Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'un lac de données du SDK Amazon Chime
Le lac de données d'analyse des appels du SDK Amazon Chime vous permet de diffuser vos informations basées sur l'apprentissage automatique et toutes les métadonnées d'Amazon Kinesis Data Stream vers votre compartiment Amazon S3. Par exemple, utiliser le lac de données pour accéder URLs aux enregistrements. Pour créer le lac de données, vous déployez un ensemble de AWS CloudFormation modèles depuis la console Amazon Chime SDK ou par programmation à l'aide du. AWS CLI Le lac de données vous permet d'interroger les métadonnées de vos appels et les données d'analyse vocale en faisant référence aux tables de données AWS Glue dans Amazon Athena.
Rubriques
Prérequis
Vous devez disposer des éléments suivants pour créer un lac de SDK Amazon Chime :
-
Un flux de données Amazon Kinesis. Pour plus d'informations, reportez-vous à la section Création d'un flux via la console de gestion AWS dans le manuel Amazon Kinesis Streams Developer Guide.
-
Un compartiment S3. Pour plus d'informations, reportez-vous à la section Création de votre premier compartiment Amazon S3 dans le guide de l'utilisateur Amazon S3.
Terminologie et concepts relatifs aux lacs de données
Utilisez les termes et concepts suivants pour comprendre le fonctionnement du lac de données.
- Amazon Kinesis Data Firehose
-
Un service d'extraction, de transformation et de chargement (ETL) qui capture, transforme et diffuse de manière fiable des données en streaming vers des lacs de données, des magasins de données et des services d'analyse. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Kinesis Data Firehose ?
- Amazon Athena
-
Amazon Athena est un service de requête interactif qui vous permet d'analyser des données dans Amazon S3 à l'aide du SQL standard. Athena fonctionne sans serveur, vous n'avez donc aucune infrastructure à gérer et vous ne payez que pour les requêtes que vous exécutez. Pour utiliser Athena, pointez sur vos données dans Amazon S3, définissez le schéma et utilisez des requêtes SQL standard. Vous pouvez également utiliser des groupes de travail pour regrouper les utilisateurs et contrôler les ressources auxquelles ils ont accès lorsqu'ils exécutent des requêtes. Les groupes de travail vous permettent de gérer la simultanéité des requêtes et de hiérarchiser l'exécution des requêtes entre différents groupes d'utilisateurs et différentes charges de travail.
- Catalogue de données Glue
-
Dans Amazon Athena, les tables et les bases de données contiennent les métadonnées qui détaillent le schéma des données sources sous-jacentes. Pour chaque jeu de données, une table doit exister dans Athena. Les métadonnées du tableau indiquent à Athena l'emplacement de votre compartiment Amazon S3. Il spécifie également la structure des données, telle que les noms des colonnes, les types de données et le nom de la table. Les bases de données contiennent uniquement les métadonnées et les informations de schéma d'un ensemble de données.
Création de plusieurs lacs de données
Plusieurs lacs de données peuvent être créés en fournissant un nom de base de données Glue unique pour spécifier où stocker les informations relatives aux appels. Pour un AWS compte donné, il peut y avoir plusieurs configurations d'analyse des appels, chacune étant associée à un lac de données correspondant. Cela signifie que la séparation des données peut être appliquée dans certains cas d'utilisation, tels que la personnalisation de la politique de conservation et de la politique d'accès sur la manière dont les données sont stockées. Différentes politiques de sécurité peuvent être appliquées pour l'accès aux informations, aux enregistrements et aux métadonnées.
Disponibilité régionale du data lake
Le lac de données du SDK Amazon Chime est disponible dans les régions suivantes.
Région |
Table Glue |
QuickSight |
|---|---|---|
us-east-1 |
Disponible |
Disponible |
us-west-2 |
Disponible |
Disponible |
eu-central-1 |
Disponible |
Disponible |
Architecture du lac de données
Le schéma suivant montre l'architecture du lac de données. Les numéros du dessin correspondent au texte numéroté ci-dessous.
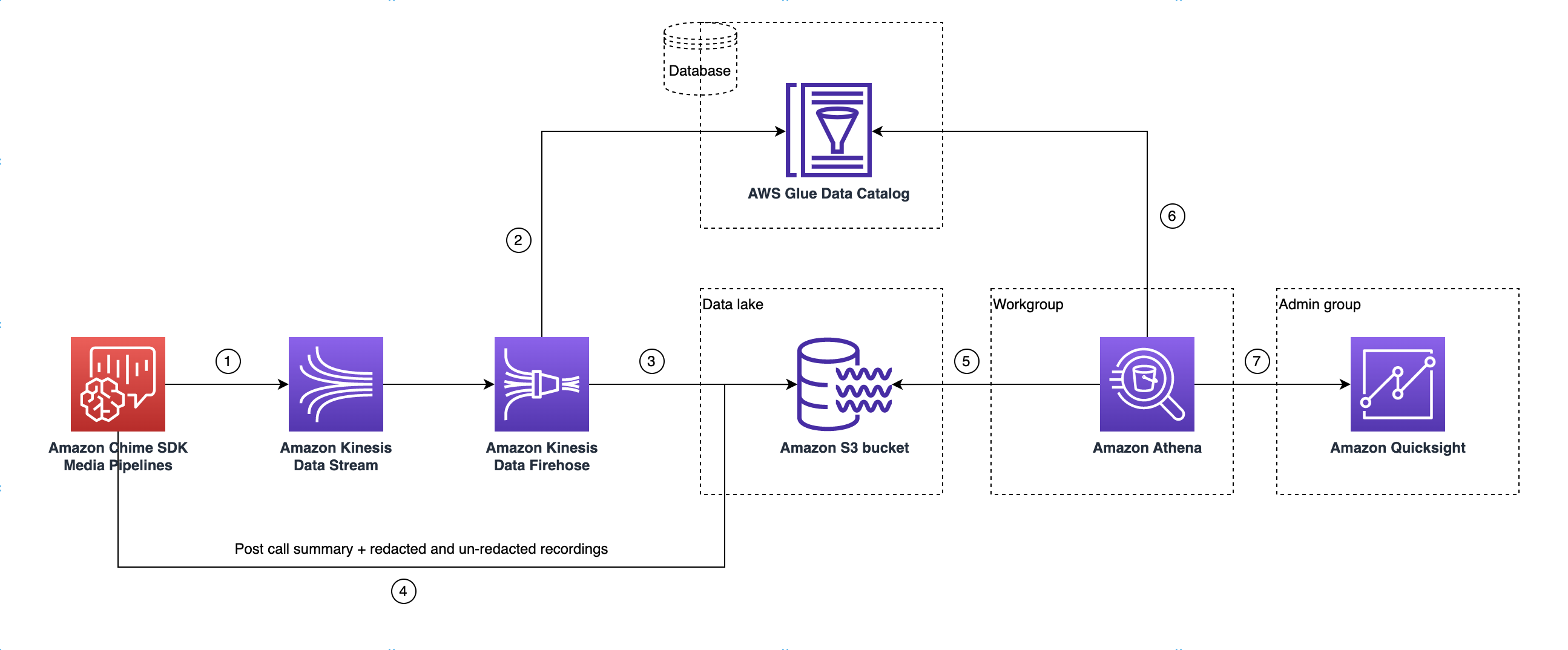
Dans le schéma, une fois que vous avez utilisé la AWS console pour déployer le CloudFormation modèle à partir du flux de travail de configuration du pipeline Media Insights, les données suivantes sont transmises au compartiment Amazon S3 :
-
L'analyse des appels du SDK Amazon Chime commencera à diffuser des données en temps réel vers le flux de données Kinesis du client.
-
Amazon Kinesis Firehose met en mémoire tampon ces données en temps réel jusqu'à ce qu'elles accumulent 128 Mo, soit 60 secondes, selon la première éventualité. Firehose utilise ensuite le catalogue
amazon_chime_sdk_call_analytics_firehose_schemade données Glue pour compresser les données et transforme les enregistrements JSON en fichier parquet. -
Le fichier parquet se trouve dans votre compartiment Amazon S3, dans un format partitionné.
-
Outre les données en temps réel, les fichiers .wav récapitulatifs Amazon Transcribe Call Analytics après l'appel (expurgés et non expurgés, si cela est spécifié dans la configuration) et les fichiers .wav d'enregistrement des appels sont également envoyés à votre compartiment Amazon S3.
-
Vous pouvez utiliser Amazon Athena et le SQL standard pour interroger les données du compartiment Amazon S3.
-
Le CloudFormation modèle crée également un catalogue de données Glue pour interroger ces données récapitulatives après l'appel via Athena.
-
Toutes les données du compartiment Amazon S3 peuvent également être visualisées à l'aide QuickSight de. QuickSight établit une connexion avec un compartiment Amazon S3 à l'aide d'Amazon Athena.
La table Amazon Athena utilise les fonctionnalités suivantes pour optimiser les performances des requêtes :
- Partitionnement de données
-
Le partitionnement divise votre table en plusieurs parties et conserve les données associées en fonction des valeurs des colonnes telles que la date, le pays et la région. Les partitions agissent comme des colonnes virtuelles. Dans ce cas, le CloudFormation modèle définit les partitions lors de la création de la table, ce qui permet de réduire la quantité de données numérisées par requête et d'améliorer les performances. Vous pouvez également filtrer par partition pour limiter la quantité de données numérisées par une requête. Pour plus d'informations, reportez-vous à la section Partitionnement des données dans Athena dans le guide de l'utilisateur d'Amazon Athena.
Cet exemple montre une structure de partitionnement datée du 1er janvier 2023 :
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
où se
DETAIL_TYPEtrouve l'un des suivants :-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- Optimisation de la génération de banques de données en colonnes
-
Apache Parquet utilise la compression par colonne, la compression basée sur le type de données et le transfert des prédicats vers le bas pour stocker les données. De meilleurs taux de compression ou le fait de sauter des blocs de données permettent de lire moins d'octets dans votre compartiment Amazon S3. Cela permet d'améliorer les performances des requêtes et de réduire les coûts. Pour cette optimisation, la conversion des données de JSON en parquet est activée dans Amazon Kinesis Data Firehose.
- Projection de partition
-
Cette fonctionnalité d'Athena crée automatiquement des partitions pour chaque jour afin d'améliorer les performances des requêtes basées sur les dates.
Configuration du lac de données
Utilisez la console Amazon Chime SDK pour effectuer les étapes suivantes.
-
Démarrez la console Amazon Chime SDK ( https://console.aws.amazon.com/chime-sdk/accueil
) et dans le volet de navigation, sous Call Analytics, sélectionnez Configurations. -
Terminez l'étape 1, choisissez Suivant, puis sur la page Étape 2, cochez la case Voice Analytics.
-
Sous Détails de la sortie, cochez la case Entrepôt de données pour effectuer une analyse historique, puis cliquez sur le lien Déployer la CloudFormation pile.
Le système vous renvoie vers la page Quick Create Stack de la CloudFormation console.
-
Entrez un nom pour la pile, puis entrez les paramètres suivants :
-
DataLakeType— Choisissez Create Call Analytics DataLake. -
KinesisDataStreamName— Choisissez votre stream. Il doit s'agir du flux utilisé pour le streaming des analyses d'appels. -
S3BucketURI— Choisissez votre compartiment Amazon S3. L'URI doit avoir le préfixes3://bucket-name -
GlueDatabaseName— Choisissez un nom de base de données AWS Glue unique. Vous ne pouvez pas réutiliser une base de données existante dans le AWS compte.
-
-
Cochez la case d'accusé de réception, puis choisissez Create data lake. Attendez 10 minutes pour que le système crée le lac.
Configuration du lac de données à l'aide de AWS CLI
AWS CLI À utiliser pour créer un rôle autorisé à créer une pile CloudFormation d'appels. Suivez la procédure ci-dessous pour créer et configurer les rôles IAM. Pour plus d'informations, consultez la section Création d'une pile dans le guide de AWS CloudFormation l'utilisateur.
-
Créez un rôle appelé AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role et associez une politique de confiance au rôle permettant de l'assumer. CloudFormation
-
Créez une politique de confiance IAM à l'aide du modèle suivant et enregistrez le fichier au format .json.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
Exécutez la aws iam create-role commande et transmettez la politique de confiance en tant que paramètre.
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
Notez l'ARN du rôle renvoyé par la réponse. le rôle arn est requis à l'étape suivante.
-
-
Créez une politique avec l'autorisation de créer une CloudFormation pile.
-
Créez une politique IAM à l'aide du modèle suivant et enregistrez le fichier au format .json. Ce fichier est obligatoire lors de l'appel à create-policy.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
Exécutez aws iam create-policy et transmettez la politique de création de pile en tant que paramètre.
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
Notez l'ARN du rôle renvoyé par la réponse. le rôle arn est requis à l'étape suivante.
-
-
Attachez la stratégie aws iam attach-role-policy au rôle.
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
Créez une CloudFormation pile et entrez les paramètres requis :aws cloudformation create-stack.
Fournissez des valeurs de paramètres pour chaque ParameterKey utilisation ParameterValue.
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
Ressources créées par la configuration du lac de données
Le tableau suivant répertorie les ressources créées lorsque vous créez un lac de données.
Type de ressource |
Nom et description de la ressource |
Nom du service |
|---|---|---|
Base de données du catalogue de données AWS Glue |
GlueDatabaseName— Regroupe de manière logique toutes les tables de données AWS Glue appartenant à l'analyse des appels et à l'analyse vocale. |
Analyse des appels, analyse vocale |
|
Tableaux du catalogue de données AWS Glue |
amazon_chime_sdk_call_analytics_firehose_schema — Schéma combiné pour l'analyse des appels et l'analyse vocale transmis au Kinesis Firehose. |
Analyse des appels, analyse vocale |
call_analytics_metadata — Schéma pour les métadonnées d'analyse des appels. Contient SIPmetadata et OneTimeMetadata. |
Analyse des appels |
|
| call_analytics_recording_metadata — Schéma pour les métadonnées d'enregistrement et d'amélioration vocale | Analyse des appels, analyse vocale | |
transcribe_call_analytics — Schéma de la charge utile « UtteranceEvent » TranscribeCallAnalytics |
Analyse des appels |
|
transcribe_call_analytics_category_events — Schéma de la charge utile « CategoryEvent » TranscribeCallAnalytics |
Analyse des appels |
|
transcribe_call_analytics_post_call — Schéma pour la charge utile récapitulative de Post-Call Transcribe Call Analytics |
Analyse des appels |
|
transcribe — Schéma pour la charge utile de transcription |
Analyse des appels |
|
voice_analytics_status — Schéma pour les événements prêts pour l'analyse vocale |
Analyses vocales |
|
speaker_search_status — Schéma pour les correspondances d'identification |
Analyses vocales |
|
voice_tone_analysis_status — Schéma pour les événements d'analyse de tonalité vocale |
Analyses vocales |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-Call-Analytics- — Kinesis |
Analyse des appels, analyse vocale |
Groupe de travail Amazon Athena |
GlueDatabaseName- AmazonChime SDKData Analyses : groupe logique d'utilisateurs chargé de contrôler les ressources auxquelles ils ont accès lors de l'exécution de requêtes. |
Analyse des appels, analyse vocale |
