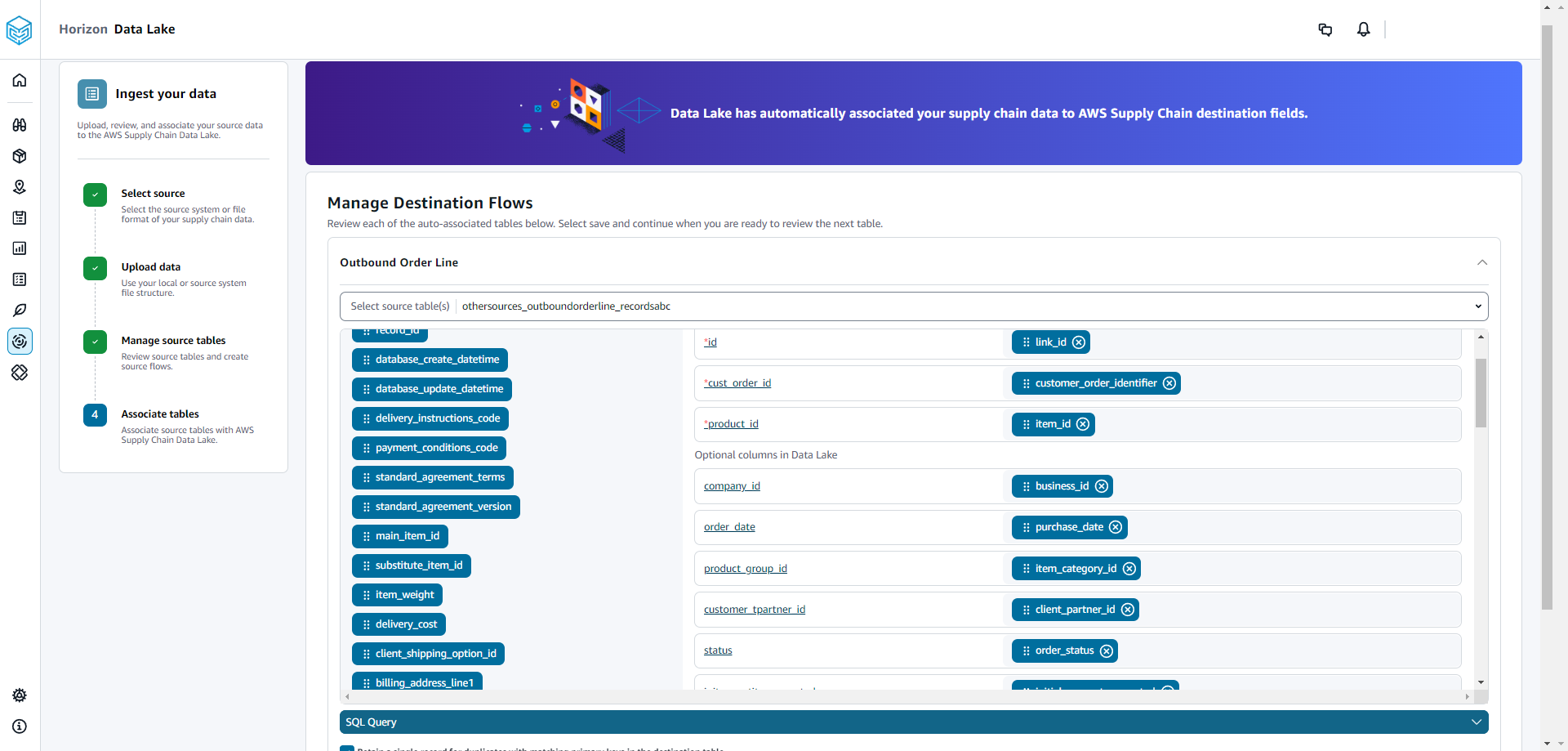
Sous Gérer les flux de destination, vous pouvez consulter chaque table associée automatiquement.
Par défaut, l'association automatique est activée et les colonnes source sont associées automatiquement aux colonnes de destination. Pour mettre à jour les colonnes associées automatiquement, vous pouvez mettre à jour la recette SQL afin de créer votre recette personnalisée.
Sous Colonnes source, toutes les colonnes source non associées sont répertoriées. Faites glisser les colonnes non associées vers les colonnes de destination sur la droite.
Suivez l'étape précédente pour chaque table associée automatiquement.
Sélectionnez Envoyer.
Choisissez Exit and Review Destination Flows.
