Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comment fonctionnent les bases de connaissances Amazon Bedrock
Les bases de connaissances Amazon Bedrock vous aident à tirer parti de la génération augmentée de récupération (RAG), une technique populaire qui consiste à extraire des informations d'un magasin de données pour augmenter les réponses générées par les grands modèles linguistiques (). LLMs Lorsque vous configurez une base de connaissances avec votre source de données, votre application peut interroger la base de connaissances afin de renvoyer des informations permettant de répondre à la requête, soit avec des citations directes provenant des sources, soit avec des réponses naturelles générées à partir des résultats de la requête.
Avec les bases de connaissances Amazon Bedrock, vous pouvez créer des applications enrichies par le contexte reçu en interrogeant une base de connaissances. Il permet de réduire les délais de mise sur le marché en vous évitant les lourdes tâches liées à la construction de pipelines et en vous fournissant une solution out-of-the-box RAG pour réduire le temps de création de votre application. L’ajout d’une base de connaissances augmente également la rentabilité en évitant d’avoir à entraîner en permanence le modèle afin de tirer parti de vos données privées.
Les schémas suivants illustrent grossièrement le fonctionnement du modèle RAG. La base de connaissances simplifie la configuration et la mise en œuvre de RAG en automatisant plusieurs étapes de ce processus.
Prétraitement des données non structurées
Pour permettre une extraction efficace à partir de données privées non structurées (données qui n'existent pas dans un magasin de données structurées), une pratique courante consiste à convertir les données en texte et à les diviser en éléments gérables. Les pièces ou les morceaux sont ensuite convertis en éléments incorporés et écrits dans un index vectoriel, tout en conservant un mappage avec le document original. Ces intégrations sont utilisées pour déterminer la similitude sémantique entre les requêtes et le texte provenant des sources de données. L’image suivante illustre le traitement préalable des données pour la base de données vectorielles.
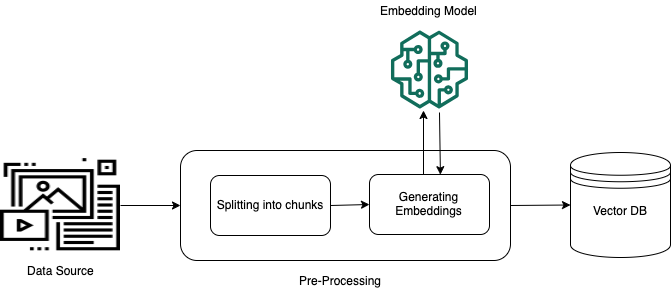
Les intégrations vectorielles sont une série de nombres qui représentent chaque partie du texte. Un modèle convertit chaque fragment de texte en séries de nombres, appelées vecteurs, afin que les textes puissent être comparés mathématiquement. Ces vecteurs peuvent être des nombres à virgule flottante (float32) ou des nombres binaires. La plupart des modèles d'intégration pris en charge par Amazon Bedrock utilisent des vecteurs à virgule flottante par défaut. Cependant, certains modèles prennent en charge les vecteurs binaires. Si vous choisissez un modèle d'intégration binaire, vous devez également choisir un modèle et un magasin de vecteurs qui prennent en charge les vecteurs binaires.
Les vecteurs binaires, qui n'utilisent qu'un bit par dimension, ne sont pas aussi coûteux en stockage que les vecteurs à virgule flottante (float32), qui utilisent 32 bits par dimension. Cependant, les vecteurs binaires ne sont pas aussi précis que les vecteurs à virgule flottante dans leur représentation du texte.
L'exemple suivant montre un morceau de texte sous trois formes :
| Représentation | Valeur |
|---|---|
| Texte | « Amazon Bedrock utilise des modèles de base très performants développés par les principales sociétés d'IA et Amazon. » |
| Vecteur à virgule flottante | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| Vecteur binaire | [1,1,0,0,0, ...] |
Exécution du runtime
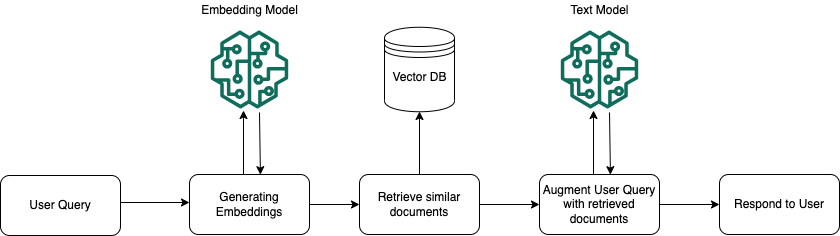
Au moment de l’exécution, un modèle d’intégration est utilisé pour convertir la requête de l’utilisateur en vecteur. L’index vectoriel est ensuite interrogé pour trouver les segments dont la sémantique est similaire à la requête de l’utilisateur en comparant les vecteurs de documents au vecteur de requête de l’utilisateur. Au cours de la dernière étape, l’invite utilisateur est complétée par le contexte supplémentaire provenant des segments extraits de l’index vectoriel. L’invite associée au contexte supplémentaire est ensuite envoyée au modèle pour générer une réponse pour l’utilisateur. L’image suivante montre comment la génération augmentée par récupération fonctionne au moment de l’exécution pour compléter les réponses aux requêtes des utilisateurs.
Pour en savoir plus sur la façon de transformer vos données en base de connaissances, comment interroger votre base de connaissances après l'avoir configurée et sur les personnalisations que vous pouvez appliquer à la source de données lors de l'ingestion, consultez les rubriques suivantes :
Rubriques
