Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Métriques de classification personnalisées
Amazon Comprehend fournit des statistiques pour vous aider à estimer les performances d'un classificateur personnalisé. Amazon Comprehend calcule les métriques à l'aide des données de test issues de la tâche de formation du classificateur. Les métriques représentent avec précision les performances du modèle pendant l'entraînement, de sorte qu'elles se rapprochent des performances du modèle pour la classification de données similaires.
Utilisez des opérations d'API, par exemple DescribeDocumentClassifierpour récupérer les métriques d'un classificateur personnalisé.
Note
Reportez-vous à la section Métriques : précision, rappel et FScore
Métriques
Amazon Comprehend prend en charge les métriques suivantes :
Pour consulter les métriques d'un classificateur, ouvrez la page Détails du classificateur dans la console.
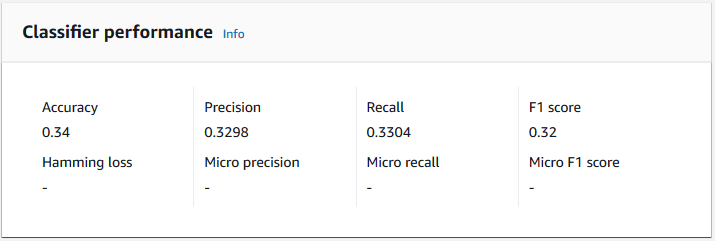
Précision
La précision indique le pourcentage d'étiquettes à partir des données de test que le modèle a prédit avec précision. Pour calculer la précision, divisez le nombre d'étiquettes prédites avec précision dans les documents de test par le nombre total d'étiquettes dans les documents de test.
Par exemple
| Étiquette réelle | Étiquette prévue | Exactif/Incorrect |
|---|---|---|
|
1 |
1 |
Précis |
|
0 |
1 |
Incorrect |
|
2 |
3 |
Incorrect |
|
3 |
3 |
Précis |
|
2 |
2 |
Précis |
|
1 |
1 |
Précis |
|
3 |
3 |
Précis |
La précision correspond au nombre de prédictions exactes divisé par le nombre total d'échantillons de test = 5/7 = 0,714, soit 71,4 %
Précision (macroprécision)
La précision est une mesure de l'utilité des résultats du classificateur dans les données de test. Il est défini comme le nombre de documents classés avec précision, divisé par le nombre total de classifications pour la classe. La haute précision signifie que le classificateur a renvoyé des résultats nettement plus pertinents que des résultats non pertinents.
La Precision métrique est également connue sous le nom de Macro Precision.
L'exemple suivant montre les résultats de précision pour un ensemble de tests.
| Étiquette | Taille de l'échantillon | Précision de l'étiquette |
|---|---|---|
|
Étiquette_1 |
400 |
0.75 |
|
Étiquette_2 |
300 |
0,80 |
|
Étiquette_3 |
30 000 |
0.90 |
|
Étiquette_4 |
20 |
0.50 |
|
Étiquette_5 |
10 |
0,40 |
La métrique de précision (précision macro) du modèle est donc la suivante :
Macro Precision = (0.75 + 0.80 + 0.90 + 0.50 + 0.40)/5 = 0.67Rappel (rappel de macros)
Cela indique le pourcentage de catégories correctes dans votre texte que le modèle peut prévoir. Cette métrique provient de la moyenne des scores de rappel de toutes les étiquettes disponibles. Le rappel est une mesure de l'exhaustivité des résultats du classificateur pour les données de test.
Un taux de rappel élevé signifie que le classificateur a renvoyé la plupart des résultats pertinents.
La Recall métrique est également connue sous le nom de Macro Recall.
L'exemple suivant montre les résultats du rappel d'un ensemble de tests.
| Étiquette | Taille de l'échantillon | Rappel d'étiquettes |
|---|---|---|
|
Étiquette_1 |
400 |
0,70 |
|
Étiquette_2 |
300 |
0,70 |
|
Étiquette_3 |
30 000 |
0,98 |
|
Étiquette_4 |
20 |
0,80 |
|
Étiquette_5 |
10 |
0.10 |
La métrique de rappel (rappel de macros) du modèle est donc la suivante :
Macro Recall = (0.70 + 0.70 + 0.98 + 0.80 + 0.10)/5 = 0.656Score F1 (score F1 macro)
Le score F1 est dérivé des Recall valeurs Precision et. Il mesure la précision globale du classificateur. Le score le plus élevé est 1 et le score le plus bas est 0.
Amazon Comprehend calcule le score Macro F1. Il s'agit de la moyenne non pondérée des scores F1 du label. En utilisant le kit de test suivant comme exemple :
| Étiquette | Taille de l'échantillon | Libellé : score F1 |
|---|---|---|
|
Étiquette_1 |
400 |
0,724 |
|
Étiquette_2 |
300 |
0,824 |
|
Étiquette_3 |
30 000 |
0,94 |
|
Étiquette_4 |
20 |
0,62 |
|
Étiquette_5 |
10 |
0,16 |
Le score F1 (score Macro F1) du modèle est calculé comme suit :
Macro F1 Score = (0.724 + 0.824 + 0.94 + 0.62 + 0.16)/5 = 0.6536Défaite de Hamming
Fraction d'étiquettes incorrectement prédites. Également considéré comme la fraction d'étiquettes incorrectes par rapport au nombre total d'étiquettes. Des scores proches de zéro sont meilleurs.
Microprécision
Original :
Similaire à la métrique de précision, sauf que la microprécision est basée sur le score global de tous les scores de précision additionnés.
Micro rappel
Similaire à la métrique de rappel, sauf que le micro rappel est basé sur le score global de tous les scores de rappel additionnés.
Score de Micro F1
Le score Micro F1 est une combinaison des métriques Micro Precision et Micro Recall.
Améliorer les performances de votre classificateur personnalisé
Les métriques fournissent un aperçu des performances de votre classificateur personnalisé lors d'une tâche de classification. Si les indicateurs sont faibles, le modèle de classification risque de ne pas être efficace pour votre cas d'utilisation. Plusieurs options s'offrent à vous pour améliorer les performances de votre classificateur :
-
Dans vos données d'entraînement, fournissez des exemples concrets qui définissent une séparation claire des catégories. Par exemple, fournissez des documents qui utilisent le caractère unique words/sentences pour représenter la catégorie.
-
Ajoutez des données supplémentaires pour les étiquettes sous-représentées dans vos données d'entraînement.
-
Essayez de réduire le biais dans les catégories. Si la plus grande étiquette de vos données contient plus de 10 fois le nombre de documents figurant dans la plus petite étiquette, essayez d'augmenter le nombre de documents pour la plus petite étiquette. Assurez-vous de réduire le rapport d'asymétrie à 10:1 au maximum entre les classes les plus représentées et les moins représentées. Vous pouvez également essayer de supprimer les documents d'entrée des classes les plus représentées.
