Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Récupération de métriques avec l'API Performance Insights
Lorsque l'API Performance Insights est activée, elle fournit une visibilité sur les performances des instances. Amazon CloudWatch Logs fournit la source officielle pour les mesures de surveillance des ventes pour AWS les services.
Performance Insights offre une vue spécifique au domaine de la charge de base de données mesurée en tant que moyenne des sessions actives (AAS). Cette métrique est présentée aux consommateurs de l'API sous la forme d'un ensemble de données de série chronologique bidimensionnel. La dimension temporelle des données fournit les données de charge de la base de données pour chaque point temporel de la plage de temps interrogée. Chaque point dans te temps décompose la charge globale par rapport aux dimensions demandées, par exemple, Query, Wait-state, Application ou Host, mesurée à ce point dans le temps.
Amazon DocumentDB Performance Insights surveille votre instance de base de données Amazon DocumentDB afin que vous puissiez analyser et résoudre les problèmes liés aux performances de la base de données. Vous pouvez consulter les données de Performance Insights dans AWS Management Console. Performance Insights fournit également une API publique qui vous permet d'interroger vos propres données. Vous pouvez utiliser l'API pour effectuer les opérations suivantes :
-
Déchargement des données dans une base de données
-
Ajout de données Performance Insights aux tableaux de bord de surveillance existants
-
Création d'outils de surveillance
Pour utiliser l'API Performance Insights, activez Performance Insights sur l'une de vos instances Amazon DocumentDB. Pour de plus amples informations sur l'activation de Performance Insights, veuillez consulter Activation et désactivation de Performance Insights. Pour de plus amples informations sur l'API Performance Insights, veuillez consulter la Référence d'API Performance Insights.
L'API Performance Insights fournit les opérations suivantes.
|
Action Performance Insights |
AWS CLI commande |
Description |
|---|---|---|
|
Récupère les N premières clés de dimension d'une mesure sur une période spécifique. |
||
|
Récupère les attributs du groupe de dimensions spécifié pour une instance de base de données ou une source de données. Par exemple, si vous spécifiez un ID de requête et si les détails de la dimension sont disponibles, le texte intégral de la dimension |
||
GetResourceMetadata |
Récupérez les métadonnées de différentes fonctions. Par exemple, les métadonnées peuvent indiquer qu'une fonction est activée ou désactivée sur une instance de base de données spécifique. |
|
|
Récupère les métriques Performance Insights d'un ensemble de sources de données, au cours d'une période. Vous pouvez fournir des groupes de dimensions et des dimensions spécifiques, ainsi que des critères d'agrégation et de filtrage, pour chaque groupe. |
||
ListAvailableResourceDimensions |
Récupérez les dimensions pouvant être interrogées pour chaque type de métrique spécifié sur une instance spécifiée. |
|
ListAvailableResourceMetrics |
Récupérez toutes les métriques disponibles des types de métriques spécifiés pouvant être interrogés pour une instance de base de données spécifiée. |
Rubriques
AWS CLI pour Performance Insights
Vous pouvez consulter les données de Performance Insights à l'aide d AWS CLI. Vous pouvez obtenir de l'aide sur les commandes AWS CLI relatives à Performance Insights en saisissant le code suivant sur la ligne de commande.
aws pi help
Si ce n'est pas le AWS CLI cas, reportez-vous à la section Installation de l'interface de ligne de AWS commande dans le guide de AWS CLI l'utilisateur pour plus d'informations sur son installation.
Récupération de métriques de série chronologique
L'opération GetResourceMetrics récupère une ou plusieurs métriques de série chronologique à partir des données de Performance Insights. GetResourceMetrics exige une métrique et une période, et renvoie une réponse contenant la liste des points de données.
Par exemple, les AWS Management Console utilisations GetResourceMetrics pour remplir le graphique Counter Metrics et le graphique de charge de base de données, comme indiqué dans l'image suivante.
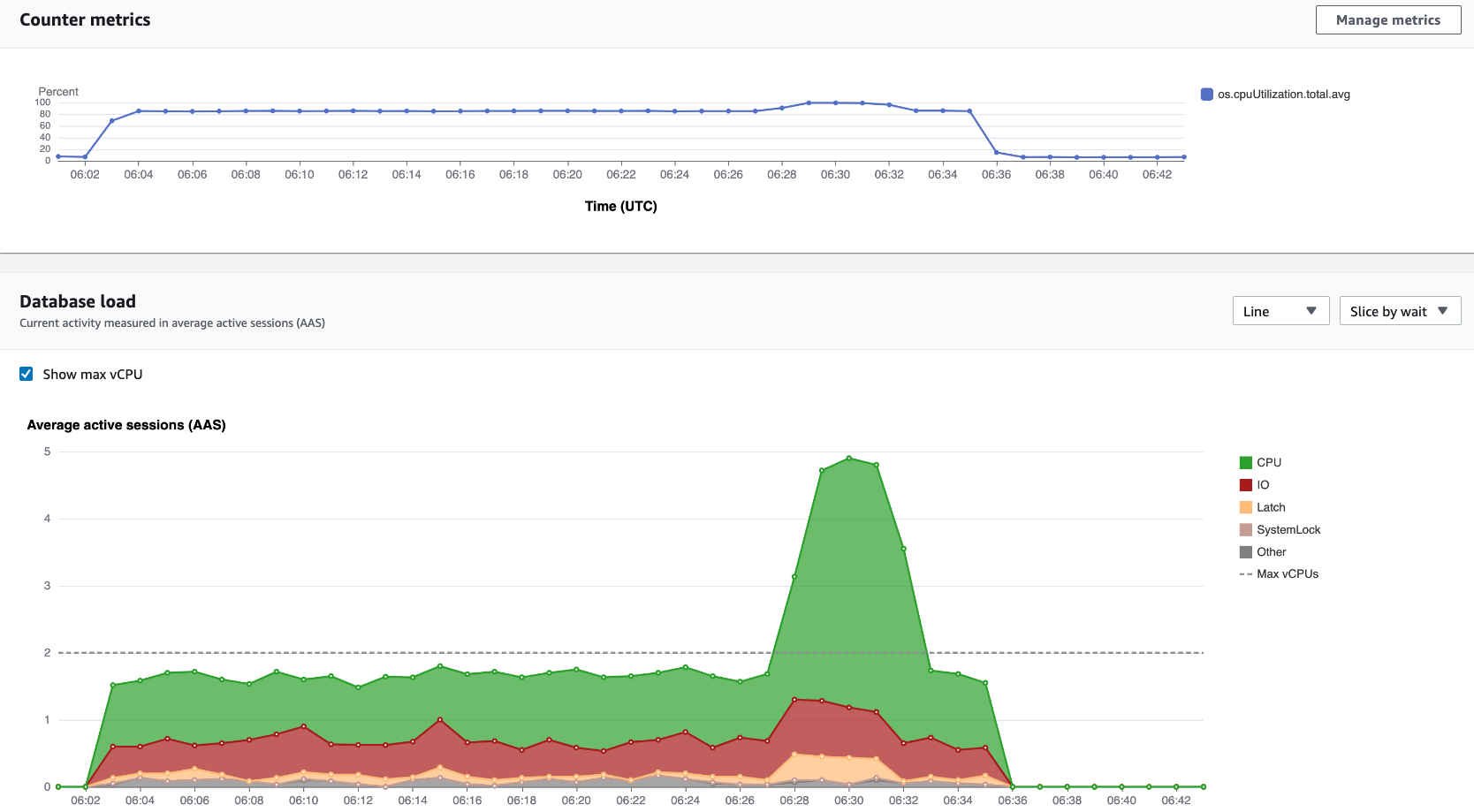
Toutes les métriques renvoyées par GetResourceMetrics sont des métriques de série chronologique standard, à l'exception de db.load. Elle apparaît dans le graphique Database Load (Charge de base de données). La métrique db.load est différente des autres métriques de série chronologique, car vous pouvez la décomposer en sous-composants appelés dimensions. Dans l'image précédente, db.load est décomposé et regroupé en fonction des états d'attente qui constituent db.load.
Note
GetResourceMetrics peut également renvoyer la métrique db.sampleload, mais la métrique db.load est appropriée dans la plupart des cas.
Pour de plus amples informations sur les métriques de compteur renvoyées par GetResourceMetrics, veuillez consulter Performance Insights pour les contre-métriques.
Les calculs suivants sont pris en charge pour les métriques :
-
Moyenne – Moyenne de la métrique sur une période. Ajoutez
.avgau nom de la métrique. -
Minimum – Valeur minimale de la métrique sur une période. Ajoutez
.minau nom de la métrique. -
Maximum – Valeur maximale de la métrique sur une période. Ajoutez
.maxau nom de la métrique. -
Somme – Somme des valeurs de la métrique sur une période. Ajoutez
.sumau nom de la métrique. -
Nombre échantillon – Nombre de fois où la métrique a été collectée sur une période. Ajoutez
.sample_countau nom de la métrique.
Par exemple, supposons qu'une métrique soit collectée pendant 300 secondes (5 minutes) et qu'elle soit collectée une fois toutes les minutes. Les valeurs pour chaque minute sont 1, 2, 3, 4 et 5. Dans ce cas, les calculs suivants sont renvoyés :
-
Moyenne – 3
-
Minimum – 1
-
Maximum – 5
-
Somme – 15
-
Nombre échantillon – 5
Pour plus d'informations sur l'utilisation de la get-resource-metrics AWS CLI commande, consultez get-resource-metrics.
Pour l'option --metric-queries, spécifiez une ou plusieurs requêtes pour lesquelles vous souhaitez obtenir les résultats. Chaque requête se compose d'un paramètre Metric obligatoire et des paramètres GroupBy et Filter facultatifs. Voici un exemple de spécification de l'option --metric-queries.
{ "Metric": "string", "GroupBy": { "Group": "string", "Dimensions": ["string", ...], "Limit": integer }, "Filter": {"string": "string" ...}
AWS CLI exemples de Performance Insights
Les exemples suivants montrent comment utiliser AWS CLI for Performance Insights.
Rubriques
Récupération de métriques de compteur
L'image suivante illustre deux graphiques de métriques de compteur dans AWS Management Console.
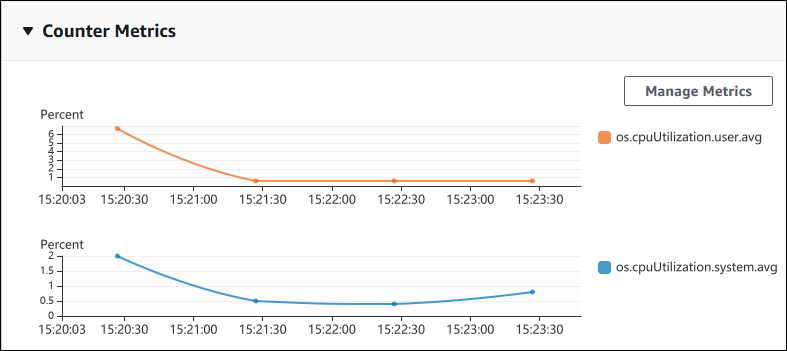
L'exemple suivant décrit comment collecter les mêmes données utilisées par AWS Management Console pour générer les deux graphiques Counter Metrics (Métriques de compteur).
Pour Linux, macOS ou Unix :
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Pour Windows :
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Vous pouvez également simplifier la lecture d'une commande en spécifiant un fichier pour l'option --metrics-query. L'exemple suivant utilise un fichier nommé query.json pour l'option. Le contenu du fichier est le suivant.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
Exécutez la commande suivante pour utiliser le fichier.
Pour Linux, macOS ou Unix :
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Pour Windows :
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
L'exemple précédent spécifie les valeurs suivantes pour les options :
-
--service-type—DOCDBpour Amazon DocumentDB -
--identifier– ID de ressource de l'instance de base de données -
--start-timeet--end-time– ValeursDateTimeconformes à l'ISO 8601 pour la période à interroger, avec plusieurs formats pris en charge
L'interrogation se déroule pendant un intervalle d'une heure :
-
--period-in-seconds–60pour une requête toutes les minutes -
--metric-queries– Tableau de deux requêtes s'appliquant chacune à une métrique.Le nom de la métrique utilise des points pour classifier la métrique dans une catégorie utile, l'élément final étant une fonction. Dans l'exemple, la fonction est
avgpour chaque requête. Comme pour Amazon CloudWatch, les fonctions prises en charge sontminmax,total, etavg.
La réponse ressemble à ce qui suit.
{ "AlignedStartTime": "2022-03-13T08:00:00+00:00", "AlignedEndTime": "2022-03-13T09:00:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ { "Key": { "Metric": "os.cpuUtilization.user.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", //Minute1 "Value": 3.6 }, { "Timestamp": "2022-03-13T08:02:00+00:00", //Minute2 "Value": 2.6 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric { "Key": { "Metric": "os.cpuUtilization.idle.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", "Value": 92.7 }, { "Timestamp": "2022-03-13T08:02:00+00:00", "Value": 93.7 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric ] } ] //end of MetricList } //end of response
La réponse contient les éléments Identifier, AlignedStartTime et AlignedEndTime. Étant donné que la valeur de --period-in-seconds était définie sur 60, les heures de début et de fin ont été arrondies à la minute près. Si --period-in-seconds était défini sur 3600, les heures de début et de fin auraient été arrondies à l'heure près.
L'élément MetricList dans la réponse comporte un certain nombre d'entrées, chacune associée à une entrée Key et DataPoints. Chaque élément DataPoint comporte une entrée Timestamp et Value. Chaque liste Datapoints répertorie 60 points de données, car les requêtes sont exécutées toutes les minutes pendant une heure, avec Timestamp1/Minute1, Timestamp2/Minute2, etc. jusqu'à Timestamp60/Minute60.
Étant donné que la requête s'applique à deux métriques de compteur différentes, contient deux élément MetricList.
Récupération de la charge moyenne de la base de données pour les états d'attente les plus élevés
L'exemple suivant est la même requête que celle AWS Management Console utilisée pour générer un graphique linéaire à aires empilées. Cet exemple extrait le résultat de la db.load.avg dernière heure en divisant la charge en fonction des sept premiers états d'attente. La commande est identique à la commande de la rubrique Récupération de métriques de compteur. Le contenu du fichier query.json est cependant différent :
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 7 } } ]
Exécutez la commande suivante.
Pour Linux, macOS ou Unix :
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Pour Windows :
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
L'exemple indique la métrique de db.load.avg et a GroupBy des sept premiers états d'attente. Pour plus de détails sur les valeurs valides pour cet exemple, consultez DimensionGrouple manuel Performance Insights API Reference.
La réponse ressemble à ce qui suit.
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_state.name": "CPU" } }, "DataPoints": [ { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the CPU key ] },//... In total we have 3 key/datapoints entries, 1) total, 2-3) Top Wait States ] //end of MetricList } //end of response
Dans cette réponse, il y a trois entrées dans leMetricList. Il y a une entrée pour le totaldb.load.avg, et trois entrées chacune pour le résultat db.load.avg divisé en fonction de l'un des trois premiers états d'attente. Comme il existait une dimension de regroupement (contrairement au premier exemple), il doit y avoir une clé pour chaque regroupement de la métrique. Un seul élément Key peut être associé à chaque métrique, comme dans le cas d'utilisation de la métrique de compteur de base.
Récupération de la charge moyenne de la base de données pour la requête la plus fréquente
L'exemple suivant regroupe db.wait_state les 10 principales instructions de requête. Il existe deux groupes différents pour les instructions de requête :
-
db.query— L'instruction de requête complète, telle que{"find":"customers","filter":{"FirstName":"Jesse"},"sort":{"key":{"$numberInt":"1"}}} -
db.query_tokenized— L'instruction de requête tokenisée, telle que{"find":"customers","filter":{"FirstName":"?"},"sort":{"key":{"$numberInt":"?"}},"limit":{"$numberInt":"?"}}
Lors de l'analyse des performances d'une base de données, il peut être utile de considérer les instructions de requête dont les paramètres ne diffèrent que comme un élément logique. Vous pouvez donc utiliser db.query_tokenized lors de l'interrogation. Toutefois, en particulier lorsque cela vous intéresseexplain(), il est parfois plus utile d'examiner des instructions de requête complètes avec des paramètres. Il existe une relation parent-enfant entre les requêtes tokenisées et les requêtes complètes, plusieurs requêtes complètes (enfants) étant regroupées sous la même requête tokenisée (parent).
La commande illustrée dans cet exemple est identique à la commande de la rubrique Récupération de la charge moyenne de la base de données pour les états d'attente les plus élevés. Le contenu du fichier query.json est cependant différent :
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Limit": 10 } } ]
L'exemple suivant utilise db.query_tokenized.
Pour Linux, macOS ou Unix :
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Pour Windows :
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
Cet exemple montre des requêtes de plus d'une heure, avec une minute period-in-seconds.
L'exemple indique la métrique de db.load.avg et a GroupBy des sept premiers états d'attente. Pour plus de détails sur les valeurs valides pour cet exemple, consultez DimensionGrouple manuel Performance Insights API Reference.
La réponse ressemble à ce qui suit.
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { "Metric": "db.load.avg" }, "DataPoints": [ //... 60 datapoints for the total db.load.avg key ] }, { "Key": {//Next key are the top tokenized queries "Metric": "db.load.avg", "Dimensions": { "db.query_tokenized.db_id": "pi-1064184600", "db.query_tokenized.id": "77DE8364594EXAMPLE", "db.query_tokenized.statement": "{\"find\":\"customers\",\"filter\":{\"FirstName\":\"?\"},\"sort\":{\"key\":{\"$numberInt\":\"?\"}},\"limit\" :{\"$numberInt\":\"?\"},\"$db\":\"myDB\",\"$readPreference\":{\"mode\":\"primary\"}}" } }, "DataPoints": [ //... 60 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized queries, 1 total key ] //End of MetricList } //End of response
Cette réponse comporte 11 entrées MetricList (1 au total, 10 requêtes les plus tokenisées), chaque entrée en comptant 24 par heure. DataPoints
Pour les requêtes tokenisées, chaque liste de dimensions comporte trois entrées :
-
db.query_tokenized.statement— L'instruction de requête tokenisée. -
db.query_tokenized.db_id— L'identifiant synthétique que Performance Insights génère pour vous. Cet exemple renvoie l'ID synthétiquepi-1064184600. -
db.query_tokenized.id– ID de la requête dans Performance Insights.Dans le AWS Management Console, cet ID est appelé Support ID. Il est nommé ainsi parce que l'ID est une donnée que le AWS Support peut examiner pour vous aider à résoudre un problème lié à votre base de données. AWS prend très au sérieux la sécurité et la confidentialité de vos données, et presque toutes les données sont stockées cryptées avec votre AWS KMS key. Par conséquent, personne à l'intérieur ne AWS peut consulter ces données. Dans l'exemple précédent,
tokenized.statementettokenized.db_idsont tous les deux stockés sous forme chiffrée. Si vous rencontrez un problème avec votre base de données, le AWS Support peut vous aider en faisant référence à l'ID de support.
Lors de l'interrogation, il peut s'avérer utile de spécifier une entrée Group dans GroupBy. Toutefois, pour contrôler les données renvoyées de manière plus précise, spécifier la liste des dimensions. Par exemple, si db.query_tokenized.statement est le seul élément nécessaire, un attribut Dimensions peut être ajouté au fichier query.json.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Dimensions":["db.query_tokenized.statement"], "Limit": 10 } } ]
Récupération de la charge moyenne de la base de données filtrée par requête
La requête d'API correspondante illustrée dans cet exemple est identique à la commande de la rubrique Récupération de la charge moyenne de la base de données pour la requête la plus fréquente. Le contenu du fichier query.json est cependant différent :
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 5 }, "Filter": { "db.query_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
Dans cette réponse, toutes les valeurs sont filtrées en fonction de la contribution de la requête tokenisée AKIAIOSFODNN7 EXAMPLE spécifiée dans le fichier query.json. Les clés peuvent également suivre un ordre différent de celui d'une requête sans filtre, car ce sont les cinq premiers états d'attente qui ont affecté la requête filtrée.
