Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Étape 4 : Préparation de la sortie Amazon Comprehend pour la visualisation des données
Pour préparer les résultats des tâches d'analyse des sentiments et des entités afin de créer des visualisations de données, vous utilisez AWS Glue et Amazon Athena. Au cours de cette étape, vous allez extraire les fichiers de résultats d'Amazon Comprehend. Ensuite, vous créez un AWS Glue robot d'exploration qui explore vos données et les catalogue automatiquement dans les tableaux du. AWS Glue Data Catalog Ensuite, vous pouvez accéder à ces tables et les transformer à l'aide Amazon Athena d'un service de requête interactif et sans serveur. Lorsque vous avez terminé cette étape, vos résultats Amazon Comprehend sont propres et prêts à être visualisés.
Pour une tâche de détection d'entités PII, le fichier de sortie est en texte brut et non une archive compressée. Le nom du fichier de sortie est le même que celui du fichier d'entrée, avec .out un ajout à la fin. Vous n'avez pas besoin de l'étape d'extraction du fichier de sortie. Passez à Charger les données dans un AWS Glue Data Catalog.
Rubriques
Prérequis
Avant de commencer, complétez Étape 3 : Exécution de tâches d'analyse sur des documents dans Amazon S3.
Téléchargez le résultat
Amazon Comprehend utilise la compression Gzip pour compresser les fichiers de sortie et les enregistrer sous forme d'archive tar. Le moyen le plus simple d'extraire les fichiers de sortie est de télécharger les output.tar.gz archives localement.
Au cours de cette étape, vous allez télécharger les archives de sortie des sentiments et des entités.
Pour trouver les fichiers de sortie pour chaque tâche, revenez à la tâche d'analyse dans la console Amazon Comprehend. La tâche d'analyse fournit l'emplacement S3 de la sortie, où vous pouvez télécharger le fichier de sortie.
Pour télécharger les fichiers de sortie (console)
-
Dans la console Amazon Comprehend
, dans le volet de navigation, revenez à Analysis jobs. -
Choisissez votre job d'analyse des sentiments
reviews-sentiment-analysis. -
Sous Sortie, choisissez le lien affiché à côté de Emplacement des données de sortie. Cela vous redirige vers l'
output.tar.gzarchive de votre compartiment S3. -
Dans l'onglet Vue d'ensemble, choisissez Télécharger.
-
Sur votre ordinateur, renommez l'archive en
sentiment-output.tar.gz. Comme tous les fichiers de sortie portent le même nom, cela vous permet de suivre les fichiers de sentiments et d'entités. -
Répétez les étapes 1 à 4 pour rechercher et télécharger le résultat de votre
reviews-entities-analysistravail. Sur votre ordinateur, renommez l'archive enentities-output.tar.gz.
Pour rechercher les fichiers de sortie pour chaque tâche, utilisez le fichier JobId de la tâche d'analyse pour trouver l'emplacement S3 de la sortie. Utilisez ensuite la cp commande pour télécharger le fichier de sortie sur votre ordinateur.
Pour télécharger les fichiers de sortie (AWS CLI)
-
Pour répertorier les détails de votre tâche d'analyse des sentiments, exécutez la commande suivante. Remplacez
sentiment-job-idJobIdque vous avez enregistré.aws comprehend describe-sentiment-detection-job --job-idsentiment-job-idSi vous avez perdu la trace de votre offre d'emploi
JobId, vous pouvez exécuter la commande suivante pour répertorier toutes les offres d'emploi qui vous intéressent et filtrer par nom votre offre d'emploi.aws comprehend list-sentiment-detection-jobs --filter JobName="reviews-sentiment-analysis" -
Dans l'
OutputDataConfigobjet, trouvez laS3Urivaleur. LaS3Urivaleur doit être similaire au format suivant :s3://amzn-s3-demo-bucket/.../output/output.tar.gz -
Pour télécharger l'archive de sortie des sentiments dans votre répertoire local, exécutez la commande suivante. Remplacez le chemin du compartiment S3 par celui
S3Urique vous avez copié à l'étape précédente.path/sentiment-output.tar.gzremplace le nom de l'archive d'origine pour vous aider à suivre les fichiers de sentiments et d'entités.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/sentiment-output.tar.gz -
Pour répertorier les détails de votre tâche d'analyse des entités, exécutez la commande suivante.
aws comprehend describe-entities-detection-job --job-identities-job-idSi vous ne connaissez pas votre tâche
JobId, exécutez la commande suivante pour répertorier toutes les tâches de vos entités et filtrer votre tâche par nom.aws comprehend list-entities-detection-jobs --filter JobName="reviews-entities-analysis" -
À partir de l'
OutputDataConfigobjet figurant dans la description de poste de votre entité, copiez laS3Urivaleur. -
Pour télécharger l'archive de sortie des entités dans votre répertoire local, exécutez la commande suivante. Remplacez le chemin du compartiment S3 par celui
S3Urique vous avez copié à l'étape précédente.path/entities-output.tar.gzremplace le nom de l'archive d'origine.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/entities-output.tar.gz
Extraire les fichiers de sortie
Avant de pouvoir accéder aux résultats d'Amazon Comprehend, décompressez les archives des sentiments et des entités. Vous pouvez utiliser votre système de fichiers local ou un terminal pour décompresser les archives.
Si vous utilisez macOS, double-cliquez sur l'archive dans le système de fichiers de votre interface graphique pour extraire le fichier de sortie de l'archive.
Si vous utilisez Windows, vous pouvez utiliser un outil tiers tel que 7-Zip pour extraire les fichiers de sortie dans votre système de fichiers GUI. Sous Windows, vous devez effectuer deux étapes pour accéder au fichier de sortie dans l'archive. Décompressez d'abord l'archive, puis extrayez-la.
Renommez le fichier de sentiment comme sentiment-output et le fichier d'entités comme entities-output pour faire la distinction entre les fichiers de sortie.
Si vous utilisez Linux ou macOS, vous pouvez utiliser votre terminal standard. Si vous utilisez Windows, vous devez avoir accès à un environnement de type Unix, tel que Cygwin, pour exécuter des commandes tar.
Pour extraire le fichier de sortie des sentiments de l'archive des sentiments, exécutez la commande suivante sur votre terminal local.
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
Notez que le --transform paramètre ajoute le préfixe sentiment- au fichier de sortie à l'intérieur de l'archive, renommant le fichier en. sentiment-output Cela vous permet de faire la distinction entre les fichiers de sortie de sentiment et les fichiers de sortie des entités et d'éviter toute réécriture.
Pour extraire le fichier de sortie des entités de l'archive des entités, exécutez la commande suivante dans votre terminal local.
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
Le --transform paramètre ajoute le préfixe entities- au nom du fichier de sortie.
Astuce
Pour réduire les coûts de stockage dans Amazon S3, vous pouvez compresser à nouveau les fichiers avec Gzip avant de les télécharger. Il est important de décompresser et de décompresser les archives d'origine, car elles ne AWS Glue peuvent pas lire automatiquement les données d'une archive tar. Cependant, il AWS Glue peut lire des fichiers au format Gzip.
Téléchargez les fichiers extraits
Après avoir extrait les fichiers, chargez-les dans votre bucket. Vous devez stocker les fichiers de sortie des sentiments et des entités dans des dossiers séparés AWS Glue afin de lire correctement les données. Dans votre compartiment, créez un dossier pour les résultats de sentiment extraits et un second dossier pour les résultats des entités extraits. Vous pouvez créer des dossiers à l'aide de la console Amazon S3 ou du AWS CLI.
Dans votre compartiment S3, créez un dossier pour le fichier de résultats de sentiment extrait et un dossier pour le fichier de résultats d'entités. Téléchargez ensuite les fichiers de résultats extraits dans leurs dossiers respectifs.
Pour télécharger les fichiers extraits sur Amazon S3 (console)
Ouvrez la console Amazon S3 à l'adresse https://console.aws.amazon.com/s3/
. -
Dans Buckets, choisissez votre bucket, puis choisissez Create folder.
-
Pour le nouveau nom du dossier, entrez
sentiment-resultset choisissez Enregistrer. Ce dossier contiendra le fichier de sortie des sentiments extrait. -
Dans l'onglet Vue d'ensemble de votre bucket, dans la liste des contenus du bucket, choisissez le nouveau dossier
sentiment-results. Choisissez Charger. -
Choisissez Ajouter des fichiers, sélectionnez le
sentiment-outputfichier sur votre ordinateur local, puis cliquez sur Suivant. -
Conservez les options Gérer les utilisateurs, Accès pour les autres Compte AWS et Gérer les autorisations publiques comme options par défaut. Choisissez Suivant.
-
Pour Classe de stockage, choisissez Standard. Conservez les options de chiffrement, de métadonnées et de balise par défaut. Choisissez Suivant.
-
Passez en revue les options de téléchargement, puis choisissez Upload.
-
Répétez les étapes 1 à 8 pour créer un dossier appelé
entities-resultset téléchargez-y leentities-outputfichier.
Vous pouvez créer un dossier dans votre compartiment S3 lors du chargement d'un fichier à l'aide de la cp commande.
Pour télécharger les fichiers extraits sur Amazon S3 (AWS CLI)
-
Créez un dossier de sentiments et téléchargez-y votre fichier de sentiments en exécutant la commande suivante.
path/aws s3 cppath/sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/ -
Créez un dossier de sortie d'entités et téléchargez-y votre fichier d'entités en exécutant la commande suivante.
path/aws s3 cppath/entities-output s3://amzn-s3-demo-bucket/entities-results/
Chargez les données dans un AWS Glue Data Catalog
Pour enregistrer les résultats dans une base de données, vous pouvez utiliser un AWS Glue robot d'exploration. Un AWS Glue robot d'exploration analyse les fichiers et découvre le schéma des données. Il organise ensuite les données dans des tables dans une AWS Glue Data Catalog (base de données sans serveur). Vous pouvez créer un robot d'exploration à l'aide de la AWS Glue console ou du AWS CLI.
Créez un AWS Glue robot d'exploration qui analyse vos entities-results dossiers sentiment-results et vos dossiers séparément. Un nouveau rôle IAM pour AWS Glue
donne à l'explorateur l'autorisation d'accéder à votre compartiment S3. Vous créez ce rôle IAM lors de la configuration du robot d'exploration.
Pour charger les données dans une AWS Glue Data Catalog (console)
-
Assurez-vous que vous vous trouvez dans une région qui prend en charge AWS Glue. Si vous vous trouvez dans une autre région, dans la barre de navigation, choisissez une région prise en charge dans le sélecteur de région. Pour obtenir la liste des régions qui prennent en charge les infrastructures AWS Glue, consultez le tableau des régions
du Guide mondial des infrastructures. Ouvrez la AWS Glue console à l'adresse https://console.aws.amazon.com/glue/
. -
Dans le volet de navigation, choisissez Crawlers, puis choisissez Ajouter un robot d'exploration.
-
Pour le nom du robot d'exploration, entrez
comprehend-analysis-crawlerpuis choisissez Next. -
Pour le type de source Crawler, choisissez Data stores, puis Next.
-
Pour Ajouter un magasin de données, procédez comme suit :
-
Dans Choisir un magasin de données, choisissez S3.
-
Laissez le champ Connexion vide.
-
Pour explorer les données, choisissez le chemin spécifié dans mon compte.
-
Pour Inclure le chemin, entrez le chemin S3 complet du dossier de sortie des sentiments :
s3://amzn-s3-demo-bucket/sentiment-results. -
Choisissez Suivant.
-
-
Pour Ajouter un autre magasin de données, cliquez sur Oui, puis sur Suivant. Répétez l'étape 6, mais entrez le chemin S3 complet du dossier de sortie des entités :
s3://amzn-s3-demo-bucket/entities-results. -
Pour Ajouter un autre magasin de données, cliquez sur Non, puis sur Suivant.
-
Pour Choisir un rôle IAM, procédez comme suit :
-
Choisissez Créer un rôle IAM.
-
Pour le rôle IAM, entrez
glue-access-rolepuis choisissez Next.
-
-
Pour Créer un calendrier pour ce robot d'exploration, choisissez Exécuter à la demande, puis Suivant.
-
Pour configurer la sortie du robot d'exploration, procédez comme suit :
-
Pour Base de données, sélectionnez Ajouter une base de données.
-
Pour Database name (Nom de la base de données), entrez
comprehend-results. Cette base de données stockera vos tables de sortie Amazon Comprehend. -
Conservez les paramètres par défaut des autres options et choisissez Next.
-
-
Passez en revue les informations du crawler, puis choisissez Terminer.
-
Dans la console Glue, dans Crawlers, choisissez
comprehend-analysis-crawlerRun crawler. La fin du robot d'exploration peut prendre quelques minutes.
Créez un rôle IAM AWS Glue qui autorise l'accès à votre compartiment S3. Créez ensuite une base de données dans le AWS Glue Data Catalog. Enfin, créez et exécutez un robot d'exploration qui charge vos données dans les tables de la base de données.
Pour charger les données dans un AWS Glue Data Catalog (AWS CLI)
-
Pour créer un rôle IAM pour AWS Glue, procédez comme suit :
-
Enregistrez la politique de confiance suivante sous forme de document JSON appelé
glue-trust-policy.jsonsur votre ordinateur.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Pour créer un rôle IAM, exécutez la commande suivante.
path/aws iam create-role --role-name glue-access-role --assume-role-policy-document file://path/glue-trust-policy.json -
Lorsque le numéro de ressource Amazon (ARN) du nouveau rôle est AWS CLI répertorié, copiez-le et enregistrez-le dans un éditeur de texte.
-
Enregistrez la politique IAM suivante sous forme de document JSON appelé
glue-access-policy.jsonsur votre ordinateur. La politique AWS Glue autorise l'exploration de vos dossiers de résultats.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/sentiment-results*", "arn:aws:s3:::amzn-s3-demo-bucket/entities-results*" ] } ] } -
Pour créer la politique IAM, exécutez la commande suivante.
path/aws iam create-policy --policy-name glue-access-policy --policy-document file://path/glue-access-policy.json -
Lorsque l'ARN de la politique d'accès est AWS CLI répertorié, copiez-le et enregistrez-le dans un éditeur de texte.
-
Associez la nouvelle politique au rôle IAM en exécutant la commande suivante.
policy-arnaws iam attach-role-policy --policy-arnpolicy-arn--role-name glue-access-role -
Associez la politique AWS gérée
AWSGlueServiceRoleà votre rôle IAM en exécutant la commande suivante.aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole --role-name glue-access-role
-
-
Créez une AWS Glue base de données en exécutant la commande suivante.
aws glue create-database --database-input Name="comprehend-results" -
Créez un nouveau AWS Glue crawler en exécutant la commande suivante.
glue-iam-role-arnaws glue create-crawler --name comprehend-analysis-crawler --roleglue-iam-role-arn--targets S3Targets=[ {Path="s3://amzn-s3-demo-bucket/sentiment-results"}, {Path="s3://amzn-s3-demo-bucket/entities-results"}] --database-name comprehend-results -
Démarrez le crawler en exécutant la commande suivante.
aws glue start-crawler --name comprehend-analysis-crawlerLa fin du robot d'exploration peut prendre quelques minutes.
Préparer les données pour l'analyse
Vous disposez à présent d'une base de données contenant les résultats d'Amazon Comprehend. Cependant, les résultats sont imbriqués. Pour les désimbriquer, vous devez exécuter quelques instructions SQL dans Amazon Athena. Amazon Athena est un service de requête interactif qui facilite l'analyse des données dans Amazon S3 à l'aide du SQL standard. Athena fonctionne sans serveur, il n'y a donc aucune infrastructure à gérer et dispose d'un pay-per-query modèle de tarification. Au cours de cette étape, vous créez de nouvelles tables de données nettoyées que vous pouvez utiliser pour l'analyse et la visualisation. Vous utilisez la console Athena pour préparer les données.
Pour préparer les données
Ouvrez la console à l'adresse https://console.aws.amazon.com/athena/
. -
Dans l’éditeur de requête, choisissez Settings (Paramètres), puis Manage (Gérer).
-
Pour Emplacement des résultats de la requête, entrez
s3://amzn-s3-demo-bucket/query-results/. Cela crée un nouveau dossier appeléquery-resultsdans votre compartiment qui stocke le résultat des Amazon Athena requêtes que vous exécutez. Choisissez Save (Enregistrer). -
Dans l'éditeur de requêtes, sélectionnez Editeur.
-
Pour Base de données, choisissez la AWS Glue base de données
comprehend-resultsque vous avez créée. -
Dans la section Tables, vous devriez avoir deux tables appelées
sentiment_resultsetentities_results. Prévisualisez les tableaux pour vous assurer que le robot a chargé les données. Dans les options de chaque tableau (les trois points à côté du nom du tableau), choisissez Aperçu du tableau. Une courte requête s'exécute automatiquement. Vérifiez le volet Résultats pour vous assurer que les tables contiennent des données.Astuce
Si les tables ne contiennent aucune donnée, essayez de vérifier les dossiers de votre compartiment S3. Assurez-vous qu'il existe un dossier pour les résultats des entités et un dossier pour les résultats des sentiments. Essayez ensuite d'exécuter un nouveau AWS Glue robot d'exploration.
-
Pour désimbriquer la
sentiment_resultstable, entrez la requête suivante dans l'éditeur de requêtes et choisissez Exécuter.CREATE TABLE sentiment_results_final AS SELECT file, line, sentiment, sentimentscore.mixed AS mixed, sentimentscore.negative AS negative, sentimentscore.neutral AS neutral, sentimentscore.positive AS positive FROM sentiment_results -
Pour commencer à dénicher la table des entités, entrez la requête suivante dans l'éditeur de requêtes et choisissez Exécuter.
CREATE TABLE entities_results_1 AS SELECT file, line, nested FROM entities_results CROSS JOIN UNNEST(entities) as t(nested) -
Pour terminer la désimbrication de la table des entités, entrez la requête suivante dans l'éditeur de requêtes et choisissez Exécuter la requête.
CREATE TABLE entities_results_final AS SELECT file, line, nested.beginoffset AS beginoffset, nested.endoffset AS endoffset, nested.score AS score, nested.text AS entity, nested.type AS category FROM entities_results_1
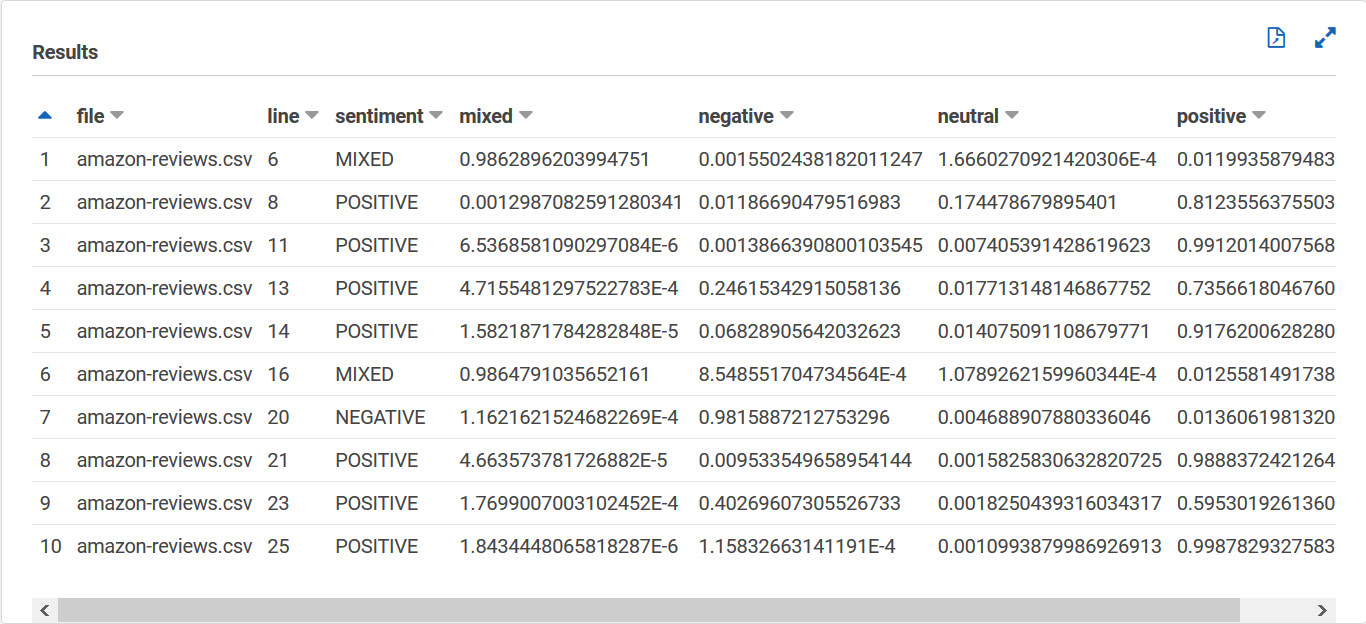
Votre sentiment_results_final tableau doit ressembler à ce qui suit, avec des colonnes nommées fichier, ligne, sentiment, mixte, négatif, neutre et positif. Le tableau doit comporter une valeur par cellule. La colonne des sentiments décrit le sentiment général le plus probable à l'égard d'un avis donné. Les colonnes mixtes, négatives, neutres et positives donnent des scores pour chaque type de sentiment.
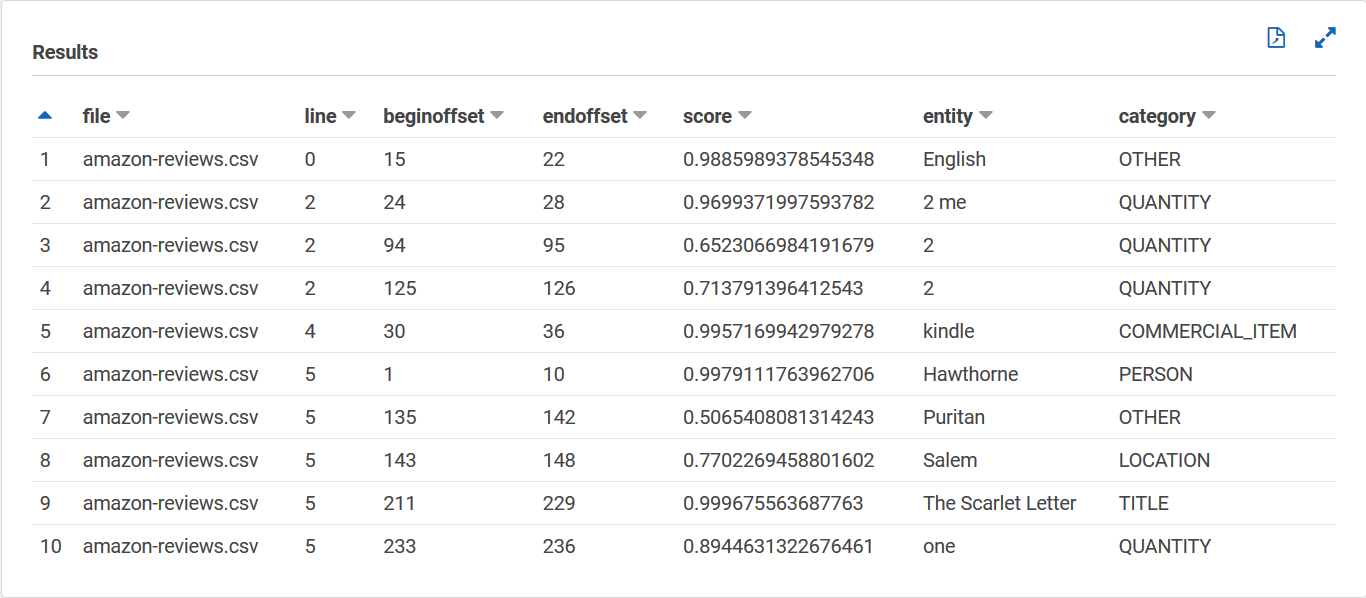
Votre entities_results_final tableau doit ressembler à ce qui suit, avec des colonnes nommées file, line, beginoffset, endoffset, score, entity et category. Le tableau doit comporter une valeur par cellule. La colonne de score indique la confiance d'Amazon Comprehend dans l'entité détectée. La catégorie indique le type d'entité détecté par Comprehend.
Maintenant que les résultats d'Amazon Comprehend sont chargés dans des tableaux, vous pouvez visualiser et extraire des informations pertinentes à partir des données.
