Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utiliser Babelfish comme cible pour AWS Database Migration Service
Vous pouvez migrer les données d'une base de données source Microsoft SQL Server vers une cible Babelfish à l'aide de. AWS Database Migration Service
Babelfish pour Aurora PostgreSQL étend l'Édition compatible avec PostgreSQL de votre base de données Amazon Aurora et permet d'accepter les connexions de base de données à partir de clients Microsoft SQL Server. Les applications initialement conçues pour SQL Server peuvent ainsi être utilisées avec Aurora PostgreSQL, sans apporter de changements significatifs au code par rapport à une migration traditionnelle et sans modifier les pilotes de base de données.
Pour plus d'informations sur les versions de Babelfish compatibles AWS DMS en tant que cible, consultez. Objectifs pour AWS DMS Les versions antérieures de Babelfish sur Aurora PostgreSQL nécessitent une mise à niveau avant d’utiliser le point de terminaison Babelfish.
Note
Le point de terminaison cible Aurora PostgreSQL est la méthode privilégiée pour migrer des données vers Babelfish. Pour de plus amples informations, veuillez consulter Utilisation de Babelfish for Aurora PostgreSQL en tant que cible.
Pour en savoir plus sur l’utilisation de Babelfish comme point de terminaison de base de données, consultez Babelfish for Aurora PostgreSQL dans le Guide de l’utilisateur Amazon Aurora pour Aurora.
Prérequis pour utiliser Babelfish comme cible pour AWS DMS
Vous devez créer vos tables avant de migrer les données afin de vous assurer que celles-ci AWS DMS utilisent les types de données et les métadonnées de table appropriés. Si vous ne créez pas vos tables sur la cible avant d'exécuter la migration, vous AWS DMS risquez de créer les tables avec des types de données et des autorisations incorrects. Par exemple, AWS DMS crée une colonne d'horodatage au format binaire (8) à la place et ne fournit pas les fonctionnalités attendues timestamp/rowversion .
Pour préparer et créer vos tables avant la migration
-
Exécutez vos instructions DDL de création de table qui incluent des contraintes uniques, des clés primaires ou des contraintes par défaut.
N’incluez pas de contraintes de clé étrangère ni d’instructions DDL pour des objets tels que des vues, des procédures stockées, des fonctions ou des déclencheurs. Vous pouvez les appliquer après avoir migré la base de données source.
-
Identifiez les colonnes d’identité, les colonnes calculées ou les colonnes contenant des types de données rowversion ou timestamp pour vos tables. Créez ensuite les règles de transformation nécessaires pour gérer les problèmes connus lors de l’exécution de la tâche de migration. Pour plus d'informations, voir Règles et actions de transformation.
-
Identifiez les colonnes contenant des types de données que Babelfish ne prend pas en charge. Modifiez ensuite les colonnes concernées dans la table cible pour utiliser les types de données pris en charge, ou créez une règle de transformation qui les supprime lors de la tâche de migration. Pour plus d'informations, voir Règles et actions de transformation.
Le tableau suivant répertorie les types de données source non pris en charge par Babelfish, ainsi que le type de données cible recommandé correspondant à utiliser.
Type de données source
Type de données Babelfish recommandé
HEIRARCHYID
NVARCHAR(250)
GEOMETRY
VARCHAR(MAX)
GEOGRAPHY
VARCHAR(MAX)
Pour définir le niveau des unités de capacité Aurora (ACUs) pour votre base de données source Aurora PostgreSQL Serverless V2
Vous pouvez améliorer les performances de votre tâche de AWS DMS migration avant de l'exécuter en définissant la valeur ACU minimale.
-
Dans la fenêtre des paramètres de capacité de Severless v2, définissez un niveau minimum ACUs de
2ou un niveau raisonnable pour votre cluster de base de données Aurora.Pour plus d’informations sur la définition des unités de capacité Aurora, consultez Choix de la plage de capacité Aurora sans serveur v2 pour un cluster Aurora dans le Guide de l’utilisateur Amazon Aurora.
Après avoir exécuté votre tâche de AWS DMS migration, vous pouvez rétablir la valeur minimale de votre base ACUs de données source Aurora PostgreSQL Serverless V2 à un niveau raisonnable.
Exigences de sécurité lors de l'utilisation de Babelfish comme cible pour AWS Database Migration Service
Ce qui suit décrit les exigences de sécurité pour une utilisation AWS DMS avec une cible Babelfish :
-
Le nom d’utilisateur de l’administrateur (utilisateur Admin) utilisé pour créer la base de données.
-
L’identifiant de connexion PSQL et l’utilisateur disposant des autorisations SELECT, INSERT, UPDATE, DELETE et REFERENCES suffisantes.
Autorisations utilisateur pour utiliser Babelfish comme cible pour AWS DMS
Important
À des fins de sécurité, le compte d’utilisateur utilisé pour la migration des données doit être un utilisateur enregistré dans une base de données Babelfish que vous utilisez en tant que cible.
Votre point de terminaison cible Babelfish nécessite des autorisations utilisateur minimales pour exécuter une migration AWS DMS .
Pour créer un identifiant de connexion et un utilisateur Transact-SQL (T-SQL) à faible privilège
-
Créez un identifiant de connexion et un mot de passe à utiliser lors de la connexion au serveur.
CREATE LOGIN dms_user WITH PASSWORD ='password'; GO -
Créez la base de données virtuelle pour votre cluster Babelfish.
CREATE DATABASE my_database; GO -
Créez l’utilisateur T-SQL pour la base de données cible.
USE my_database GO CREATE USER dms_user FOR LOGIN dms_user; GO -
Pour chaque table de la base de données Babelfish, accordez (GRANT) des autorisations aux tables.
GRANT SELECT, DELETE, INSERT, REFERENCES, UPDATE ON [dbo].[Categories] TO dms_user;
Limitations relatives à l'utilisation de Babelfish comme cible pour AWS Database Migration Service
Les limitations suivantes s’appliquent lors de l’utilisation d’une base de données Babelfish en tant que cible pour AWS DMS :
-
Seul le mode de préparation de table « Ne rien faire » est pris en charge.
-
Le type de données ROWVERSION nécessite une règle de mappage de table qui supprime le nom de colonne de la table pendant la tâche de migration.
-
Le type de données sql_variant n’est pas pris en charge.
-
Le mode LOB complet est pris en charge. L'utilisation de SQL Server comme point de terminaison source nécessite que le paramètre
ForceFullLob=Trued'attribut de connexion du point de terminaison SQL Server soit défini afin de LOBs pouvoir être migré vers le point de terminaison cible. -
Les paramètres de la tâche de réplication présentent les limitations suivantes :
{ "FullLoadSettings": { "TargetTablePrepMode": "DO_NOTHING", "CreatePkAfterFullLoad": false, }. } -
Les types de données TIME DATETIME2 (7), (7) et DATETIMEOFFSET (7) dans Babelfish limitent la valeur de précision pour la partie secondes du temps à 6 chiffres. Envisagez d’utiliser une valeur de précision de 6 pour votre table cible lorsque vous utilisez ces types de données. Pour les versions 2.2.0 et supérieures de Babelfish, lorsque vous utilisez TIME (7) et DATETIME2 (7), le septième chiffre de précision est toujours zéro.
-
En mode DO_NOTHING, DMS vérifie si la table existe déjà. Si la table n’existe pas dans le schéma cible, DMS crée la table en fonction de la définition de table source et mappe tous les types de données définis par l’utilisateur à leur type de données de base.
-
Une tâche de AWS DMS migration vers une cible Babelfish ne prend pas en charge les tables dont les colonnes utilisent les types de données ROWVERSION ou TIMESTAMP. Vous pouvez utiliser une règle de mappage de table qui supprime le nom de colonne de la table pendant le processus de transfert. Dans l’exemple de règle de transformation suivant, une table nommée
Actordans votre source est transformée pour supprimer toutes les colonnes commençant par les caractèrescolde la tableActordans votre cible.{ "rules": [{ "rule-type": "selection",is "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "remove-column", "rule-target": "column", "object-locator": { "schema-name": "test", "table-name": "Actor", "column-name": "col%" } }] } -
Pour les tables comportant des colonnes d’identité ou calculées, où les tables cibles utilisent des noms en casse mixte tels que Catégories, vous devez créer une action de règle de transformation qui convertit les noms des table en minuscules pour votre tâche DMS. L'exemple suivant montre comment créer l'action de règle de transformation Make lowercase à l'aide de la AWS DMS console. Pour de plus amples informations, veuillez consulter Règles et actions de transformation.
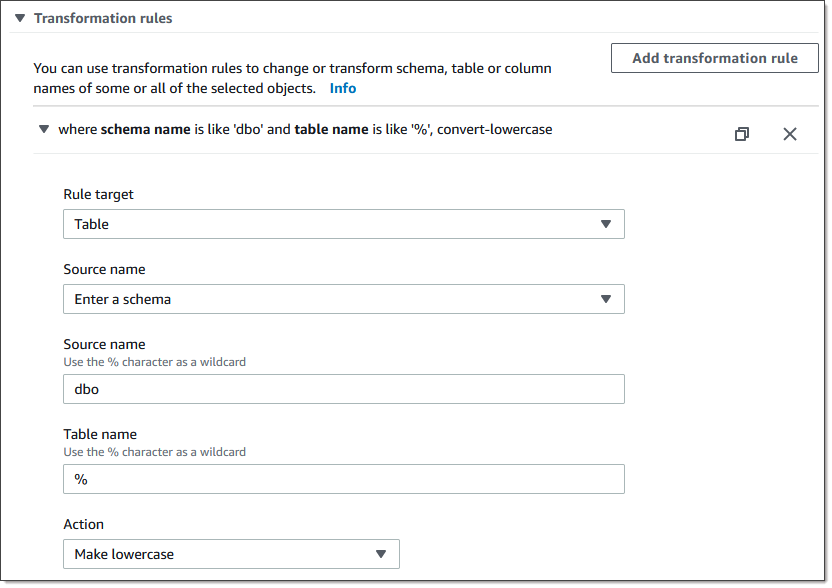
-
Avant Babelfish version 2.2.0, DMS limitait le nombre de colonnes que vous pouviez répliquer vers un point de terminaison cible Babelfish à vingt (20) colonnes. Avec Babelfish 2.2.0, la limite est passée à 100 colonnes. Mais avec Babelfish versions 2.4.0 et ultérieures, le nombre de colonnes que vous pouvez répliquer augmente à nouveau. Vous pouvez exécuter l’exemple de code suivant sur la base de données SQL Server pour déterminer quelles tables sont trop longues.
USE myDB; GO DECLARE @Babelfish_version_string_limit INT = 8000; -- Use 380 for Babelfish versions before 2.2.0 WITH bfendpoint AS ( SELECT [TABLE_SCHEMA] ,[TABLE_NAME] , COUNT( [COLUMN_NAME] ) AS NumberColumns , ( SUM( LEN( [COLUMN_NAME] ) + 3) + SUM( LEN( FORMAT(ORDINAL_POSITION, 'N0') ) + 3 ) + LEN( TABLE_SCHEMA ) + 3 + 12 -- INSERT INTO string + 12) AS InsertIntoCommandLength -- values string , CASE WHEN ( SUM( LEN( [COLUMN_NAME] ) + 3) + SUM( LEN( FORMAT(ORDINAL_POSITION, 'N0') ) + 3 ) + LEN( TABLE_SCHEMA ) + 3 + 12 -- INSERT INTO string + 12) -- values string >= @Babelfish_version_string_limit THEN 1 ELSE 0 END AS IsTooLong FROM [INFORMATION_SCHEMA].[COLUMNS] GROUP BY [TABLE_SCHEMA], [TABLE_NAME] ) SELECT * FROM bfendpoint WHERE IsTooLong = 1 ORDER BY TABLE_SCHEMA, InsertIntoCommandLength DESC, TABLE_NAME ;
Types de données cibles pour Babelfish
Le tableau suivant indique les types de données cibles de Babelfish pris en charge lors de l'utilisation AWS DMS et le mappage par défaut à partir AWS DMS des types de données.
Pour plus d'informations sur AWS DMS les types de données, consultezTypes de données pour AWS Database Migration Service.
|
AWS DMS type de données |
Type de données Babelfish |
|---|---|
|
BOOLEAN |
TINYINT |
|
BYTES |
VARBINARY(Length) |
|
DATE |
DATE |
|
TIME |
TIME |
|
INT1 |
SMALLINT |
|
INT2 |
SMALLINT |
|
INT4 |
INT |
|
INT8 |
BIGINT |
|
NUMERIC |
NUMERIC(p,s) |
|
REAL4 |
REAL |
|
REAL8 |
FLOAT |
|
CHAÎNE |
Si la colonne est une colonne de date ou d'heure, effectuez les opérations suivantes :
Si la colonne n'est pas une colonne de date ou d'heure, utilisez VARCHAR (length). |
|
UINT1 |
TINYINT |
|
UINT2 |
SMALLINT |
|
UINT4 |
INT |
|
UINT8 |
BIGINT |
|
WSTRING |
NVARCHAR(length) |
|
BLOB |
VARBINARY(max) Pour utiliser ce type de données avec DMS, vous devez activer l'utilisation de BLOBs pour une tâche spécifique. DMS prend en charge les types de données BLOB uniquement dans les tables qui contiennent une clé primaire. |
|
CLOB |
VARCHAR(max) Pour utiliser ce type de données avec DMS, vous devez activer l'utilisation de CLOBs pour une tâche spécifique. |
|
NCLOB |
NVARCHAR(max) Pour utiliser ce type de données avec DMS, vous devez activer l'utilisation de NCLOBs pour une tâche spécifique. Au cours de la CDC, DMS prend en charge les types de données NCLOB uniquement dans les tables qui contiennent une clé primaire. |
