Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Amazon DocumentDB : comment ça marche
Amazon DocumentDB (compatible avec MongoDB) est un service de base de données entièrement géré et compatible avec MongoDB. Avec Amazon DocumentDB, vous pouvez exécuter le même code d'application et utiliser les mêmes pilotes et outils que ceux que vous utilisez avec MongoDB. Amazon DocumentDB est compatible avec MongoDB 3.6, 4.0 et 5.0.
Rubriques
Lorsque vous utilisez Amazon DocumentDB, vous commencez par créer un cluster. Un cluster de bases de données se compose de zéro ou plusieurs instances de bases de données, et d'un volume de cluster qui gère les données de ces instances. Un volume de cluster Amazon DocumentDB est un volume de stockage de base de données virtuelle qui couvre plusieurs zones de disponibilité. Chaque zone de disponibilité possède une copie des données du cluster.
Un cluster Amazon DocumentDB se compose de deux composants :
-
Volume du cluster : utilise un service de stockage cloud natif pour répliquer les données de six manières sur trois zones de disponibilité, fournissant ainsi un stockage hautement durable et disponible. Un cluster Amazon DocumentDB possède exactement un volume de cluster, qui peut stocker jusqu'à 128 TiB de données.
-
Instances : fournissent la puissance de traitement de la base de données, en écrivant des données sur le volume de stockage du cluster et en lisant des données à partir de celui-ci. Un cluster Amazon DocumentDB peut comporter de 0 à 16 instances.
Les instances jouent l'un de ces deux rôles :
-
Instance principale : prend en charge les opérations de lecture et d'écriture et effectue toutes les modifications de données sur le volume du cluster. Chaque cluster Amazon DocumentDB possède une instance principale.
-
Instance de réplication : prend en charge uniquement les opérations de lecture. Un cluster Amazon DocumentDB peut contenir jusqu'à 15 répliques en plus de l'instance principale. Le fait de posséder plusieurs réplicas vous permet de répartir les charges de travail en lecture. En outre, en plaçant les réplicas dans des zones de disponibilité distinctes, vous pouvez aussi accroître la disponibilité de votre cluster.
Le schéma suivant illustre la relation entre le volume du cluster, l'instance principale et les répliques dans un cluster Amazon DocumentDB :
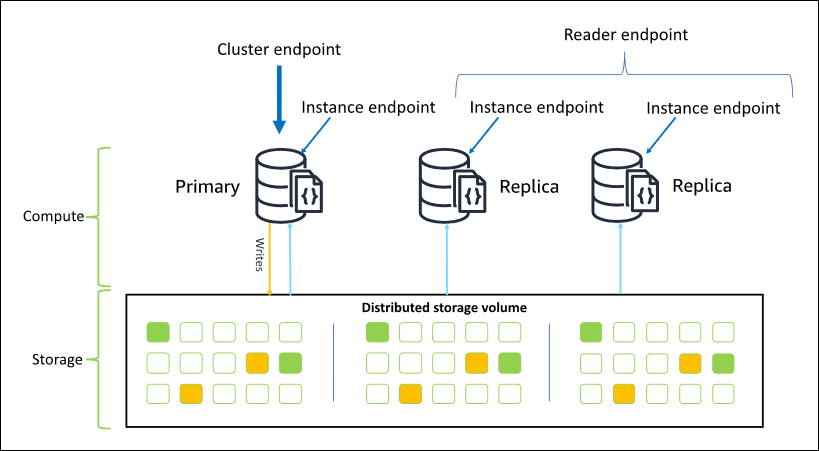
Les instances de cluster n'ont pas besoin d'être de la même classe d'instance, et elles peuvent être allouées et terminées comme on le souhaite. Cette architecture vous permet de dimensionner votre capacité de calcul du cluster indépendamment de son stockage.
Lorsque votre application écrit les données sur l'instance principale, celle-ci exécute une écriture durable sur le volume de cluster. Il réplique ensuite l'état de cette écriture (et non les données) sur chaque réplique active. Les répliques Amazon DocumentDB ne participent pas au traitement des écritures. Les répliques Amazon DocumentDB sont donc avantageuses pour le dimensionnement des lectures. Les lectures à partir des répliques Amazon DocumentDB sont finalement cohérentes avec un décalage de réplication minimal, généralement moins de 100 millisecondes après que l'instance principale a écrit les données. Les lectures à partir des réplicas sont assurées d'être lues dans l'ordre dans lequel elles ont été écrits sur l'instance principale. Le retard du réplica varie en fonction de la fréquence de modification des données, et les périodes de haute activité en écriture peut augmenter le retard du réplica. Pour de plus amples informations, veuillez consulter les métriques ReplicationLag dans Métriques Amazon DocumentDB.
Points de terminaison Amazon DocumentDB
Amazon DocumentDB propose plusieurs options de connexion pour répondre à un large éventail de cas d'utilisation. Pour vous connecter à une instance dans un cluster Amazon DocumentDB, vous devez spécifier le point de terminaison de l'instance. Un point de terminaison est une adresse hôte et un numéro de port, séparés par un point.
Nous vous recommandons de vous connecter à votre cluster à l'aide du point de terminaison du cluster et en mode jeu de réplicas (voir Connexion à Amazon DocumentDB en tant que jeu de répliques), sauf si vous avez un cas d'utilisation spécifique pour vous connecter au point de terminaison du lecteur ou au point de terminaison d'une instance. Pour acheminer les demandes vers vos réplicas, choisissez un mode de préférence de lecture de pilote qui optimise la disponibilité en lecture tout en répondant à vos exigences de cohérence en lecture de votre application. La préférence de secondaryPreferred lecture active les lectures de réplica et libère l'instance principale pour effectuer plus de travail.
Les points de terminaison suivants sont disponibles à partir d'un cluster Amazon DocumentDB.
Point de terminaison de cluster
Le point de terminaison du cluster se connecte à l'instance principale actuelle de votre cluster. Des opérations de lecture et d'écriture peuvent être effectuées à l'aide du point de terminaison du cluster. Un cluster Amazon DocumentDB possède exactement un point de terminaison de cluster.
Le point de terminaison de cluster assure la prise en charge du basculement pour les connexions en lecture/écriture au cluster. En cas de défaillance de l'instance principale actuelle de votre cluster et si ce dernier possède au moins un réplica en lecture actif, le point de terminaison du cluster redirige automatiquement les demandes de connexion vers une nouvelle instance principale. Lorsque vous vous connectez à votre cluster Amazon DocumentDB, nous vous recommandons de vous connecter à votre cluster en utilisant le point de terminaison du cluster et en mode Replica Set (voirConnexion à Amazon DocumentDB en tant que jeu de répliques).
Voici un exemple de point de terminaison du cluster Amazon DocumentDB :
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
L'exemple suivant présente une chaîne de connexion utilisant ce point de terminaison de cluster :
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Pour plus d'informations sur la recherche des points de terminaison d'un cluster, consultez Trouver les points de terminaison d'un cluster.
Point de terminaison du lecteur
Le point de terminaison du lecteur équilibre les charges des connexions en lecture seule sur tous les réplicas disponibles dans votre cluster. Un point de terminaison du lecteur de cluster fonctionnera comme le point de terminaison du cluster si vous vous connectez via le replicaSet mode, ce qui signifie que dans la chaîne de connexion, le paramètre du jeu de &replicaSet=rs0 répliques est Dans ce cas, vous pourrez effectuer des opérations d'écriture sur le primaire. Toutefois, si vous vous connectez au cluster spécifiédirectConnection=true, la tentative d'exécution d'une opération d'écriture via une connexion au point de terminaison du lecteur entraîne une erreur. Un cluster Amazon DocumentDB possède exactement un point de terminaison de lecteur.
Si le cluster ne contient qu'une instance (principale), le point de terminaison du lecteur se connecte à l'instance principale. Lorsque vous ajoutez une instance de réplique à votre cluster Amazon DocumentDB, le point de terminaison du lecteur ouvre des connexions en lecture seule vers la nouvelle réplique une fois celle-ci active.
Voici un exemple de point de terminaison de lecteur pour un cluster Amazon DocumentDB :
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
L'exemple suivant présente une chaîne de connexion utilisant un point de terminaison de lecteur :
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
Le point de terminaison de lecteur équilibre les charges des connexions en lecture seule, pas les demandes de lecture. Si les connexions du point de terminaison du lecteur sont plus largement utilisées que d'autres, vos demandes de lecture risquent de ne pas être correctement équilibrées entre les instances du cluster. Il est recommandé de distribuer les demandes en se connectant au point de terminaison du cluster en tant que jeu de réplicas et en utilisant l'option de préférence de lecture secondaryPreferred.
Pour plus d'informations sur la recherche des points de terminaison d'un cluster, consultez Trouver les points de terminaison d'un cluster.
Point de terminaison d'instance
Un point de terminaison d'instance se connecte à une instance spécifique dans votre cluster. Le point de terminaison d'instance pour l'instance principale actuelle peut être utilisé pour des opérations de lecture et d'écriture. Toutefois, la tentative d'effectuer des opérations d'écriture sur un point de terminaison d'instance pour un réplica en lecture se traduit par une erreur. Un cluster Amazon DocumentDB possède un point de terminaison d'instance par instance active.
Un point de terminaison d'instance exerce un contrôle direct sur une instance spécifique, pour les scénarios où l'utilisation du point de terminaison de cluster ou du point de terminaison de lecteur peut ne pas être appropriée. Un exemple de cas d'utilisation est la mise en service pour une charge de travail périodique des analyses en lecture seule. Vous pouvez provisionner une instance de larger-than-normal réplique, vous connecter directement à la nouvelle instance plus grande avec son point de terminaison, exécuter les requêtes d'analyse, puis mettre fin à l'instance. L'utilisation du point de terminaison d'instance empêche le trafic des analyses d'avoir un effet sur d'autres instances de cluster.
Voici un exemple de point de terminaison d'instance pour une instance unique dans un cluster Amazon DocumentDB :
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
L'exemple suivant présente une chaîne de connexion utilisant ce point de terminaison d'instance :
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Note
Un rôle de l'instance en tant que principale ou réplica peut changer suite à un événement de basculement. Vos applications ne doivent jamais supposer qu'un point de terminaison d'une instance particulière est le principal. Nous ne recommandons pas la connexion aux points de terminaison d'instance pour les applications en production. Au lieu de cela, nous vous recommandons de vous connecter à votre cluster à l'aide du point de terminaison du cluster et en mode jeu de réplicas (voir Connexion à Amazon DocumentDB en tant que jeu de répliques). Pour un contrôle plus avancé de la priorité de basculement d'une instance, consultez Comprendre la tolérance aux pannes des clusters Amazon DocumentDB.
Pour plus d'informations sur la recherche des points de terminaison d'un cluster, consultez Trouver le point de terminaison d'une instance.
Mode Replica Set
Vous pouvez vous connecter à votre point de terminaison de cluster Amazon DocumentDB en mode jeu de répliques en spécifiant le nom du jeu de répliques. rs0 La connexion en mode Jeu de réplicas fournit la capacité de spécifier les options Problème de lecture, Problème d'écriture et Préférences de lecture. Pour de plus amples informations, veuillez consulter Cohérence en lecture.
Voici un exemple de chaîne de connexion se connectant en mode Jeu de réplicas :
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Lorsque vous vous connectez en mode jeu de répliques, votre cluster Amazon DocumentDB apparaît à vos pilotes et clients sous la forme d'un jeu de répliques. Les instances ajoutées et supprimées de votre cluster Amazon DocumentDB sont automatiquement reflétées dans la configuration du jeu de répliques.
Chaque cluster Amazon DocumentDB se compose d'un seul ensemble de répliques portant le nom par défaut. rs0 Le nom du jeu de réplicas ne peut pas être modifié.
La connexion au point de terminaison du cluster en mode Jeu de réplicas est la méthode recommandée pour une utilisation générale.
Note
Toutes les instances d'un cluster Amazon DocumentDB écoutent les connexions sur le même port TCP.
Prise en charge du protocole TLS
Pour plus d'informations sur la connexion à Amazon DocumentDB à l'aide du protocole TLS (Transport Layer Security), consultez. chiffrement des données en transit
Stockage Amazon DocumentDB
Les données Amazon DocumentDB sont stockées dans un volume de cluster, qui est un volume virtuel unique utilisant des disques SSD ()SSDs. Un volume de cluster se compose de six copies de vos données, qui sont répliquées automatiquement sur plusieurs zones de disponibilité en une seule Région AWS. Cette réplication garantit que vos données sont hautement durables, avec une possibilité moindre de perte des données. Elle permet également de vous assurer que votre cluster est plus disponible pendant un basculement, car les copies de vos données existent déjà dans d'autres zones de disponibilité. Ces copies peuvent continuer à envoyer des demandes de données aux instances de votre cluster Amazon DocumentDB.
Facturation du stockage des données
Amazon DocumentDB augmente automatiquement la taille d'un volume de cluster à mesure que la quantité de données augmente. Un volume de cluster Amazon DocumentDB peut atteindre une taille maximale de 128 TiB ; toutefois, seul l'espace que vous utilisez dans un volume de cluster Amazon DocumentDB vous est facturé. À partir d'Amazon DocumentDB 4.0, lorsque des données sont supprimées, par exemple en supprimant une collection ou un index, l'espace global alloué diminue d'une quantité comparable. Ainsi, vous pouvez réduire les frais de stockage en supprimant les collections, les index et les bases de données dont vous n'avez plus besoin. Dans Amazon DocumentDB version 3.6, le volume du cluster peut réutiliser l'espace libéré lorsque vous supprimez des données, mais la taille du volume lui-même ne diminue jamais. Par conséquent, dans la version 3.6, il est possible que vous ne constatiez aucun changement de stockage lorsque vous supprimez une collection ou un index, même si l'espace libéré est réutilisé.
Note
Avec Amazon DocumentDB 3.6, les coûts de stockage sont basés sur le « seuil maximum » de stockage (le montant maximum alloué au cluster Amazon DocumentDB à un moment donné). Vous pouvez gérer les coûts en évitant les pratiques ETL qui créent de gros volumes d'informations temporaires ou qui chargent de gros volumes de nouvelles données avant de supprimer les anciennes données inutiles. Si la suppression de données d'un cluster Amazon DocumentDB se traduit par une quantité importante d'espace alloué mais inutilisé, la réinitialisation du seuil maximum nécessite d'effectuer un vidage logique des données et de les restaurer sur un nouveau cluster, à l'aide d'un outil tel que ou. mongodump mongorestore Le fait de créer et de restaurer un instantané n'a pas pour effet de réduire le stockage alloué, car la structure physique du stockage sous-jacent reste inchangée dans l'instantané restauré.
Note
L'utilisation d'utilitaires tels que mongodump et mongorestore entraîne des I/O frais en fonction de la taille des données lues et écrites sur le volume de stockage.
Pour plus d'informations sur le stockage et la tarification des données Amazon DocumentDB, consultez la section I/O Tarification et tarification d'Amazon DocumentDB (compatible avec MongoDB
Réplication Amazon DocumentDB
Dans un cluster Amazon DocumentDB, chaque instance de réplique expose un point de terminaison indépendant. Ces points de terminaison de réplica fournissent l'accès en lecture seule aux données du volume de cluster. Ils vous permettent de dimensionner la charge de travail en lecture pour vos données sur plusieurs instances répliquées. Ils contribuent également à améliorer les performances de lecture des données et à augmenter la disponibilité des données dans votre cluster Amazon DocumentDB. Les répliques Amazon DocumentDB sont également des cibles de basculement et sont rapidement promues en cas de défaillance de l'instance principale de votre cluster Amazon DocumentDB.
Fiabilité d'Amazon DocumentDB
Amazon DocumentDB est conçu pour être fiable, durable et tolérant aux pannes. (Pour améliorer la disponibilité, vous devez configurer votre cluster Amazon DocumentDB de manière à ce qu'il dispose de plusieurs instances de réplication dans différentes zones de disponibilité.) Amazon DocumentDB inclut plusieurs fonctionnalités automatiques qui en font une solution de base de données fiable.
Réparation automatique du stockage
Amazon DocumentDB conserve plusieurs copies de vos données dans trois zones de disponibilité, ce qui réduit considérablement le risque de perte de données en cas de panne de stockage. Amazon DocumentDB détecte automatiquement les défaillances dans le volume du cluster. Lorsqu'un segment d'un volume de cluster tombe en panne, Amazon DocumentDB répare immédiatement le segment. Il utilise les données des autres volumes qui composent le volume de cluster pour garantir que les données du segment réparé sont actives. Amazon DocumentDB évite ainsi les pertes de données et réduit le besoin d'effectuer une point-in-time restauration pour récupérer après une défaillance d'instance.
Préparation du cache « survivable »
Amazon DocumentDB gère son cache de pages dans le cadre d'un processus distinct de celui de la base de données afin que le cache de pages puisse survivre indépendamment de la base de données. Dans l'éventualité peu probable d'une défaillance de la base de données, le cache de page reste en mémoire. Cela garantit que le groupe de tampons est préparé avec l'état le plus courant au redémarrage de la base de données.
Récupération sur incident
Amazon DocumentDB est conçu pour effectuer une restauration quasi instantanée en cas de panne et pour continuer à diffuser les données de votre application. Amazon DocumentDB effectue une restauration après incident de manière asynchrone sur des threads parallèles afin que votre base de données soit ouverte et disponible presque immédiatement après un crash.
Gouvernance des ressources
Amazon DocumentDB protège les ressources nécessaires à l'exécution des processus critiques du service, tels que les bilans de santé. Pour ce faire, et lorsqu'une instance est confrontée à une pression de mémoire élevée, Amazon DocumentDB limite les demandes. Par conséquent, certaines opérations peuvent être mises en file d'attente pour attendre que la pression sur la mémoire diminue. Si la pression sur la mémoire persiste, les opérations en file d'attente peuvent expirer. Vous pouvez vérifier si le service ralentit les opérations en raison d'un manque de mémoire à l'aide des CloudWatch mesures suivantes :LowMemThrottleQueueDepth,LowMemThrottleMaxQueueDepth,LowMemNumOperationsThrottled. LowMemNumOperationsTimedOut Pour plus d'informations, consultez la section Surveillance d'Amazon DocumentDB avec. CloudWatch Si vous constatez une pression de mémoire soutenue sur votre instance en raison de ces LowMem CloudWatch indicateurs, nous vous conseillons de la dimensionner afin de fournir de la mémoire supplémentaire pour votre charge de travail.
Options de préférence de lecture
Amazon DocumentDB utilise un service de stockage partagé cloud natif qui réplique les données six fois sur trois zones de disponibilité afin de garantir des niveaux de durabilité élevés. Amazon DocumentDB ne repose pas sur la réplication de données vers plusieurs instances pour garantir la durabilité. Les données de votre cluster sont durable qu'elles contiennent une seule instance ou 15 instances.
Rubriques
Durabilité de l'écriture
Amazon DocumentDB utilise un système de stockage unique, distribué, tolérant aux pannes et autoréparateur. Ce système réplique six copies (V=6) de vos données dans trois zones de disponibilité pour garantir une AWS disponibilité et une durabilité élevées. Lors de l'écriture de données, Amazon DocumentDB s'assure que toutes les écritures sont enregistrées de manière durable sur la majorité des nœuds avant de confirmer l'écriture au client. Si vous utilisez un jeu de répliques MongoDB à trois nœuds, l'utilisation d'un souci d'écriture {w:3, j:true} de permettrait d'obtenir la meilleure configuration possible par rapport à Amazon DocumentDB.
Les écritures vers un cluster Amazon DocumentDB doivent être traitées par l'instance d'écriture du cluster. Toute tentative d'écriture dans un lecteur entraîne une erreur. Une écriture confirmée depuis une instance principale Amazon DocumentDB est durable et ne peut pas être annulée. Amazon DocumentDB est très durable par défaut et ne prend pas en charge les options d'écriture non durables. Vous ne pouvez pas modifier le niveau de durabilité (c'est-à-dire, le problème d'écriture). Amazon DocumentDB ignore w=anything et affiche effectivement w : 3 et j : true. Vous ne pouvez pas le réduire.
Le stockage et le calcul étant séparés dans l'architecture Amazon DocumentDB, un cluster avec une seule instance est extrêmement durable. La durabilité est gérée au niveau de la couche de stockage. Par conséquent, un cluster Amazon DocumentDB avec une seule instance et un cluster avec trois instances atteint le même niveau de durabilité. Vous pouvez configurer votre cluster pour votre cas d'utilisation spécifique tout en fournissant une durabilité élevée pour vos données.
Les écritures vers un cluster Amazon DocumentDB sont atomiques au sein d'un même document.
Amazon DocumentDB ne prend pas en charge wtimeout cette option et ne renverra pas d'erreur si une valeur est spécifiée. Il est garanti que les écritures sur l'instance Amazon DocumentDB principale ne seront pas bloquées indéfiniment.
Lire l'isolation
Les lectures effectuées à partir d'une instance Amazon DocumentDB ne renvoient que des données durables avant le début de la requête. Les lectures ne renvoient jamais des données modifiées après la début de l'exécution par la requête et des lectures sales ne sont pas possibles, quelles que soient les circonstances.
Cohérence en lecture
Les données lues depuis un cluster Amazon DocumentDB sont durables et ne seront pas annulées. Vous pouvez modifier la cohérence de lecture pour les lectures Amazon DocumentDB en spécifiant la préférence de lecture pour la demande ou la connexion. Amazon DocumentDB ne prend pas en charge les options de lecture non durables.
Les lectures effectuées à partir de l'instance principale d'un cluster Amazon DocumentDB sont parfaitement cohérentes dans des conditions de fonctionnement normales et sont read-after-write cohérentes. Si un basculement se produit entre la lecture et l'écriture ultérieure, le système peut brièvement renvoyer une lecture qui n'est pas fortement cohérente. Toutes les lectures à partir d'un réplica en lecture présentent une cohérence éventuelle et renvoient les données dans le même ordre, et souvent avec une latence de réplica inférieure à 100 millisecondes.
Préférences de lecture d'Amazon DocumentDB
Amazon DocumentDB prend en charge la définition d'une option de préférence de lecture uniquement lors de la lecture de données depuis le point de terminaison du cluster en mode Replica Set. La définition d'une option de préférence de lecture affecte la manière dont votre client ou pilote MongoDB achemine les demandes de lecture vers les instances de votre cluster Amazon DocumentDB. Vous pouvez définir des options de préférence de lecture pour une requête spécifique, ou en tant qu'option générale dans votre pilote MongoDB. (Consultez votre client ou la documentation du pilote pour obtenir des instructions sur la façon de définir une option de préférence de lecture).
Si votre client ou pilote ne se connecte pas à un point de terminaison du cluster Amazon DocumentDB en mode Replica Set, le résultat de la spécification d'une préférence de lecture n'est pas défini.
Amazon DocumentDB ne prend pas en charge la définition de jeux de balises comme préférence de lecture.
Options de préférences de lecture prises en charge
-
primary—La spécification d'une préférence deprimarylecture permet de garantir que toutes les lectures sont acheminées vers l'instance principale du cluster. Si l'instance principale n'est pas disponible, l'opération de lecture échoue. Une préférence deprimarylecture garantit la read-after-write cohérence et convient aux cas d'utilisation qui privilégient la read-after-write cohérence par rapport à la haute disponibilité et à la mise à l'échelle de lecture.L'exemple suivant spécifie une préférence de lecture «
primary» :db.example.find().readPref('primary') -
primaryPreferred—La spécification d'une préférence deprimaryPreferredlecture achemine les lectures vers l'instance principale dans le cadre d'un fonctionnement normal. En cas de basculement principal, le client achemine les demandes vers un réplica. Une préférence deprimaryPreferredlecture garantit read-after-write la cohérence pendant le fonctionnement normal et, en fin de compte, la cohérence des lectures lors d'un événement de basculement. Une préférence deprimaryPreferredlecture convient aux cas d'utilisation qui privilégient la read-after-write cohérence par rapport à la mise à l'échelle de lecture, mais qui nécessitent tout de même une haute disponibilité.L'exemple suivant spécifie une préférence de lecture «
primaryPreferred» :db.example.find().readPref('primaryPreferred') -
secondary—La spécification d'une préférence desecondarylecture garantit que les lectures ne sont acheminées que vers une réplique, jamais vers l'instance principale. S'il n'y a pas d'instances de réplica dans un cluster, la demande de lecture échoue. Une préférence desecondarylecture aboutit à des lectures cohérentes et convient aux cas d'utilisation qui privilégient le débit d'écriture de l'instance principale par rapport à la haute disponibilité et à la read-after-write cohérence.L'exemple suivant spécifie une préférence de lecture «
secondary» :db.example.find().readPref('secondary') -
secondaryPreferred—La spécification d'une préférence desecondaryPreferredlecture garantit que les lectures sont acheminées vers une réplique en lecture lorsqu'une ou plusieurs répliques sont actives. S'il n'y a pas d'instances de réplica actives dans un cluster, la demande de lecture est acheminé vers l'instance principale. Une préférence de lecture «secondaryPreferred» génère des lectures cohérentes à terme (eventually consistent) lorsque la lecture est traitée par un réplica en lecture. Cela permet d'obtenir de la read-after-write cohérence lorsque la lecture est prise en charge par l'instance principale (sauf en cas de basculement). Une préférence desecondaryPreferredlecture convient aux cas d'utilisation qui privilégient la mise à l'échelle de lecture et la haute disponibilité plutôt que read-after-write la cohérence.L'exemple suivant spécifie une préférence de lecture «
secondaryPreferred» :db.example.find().readPref('secondaryPreferred') -
nearest—La spécification d'une préférence denearestlecture achemine les lectures uniquement en fonction de la latence mesurée entre le client et toutes les instances du cluster Amazon DocumentDB. Une préférence de lecture «nearest» génère des lectures cohérentes à terme (eventually consistent) lorsque la lecture est traitée par un réplica en lecture. Cela permet d'obtenir de la read-after-write cohérence lorsque la lecture est prise en charge par l'instance principale (sauf en cas de basculement). Une préférence denearestlecture convient aux cas d'utilisation qui privilégient la latence de lecture la plus faible possible et la haute disponibilité plutôt que la read-after-write cohérence et la mise à l'échelle de lecture.L'exemple suivant spécifie une préférence de lecture «
nearest» :db.example.find().readPref('nearest')
Haute disponibilité
Amazon DocumentDB prend en charge les configurations de clusters à haute disponibilité en utilisant des répliques comme cibles de basculement pour l'instance principale. En cas de défaillance de l'instance principale, une réplique Amazon DocumentDB est promue en tant que nouvelle instance principale, avec une brève interruption au cours de laquelle les demandes de lecture et d'écriture adressées à l'instance principale échouent, sauf exception.
Si votre cluster Amazon DocumentDB n'inclut aucune réplique, l'instance principale est recréée en cas de panne. Cependant, la promotion d'une réplique Amazon DocumentDB est beaucoup plus rapide que la recréation de l'instance principale. Nous vous recommandons donc de créer une ou plusieurs répliques Amazon DocumentDB comme cibles de basculement.
Les réplicas qui sont destinés à être utilisés comme cibles de basculement doivent appartenir à la même classe d'instance que l'instance principale. Ils doivent être mis en service dans des zones de disponibilité autres que celle de l'instance principale. Vous pouvez décider les réplicas préférés comme cibles de basculement. Pour connaître les meilleures pratiques relatives à la configuration d'Amazon DocumentDB pour une haute disponibilité, consultez. Comprendre la tolérance aux pannes des clusters Amazon DocumentDB
Dimensionnement des lectures
Les répliques Amazon DocumentDB sont idéales pour le dimensionnement des lectures. Elles sont entièrement dédiées aux opérations de lecture sur votre volume de cluster, ce qui signifie que les réplicas ne traitent pas les écritures. La réplication de données se produit au sein du volume de cluster et non pas entre les instances. Par conséquent, les ressources de chaque réplica sont dédiées au traitement de vos requêtes, et non à la réplication et à l'écriture des données.
Si votre application exige plus de capacité de lecture, vous pouvez rapidement ajouter un réplica à votre cluster (généralement en moins de 10 minutes). Si vos exigences en matière de capacités en lecture diminuent, vous pouvez supprimer les réplicas devenus inutiles. Avec les répliques Amazon DocumentDB, vous ne payez que pour la capacité de lecture dont vous avez besoin.
Amazon DocumentDB prend en charge le dimensionnement de lecture côté client grâce à l'utilisation des options de préférence de lecture. Pour de plus amples informations, veuillez consulter Préférences de lecture d'Amazon DocumentDB.
TTL supprime
Les suppressions depuis une zone d'index TTL via un processus en arrière-plan sont effectuées dans la mesure du possible et ne sont pas garanties au cours d'une période spécifique. Des facteurs tels que la taille des instances, l'utilisation de ressources des instances, la taille de document et le débit global peuvent affecter le déroulement d'une suppression TTL.
Lorsque le moniteur TTL supprime vos documents, chaque suppression entraîne des coûts d'E/S, ce qui augmente le montant de votre facture. Si le débit et les taux de suppression TTL augmentent, vous devez vous attendre à une augmentation de votre facture en raison de l'utilisation accrue des E/S.
Lorsque vous créez un index TTL sur une collection existante, vous devez supprimer tous les documents expirés avant de créer l'index. L'implémentation TTL actuelle est optimisée pour supprimer une petite partie des documents de la collection, ce qui est typique si le TTL a été activé sur la collection dès le début, et peut entraîner des IOPS plus élevées que nécessaire si un grand nombre de documents doivent être supprimés en une seule fois.
Si vous ne souhaitez pas créer d'index TTL pour supprimer des documents, vous pouvez segmenter les documents en collections en fonction du temps et simplement supprimer ces collections lorsque les documents ne sont plus nécessaires. Par exemple : vous pouvez créer une collection par semaine et la supprimer sans encourir de frais d'E/S. Cela peut s'avérer nettement plus rentable que l'utilisation d'un indice TTL.
Ressources facturables
Identification des ressources Amazon DocumentDB facturables
En tant que service de base de données entièrement géré, Amazon DocumentDB facture les instances, le stockage, les E/S, les sauvegardes et le transfert de données. Pour plus d'informations, consultez la tarification d'Amazon DocumentDB (compatible avec MongoDB
Pour découvrir les ressources facturables présentes sur votre compte et éventuellement les supprimer, vous pouvez utiliser le AWS Management Console ou AWS CLI.
À l'aide du AWS Management Console
À l'aide de AWS Management Console, vous pouvez découvrir les clusters, les instances et les instantanés Amazon DocumentDB que vous avez provisionnés pour un usage donné. Région AWS
Pour découvrir des clusters, instances et instantanés
-
Pour découvrir les ressources facturables dans une région autre que votre région par défaut, dans le coin supérieur droit de l'écran, choisissez Région AWS celle que vous souhaitez rechercher.
-
Dans le panneau de navigation, choisissez le type de ressource facturable qui vous intéresse : Clusters, Instances ou Snapshots (Instantanés).
-
Tous vos clusters,instances ou instantanés mis en service pour la région sont répertoriés dans le panneau droit. Vous serez facturé pour les clusters, les instances et les instantanés.
À l'aide du AWS CLI
À l'aide de AWS CLI, vous pouvez découvrir les clusters, les instances et les instantanés Amazon DocumentDB que vous avez provisionnés pour un usage donné. Région AWS
Pour découvrir des clusters et des instances
Le code suivant répertorie tous vos clusters et instances pour la région spécifiée. Si vous souhaitez rechercher des clusters et des instances dans votre région par défaut, vous pouvez omettre le paramètre --region.
Pour Linux, macOS ou Unix :
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Pour Windows :
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Le résultat de cette opération ressemble à ceci.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",Pour découvrir des instantanés
Le code suivant répertorie tous vos instantanés pour la région spécifiée. Si vous souhaitez rechercher des instantanés dans votre région par défaut, vous pouvez omettre le paramètre --region.
Pour Linux, macOS ou Unix :
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Pour Windows :
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Le résultat de cette opération ressemble à ceci.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]Il vous suffit de supprimer les instantanés manual. Les instantanésAutomated sont supprimés lorsque vous supprimez le cluster.
Supprimer les ressources facturables indésirables
Pour supprimer un cluster, vous devez d'abord supprimer toutes les instances du cluster.
-
Pour supprimer des instances, consultez Suppression d'une instance Amazon DocumentDB.
Important
Même si vous supprimez les instances d'un cluster, vous êtes encore facturé pour l'utilisation du stockage et des sauvegardes associée à ce cluster. Pour arrêter tous les frais, vous devez également supprimer votre cluster et les instantanés manuels.
-
Pour supprimer des clusters, consultez Supprimer un cluster Amazon DocumentDB.
-
Pour supprimer des instantanés manuels, veuillez consulter Suppression d'un instantané de cluster.
