Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d’une base de données Amazon DynamoDB en tant que cible pour AWS Database Migration Service
Vous pouvez l'utiliser AWS DMS pour migrer des données vers une table Amazon DynamoDB. Amazon DynamoDB est un service de base de données NoSQL entièrement géré qui fournit des performances rapides et prévisibles avec une évolutivité sans faille. AWS DMS prend en charge l'utilisation d'une base de données relationnelle ou de MongoDB comme source.
Dans DynamoDB, les tables, les éléments et les attributs sont les principaux composants que vous utilisez. Une table est une collection d’éléments et chaque élément est une collection d’attributs. DynamoDB utilise les clés primaires, appelées clés de partition, afin d'identifier de façon unique chaque élément d'une table. Vous pouvez également utiliser des clés et des index secondaires pour fournir une plus grande flexibilité d'interrogation.
Vous utilisez le mappage d'objet afin de migrer vos données d'une base de données source vers une table DynamoDB cible. Le mappage d'objet vous permet de déterminer l'emplacement des données sources dans la cible.
Lors de la AWS DMS création de tables sur un point de terminaison cible DynamoDB, il crée autant de tables que dans le point de terminaison de la base de données source. AWS DMS définit également plusieurs valeurs de paramètres DynamoDB. Le coût de création de la table dépend de la quantité de données et du nombre de tables à migrer.
Note
L'option Mode SSL de la AWS DMS console ou de l'API ne s'applique pas à certains services de streaming de données et NoSQL tels que Kinesis et DynamoDB. Ils sont sécurisés par défaut, ce qui AWS DMS montre que le paramètre du mode SSL est égal à aucun (mode SSL = aucun). Vous n’avez pas besoin de fournir de configuration supplémentaire pour que votre point de terminaison utilise le protocole SSL. Par exemple, lorsque DynamoDB est utilisé comme point de terminaison cible, il est sécurisé par défaut. Tous les appels d'API à DynamoDB utilisent le protocole SSL, il n'est donc pas nécessaire d'ajouter une option SSL supplémentaire dans le point de terminaison. AWS DMS Vous pouvez placer et récupérer des données en toute sécurité via des points de terminaison SSL à l’aide du protocole HTTPS, utilisé par AWS DMS par défaut lors de la connexion à une base de données DynamoDB.
Pour accélérer le transfert, AWS DMS prend en charge le chargement complet multithread vers une instance cible DynamoDB. DMS prend en charge ce traitement multithread avec des paramètres de tâche, notamment les suivants :
-
MaxFullLoadSubTasks: utilisez cette option pour indiquer le nombre maximal de tables sources à charger en parallèle. DMS charge chaque table dans sa table cible DynamoDB correspondante à l’aide d’une sous-tâche dédiée. La valeur par défaut est 8. La valeur maximale est 49. -
ParallelLoadThreads— Utilisez cette option pour spécifier le nombre de threads AWS DMS utilisés pour charger chaque table dans sa table cible DynamoDB. La valeur par défaut est 0 (à thread unique). La valeur maximale est 200. Vous pouvez demander une augmentation de cette limite maximale.Note
DMS attribue chaque segment d'une table à son propre thread pour le chargement. Par conséquent, définissez
ParallelLoadThreadssur le nombre maximal de segments que vous spécifiez pour une table de la source. -
ParallelLoadBufferSize: utilisez cette option pour spécifier le nombre maximal d’enregistrements à stocker dans la mémoire tampon utilisée par les threads de chargement parallèles pour charger les données dans la cible DynamoDB. La valeur par défaut est 50. La valeur maximale est 1 000. Utilisez ce paramètre avecParallelLoadThreads.ParallelLoadBufferSizeest valide uniquement dans le cas de plusieurs threads. -
Paramètres de mappage de table pour des tables individuelles : utilisez des règles
table-settingspour identifier les tables individuelles de la source que vous souhaitez charger en parallèle. Utilisez également ces règles pour spécifier comment segmenter les lignes de chaque table pour le chargement multithread. Pour de plus amples informations, veuillez consulter Règles des paramètres de table et de collection et opérations.
Note
Lorsque AWS DMS les valeurs des paramètres DynamoDB sont définies pour une tâche de migration, la valeur du paramètre Unités de capacité de lecture (RCU) par défaut est définie sur 200.
La valeur du paramètre WCU (Write Capacity Units) est également définie, mais sa valeur dépend de plusieurs autres paramètres :
-
La valeur par défaut du paramètre WCU est 200.
-
Si le paramètre de tâche
ParallelLoadThreadsest défini sur une valeur supérieure à 1 (0 par défaut), le paramètre WCU est défini à 200 fois la valeurParallelLoadThreads. Les frais AWS DMS d'utilisation standard s'appliquent aux ressources que vous utilisez.
Migration à partir d’une base de données relationnelle vers une table DynamoDB
AWS DMS prend en charge la migration des données vers les types de données scalaires DynamoDB. Lors d'une migration depuis une base de données relationnelle telle qu'Oracle ou MySQL vers DynamoDB, vous pouvez restructurer la manière dont vous stockez les données.
AWS DMS Prend actuellement en charge la restructuration d'une table à une autre selon les attributs de type scalaire DynamoDB. Si vous migrez des données vers DynamoDB depuis une table de base de données relationnelle, vous prenez les données d'une table et les reformatez en attributs de types de données scalaires DynamoDB. Ces attributs peuvent accepter des données de plusieurs colonnes et vous pouvez mapper directement une colonne à un attribut.
AWS DMS prend en charge les types de données scalaires DynamoDB suivants :
-
Chaîne
-
Nombre
-
Booléen
Note
Les données NULL provenant de la source sont ignorées dans la cible.
Conditions préalables à l'utilisation de DynamoDB comme cible pour AWS Database Migration Service
Avant de commencer à utiliser une base de données DynamoDB comme cible, assurez-vous AWS DMS de créer un rôle IAM. Ce rôle IAM doit permettre d'assumer et AWS DMS d'accorder l'accès aux tables DynamoDB vers lesquelles la migration est en cours de migration. L'ensemble d'autorisations d'accès minimum est indiqué dans la stratégie IAM suivante.
Le rôle que vous utilisez pour la migration vers DynamoDB doit bénéficier des autorisations suivantes.
Limitations liées à l'utilisation de DynamoDB comme cible pour AWS Database Migration Service
Les limitations suivantes s’appliquent à l’utilisation de DynamoDB en tant que cible :
-
DynamoDB limite la précision du type de données Number à 38 places. Stockez tous les types de données en tant que chaîne avec une meilleure précision. Vous devez le spécifier explicitement à l'aide de la fonction de mappage d'objet.
-
Étant donné que DynamoDB ne possède pas de type de données Date, les données utilisant le type de données Date sont converties en chaînes.
-
DynamoDB n’autorise pas les mises à jour des attributs de la clé primaire. Cette restriction est importante lors de l'utilisation de la réplication continue avec la capture des données modifiées (CDC), car elle peut entraîner des données non souhaitées dans la cible. En fonction de la façon dont l'objet est mappé, une opération CDC qui met à jour la clé primaire peut réaliser l'une des deux actions suivantes. Elle peut échouer ou insérer un nouvel élément avec la clé primaire mise à jour et des données incomplètes.
-
AWS DMS prend uniquement en charge la réplication de tables avec des clés primaires non composites. Une exception s'applique si vous spécifiez un mappage d'objet pour la table cible avec une clé de partition ou une clé de tri personnalisée, ou les deux.
-
AWS DMS ne prend pas en charge les données LOB sauf s'il s'agit d'un CLOB. AWS DMS convertit les données CLOB en chaîne DynamoDB lors de la migration des données.
-
Lorsque vous utilisez DynamoDB comme cible, seule la table de contrôle Appliquer les exceptions (
dmslogs.awsdms_apply_exceptions) est prise en charge. Pour plus d'informations sur les tables de contrôle, consultez Paramètres de tâche de la table de contrôle. AWS DMS ne prend pas en charge le paramétrage des tâches
TargetTablePrepMode=TRUNCATE_BEFORE_LOADpour DynamoDB en tant que cible.AWS DMS ne prend pas en charge le paramétrage des tâches
TaskRecoveryTableEnabledpour DynamoDB en tant que cible.BatchApplyn'est pas pris en charge pour un point de terminaison DynamoDB.-
AWS DMS Impossible de migrer les attributs dont les noms correspondent à des mots réservés dans DynamoDB. Pour plus d'informations, consultez la section Mots réservés dans DynamoDB dans le manuel du développeur Amazon DynamoDB.
Utilisation du mappage d’objet pour migrer les données vers DynamoDB
AWS DMS utilise des règles de mappage de tables pour mapper les données de la source à la table DynamoDB cible. Pour mapper des données vers une cible DynamoDB, utilisez un type de règle de mappage de tables dénommé object-mapping. Le mappage d'objet vous permet de définir le nom des attributs et les données qui doivent être migrées vers ceux-ci. Des règles de sélection doivent être définies lorsque vous utilisez le mappage d'objet.
DynamoDB ne dispose pas d’une structure prédéfinie autre qu’une clé de partition et une clé de tri facultative. Si vous avez une clé primaire non composite, AWS DMS utilisez-la. Si vous avez une clé primaire composite ou si vous souhaitez utiliser une clé de tri, définissez ces clés et les autres attributs dans votre table DynamoDB cible.
Pour créer une règle de mappage d'objet, vous spécifiez le rule-type comme mappage d'objet. Cette règle spécifie le type de mappage d'objet que vous souhaitez utiliser.
La structure de la règle est la suivante :
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "<id>", "rule-name": "<name>", "rule-action": "<valid object-mapping rule action>", "object-locator": { "schema-name": "<case-sensitive schema name>", "table-name": "" }, "target-table-name": "<table_name>" } ] }
AWS DMS prend actuellement en charge map-record-to-record et map-record-to-document en tant que seules valeurs valides pour le rule-action paramètre. Ces valeurs indiquent ce qui est AWS DMS fait par défaut aux enregistrements qui ne sont pas exclus de la liste d'exclude-columnsattributs. Ces valeurs n'affectent en aucune façon les mappages d'attributs.
-
Vous pouvez utiliser
map-record-to-recordlors de la migration d’une base de données relationnelle vers DynamoDB. La clé primaire est utilisée depuis la base de données relationnelle comme clé de partition dans DynamoDB et crée un attribut pour chaque colonne dans la base de données source. Lors de l'utilisationmap-record-to-record, pour toute colonne de la table source non répertoriée dans la listeexclude-columnsd'attributs, AWS DMS crée un attribut correspondant sur l'instance DynamoDB cible. Cet attribut est créé, que la colonne source soit ou non utilisée dans un mappage d'attribut. -
Vous utilisez
map-record-to-documentpour placer des colonnes sources dans un mappage DynamoDB unique et plat sur la cible, avec le nom d’attribut « _doc ». Lors de l'utilisationmap-record-to-document, AWS DMS place les données dans un attribut cartographique DynamoDB unique et plat sur la source. Cet attribut est appelé « _doc ». Ce placement s'applique à toute colonne de la table source non listée dans la liste d'attributsexclude-columns.
Une des manières de comprendre la différence entre les paramètres rule-action map-record-to-record et map-record-to-document consiste à voir les deux paramètres en action. Dans cet exemple, imaginons que vous commencez avec une ligne de table d'une base de données relationnelle, présentant la structure et les données suivantes :

Pour migrer ces informations vers DynamoDB, vous créez des règles pour mapper les données dans un élément de la table DynamoDB. Notez les colonnes listées pour le paramètre exclude-columns. Ces colonnes ne sont pas directement mappées à la cible. Le mappage d'attributs est plutôt utilisé pour combiner les données dans de nouveaux éléments, tels que where FirstNameet LastNamesont regroupés pour figurer CustomerNamesur la cible DynamoDB. NickNameet les revenus ne sont pas exclus.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
À l'aide de rule-action ce paramètre map-record-to-record, les données NickNameet les revenus sont mappés aux éléments du même nom dans la cible DynamoDB.
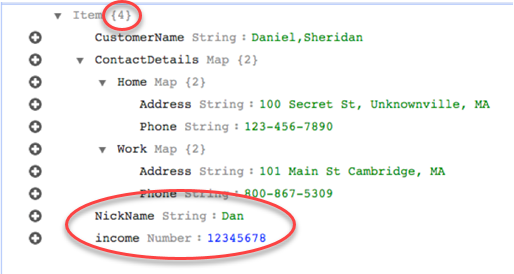
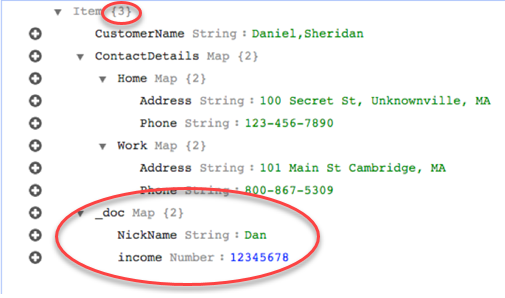
Supposons toutefois que vous utilisiez les mêmes règles mais que vous modifiiez le rule-action paramètre en map-record-to-document. Dans ce cas, les colonnes non répertoriées dans le exclude-columns paramètre, NickNameet le revenu, sont mappées à un élément _doc.
Utilisation d'expressions de condition personnalisées avec le mappage d'objet
Vous pouvez utiliser une fonctionnalité de DynamoDB nommée « expressions conditionnelles » pour manipuler les données qui sont écrites dans une table DynamoDB. Pour plus d’informations sur les expressions de condition dans DynamoDB, consultez Expressions de condition.
Une expression de condition est constituée des éléments suivants :
-
une expression (obligatoire)
-
des valeurs d'attributs d'expressions (facultatif). Spécifie une structure DynamoDB json de la valeur de l'attribut
-
des noms d'attributs d'expressions (facultatif)
-
options pour déterminer quand utiliser l'expression de condition (facultatif). La valeur par défaut est apply-during-cdc = false et apply-during-full-load = true
La structure de la règle est la suivante :
"target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "condition-expression": { "expression":"<conditional expression>", "expression-attribute-values": [ { "name":"<attribute name>", "value":<attribute value> } ], "apply-during-cdc":<optional Boolean value>, "apply-during-full-load": <optional Boolean value> }
L'exemple suivant illustre les sections utilisées pour l'expression de condition.

Utilisation du mappage d'attribut avec le mappage d'objet
La mappage d'attribut vous permet de spécifier une chaîne modèle, en utilisant les noms de la colonne source pour restructurer les données sur la cible. Aucun formatage n'est effectué, autre que ce qui est spécifié par l'utilisateur dans le modèle.
L'exemple suivant illustre la structure de la base de données source et la structure de cible DynamoDB souhaitée. La structure de la source est illustrée en premier, dans ce cas, une base de données Oracle, puis la structure souhaitée des données dans DynamoDB. L'exemple se termine avec le JSON utilisé pour créer la structure cible souhaitée.
La structure des données Oracle est la suivante :
| FirstName | LastName | StoreId | HomeAddress | HomePhone | WorkAddress | WorkPhone | DateOfBirth |
|---|---|---|---|---|---|---|---|
| Clé primaire | N/A | ||||||
| Randy | Marsh | 5 | 221B Baker Street | 1234567890 | 31 Spooner Street, Quahog | 9876543210 | 02/29/1988 |
La structure des données DynamoDB est la suivante :
| CustomerName | StoreId | ContactDetails | DateOfBirth |
|---|---|---|---|
| Clé de partition | Clé de tri | N/A | |
|
|
|
|
Le JSON suivant illustre le mappage d'objet et le mappage de colonne utilisés pour parvenir à la structure DynamoDB :
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "{\"Name\":\"${FirstName}\",\"Home\":{\"Address\":\"${HomeAddress}\",\"Phone\":\"${HomePhone}\"}, \"Work\":{\"Address\":\"${WorkAddress}\",\"Phone\":\"${WorkPhone}\"}}" } ] } } ] }
Une autre façon d'utiliser le mappage de colonne consiste à utiliser le format DynamoDB comme type de document. L'exemple de code suivant utilise dynamodb-map comme attribute-sub-type pour la mappage d'attribut.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Name": { "S": "${FirstName}" }, "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
Au lieu de celadynamodb-map, vous pouvez utiliser le mappage d'attributs dynamodb-list as attribute-sub-type for, comme indiqué dans l'exemple suivant.
{ "target-attribute-name": "ContactDetailsList", "attribute-type": "document", "attribute-sub-type": "dynamodb-list", "value": { "L": [ { "N": "${FirstName}" }, { "N": "${HomeAddress}" }, { "N": "${HomePhone}" }, { "N": "${WorkAddress}" }, { "N": "${WorkPhone}" } ] } }
Exemple 1 : utilisation du mappage d'attribut avec le mappage d'objet
L'exemple suivant fait migrer les données de deux tables de base de données MySQL, nfl_data et sport_team, vers deux tables DynamoDB appelées et. NFLTeamsSportTeams La structure des tables et le JSON utilisés pour mapper les données depuis les tables de base de données MySQL vers les tables DynamoDB sont les suivants :
La structure de la table de base de données MySQL nfl_data est indiquée ci-dessous :
mysql> desc nfl_data; +---------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+-------+ | Position | varchar(5) | YES | | NULL | | | player_number | smallint(6) | YES | | NULL | | | Name | varchar(40) | YES | | NULL | | | status | varchar(10) | YES | | NULL | | | stat1 | varchar(10) | YES | | NULL | | | stat1_val | varchar(10) | YES | | NULL | | | stat2 | varchar(10) | YES | | NULL | | | stat2_val | varchar(10) | YES | | NULL | | | stat3 | varchar(10) | YES | | NULL | | | stat3_val | varchar(10) | YES | | NULL | | | stat4 | varchar(10) | YES | | NULL | | | stat4_val | varchar(10) | YES | | NULL | | | team | varchar(10) | YES | | NULL | | +---------------+-------------+------+-----+---------+-------+
La structure de la table de base de données MySQL sport_team est indiquée ci-dessous :
mysql> desc sport_team; +---------------------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------------------+--------------+------+-----+---------+----------------+ | id | mediumint(9) | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | NULL | | | abbreviated_name | varchar(10) | YES | | NULL | | | home_field_id | smallint(6) | YES | MUL | NULL | | | sport_type_name | varchar(15) | NO | MUL | NULL | | | sport_league_short_name | varchar(10) | NO | | NULL | | | sport_division_short_name | varchar(10) | YES | | NULL | |
Les règles de mappage de table utilisées pour mapper les deux tables vers les deux tables DynamoDB sont indiquées ci-dessous :
{ "rules":[ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "dms_sample", "table-name": "nfl_data" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "dms_sample", "table-name": "sport_team" }, "rule-action": "include" }, { "rule-type":"object-mapping", "rule-id":"3", "rule-name":"MapNFLData", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"nfl_data" }, "target-table-name":"NFLTeams", "mapping-parameters":{ "partition-key-name":"Team", "sort-key-name":"PlayerName", "exclude-columns": [ "player_number", "team", "name" ], "attribute-mappings":[ { "target-attribute-name":"Team", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${team}" }, { "target-attribute-name":"PlayerName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"PlayerInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"Number\": \"${player_number}\",\"Position\": \"${Position}\",\"Status\": \"${status}\",\"Stats\": {\"Stat1\": \"${stat1}:${stat1_val}\",\"Stat2\": \"${stat2}:${stat2_val}\",\"Stat3\": \"${stat3}:${ stat3_val}\",\"Stat4\": \"${stat4}:${stat4_val}\"}" } ] } }, { "rule-type":"object-mapping", "rule-id":"4", "rule-name":"MapSportTeam", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"sport_team" }, "target-table-name":"SportTeams", "mapping-parameters":{ "partition-key-name":"TeamName", "exclude-columns": [ "name", "id" ], "attribute-mappings":[ { "target-attribute-name":"TeamName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"TeamInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"League\": \"${sport_league_short_name}\",\"Division\": \"${sport_division_short_name}\"}" } ] } } ] }
L'exemple de sortie pour la table NFLTeamsDynamoDB est illustré ci-dessous :
"PlayerInfo": "{\"Number\": \"6\",\"Position\": \"P\",\"Status\": \"ACT\",\"Stats\": {\"Stat1\": \"PUNTS:73\",\"Stat2\": \"AVG:46\",\"Stat3\": \"LNG:67\",\"Stat4\": \"IN 20:31\"}", "PlayerName": "Allen, Ryan", "Position": "P", "stat1": "PUNTS", "stat1_val": "73", "stat2": "AVG", "stat2_val": "46", "stat3": "LNG", "stat3_val": "67", "stat4": "IN 20", "stat4_val": "31", "status": "ACT", "Team": "NE" }
L'exemple de sortie pour la table SportsTeams DynamoDB est illustré ci-dessous :
{ "abbreviated_name": "IND", "home_field_id": 53, "sport_division_short_name": "AFC South", "sport_league_short_name": "NFL", "sport_type_name": "football", "TeamInfo": "{\"League\": \"NFL\",\"Division\": \"AFC South\"}", "TeamName": "Indianapolis Colts" }
Types de données cibles pour DynamoDB
Le point de terminaison DynamoDB pour AWS DMS prend en charge la plupart des types de données DynamoDB. Le tableau suivant indique les types de données AWS DMS cibles Amazon pris en charge lors de l'utilisation AWS DMS et le mappage par défaut à partir AWS DMS des types de données.
Pour plus d'informations sur AWS DMS les types de données, consultezTypes de données pour AWS Database Migration Service.
Lors de AWS DMS la migration de données à partir de bases de données hétérogènes, nous mappons les types de données de la base de données source à des types de données intermédiaires appelés types de AWS DMS données. Nous mappons ensuite les types de données intermédiaires vers les types de données cibles. Le tableau suivant indique chaque type de AWS DMS données et le type de données auquel il correspond dans DynamoDB :
| AWS DMS type de données | Type de données DynamoDB |
|---|---|
|
Chaîne |
Chaîne |
|
WString |
Chaîne |
|
Booléen |
Booléen |
|
Date |
Chaîne |
|
DateTime |
Chaîne |
|
INT1 |
Nombre |
|
INT2 |
Nombre |
|
INT4 |
Nombre |
|
INT8 |
Nombre |
|
Numérique |
Nombre |
|
Real4 |
Nombre |
|
Real8 |
Nombre |
|
UINT1 |
Nombre |
|
UINT2 |
Nombre |
|
UINT4 |
Nombre |
| UINT8 | Nombre |
| CLOB | Chaîne |
