Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Théorie de la mise à l'échelle de Kubernetes
Nœuds par rapport au taux de désabonnement
Lorsque nous discutons de l'évolutivité de Kubernetes, nous le faisons souvent en fonction du nombre de nœuds présents dans un seul cluster. Il est intéressant de noter qu'il s'agit rarement de la métrique la plus utile pour comprendre l'évolutivité. Par exemple, un cluster de 5 000 nœuds avec un nombre important mais fixe de pods n'exercerait pas beaucoup de stress sur le plan de contrôle après la configuration initiale. Cependant, si nous prenions un cluster de 1 000 nœuds et essayions de créer 10 000 emplois de courte durée en moins d'une minute, cela exercerait une forte pression soutenue sur le plan de contrôle.
Le simple fait d'utiliser le nombre de nœuds pour comprendre le dimensionnement peut être trompeur. Il est préférable de penser en termes de taux de changement qui se produit au cours d'une période donnée (utilisons un intervalle de 5 minutes pour cette discussion, car c'est ce que les requêtes Prometheus utilisent généralement par défaut). Voyons pourquoi le fait de définir le problème en termes de taux de variation peut nous donner une meilleure idée de ce qu'il faut ajuster pour atteindre l'échelle souhaitée.
Réflexion en requêtes par seconde
Kubernetes dispose d'un certain nombre de mécanismes de protection pour chaque composant (Kubelet, Scheduler, Kube Controller Manager et serveur d'API) afin d'éviter de submerger le maillon suivant de la chaîne Kubernetes. Par exemple, le Kubelet dispose d'un indicateur pour limiter les appels au serveur d'API à un certain rythme. Ces mécanismes de protection sont généralement, mais pas toujours, exprimés en termes de requêtes autorisées par seconde ou de QPS.
Il faut faire très attention lors de la modification de ces paramètres QPS. La suppression d'un goulot d'étranglement, tel que le nombre de requêtes par seconde sur un Kubelet, aura un impact sur les autres composants en aval. Cela peut surcharger le système au-delà d'un certain rythme. Il est donc essentiel de comprendre et de surveiller chaque partie de la chaîne de services pour réussir à dimensionner les charges de travail sur Kubernetes.
Note
Le serveur d'API dispose d'un système plus complexe avec l'introduction de la priorité et de l'équité des API, dont nous parlerons séparément.
Note
Attention, certains indicateurs semblent convenir, mais ils mesurent en fait autre chose. Par exemple, cela kubelet_http_inflight_requests concerne uniquement le serveur de métriques dans Kubelet, et non le nombre de requêtes de Kubelet aux requêtes apiserver. Cela pourrait nous amener à mal configurer le drapeau QPS sur le Kubelet. Une requête sur les journaux d'audit d'un Kubelet en particulier serait un moyen plus fiable de vérifier les métriques.
Mise à l'échelle des composants distribués
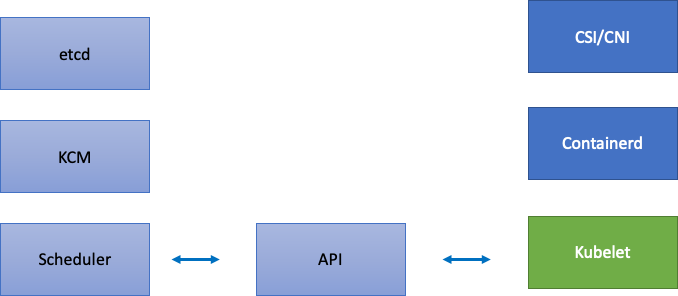
EKS étant un service géré, divisons les composants Kubernetes en deux catégories : les composants gérés par AWS, qui incluent etcd, Kube Controller Manager et le planificateur (sur la partie gauche du schéma), et les composants configurables par le client tels que Kubelet, Container Runtime et les différents opérateurs qui appellent AWS, APIs tels que les pilotes réseau et de stockage (sur la partie droite du schéma). Nous laissons le serveur d'API au centre même s'il est géré par AWS, car les paramètres de priorité et d'équité des API peuvent être configurés par les clients.
Goulets d'étranglement en amont et en aval
Lorsque nous surveillons chaque service, il est important d'examiner les indicateurs dans les deux sens afin de détecter les goulots d'étranglement. Apprenons comment procéder en utilisant Kubelet comme exemple. Kubelet parle à la fois au serveur d'API et au runtime du conteneur ; comment et que devons-nous surveiller pour détecter si l'un des composants rencontre un problème ?
Combien de pods par nœud
Lorsque nous examinons les chiffres d'échelle, tels que le nombre de pods pouvant fonctionner sur un nœud, nous pouvons prendre les 110 pods par nœud pris en charge en amont à leur valeur nominale.
Cependant, votre charge de travail est probablement plus complexe que ce qui a été testé lors d'un test d'évolutivité dans Upstream. Pour nous assurer que nous pouvons gérer le nombre de pods que nous voulons exécuter en production, veillons à ce que le Kubelet « suive » le rythme du runtime de Containerd.
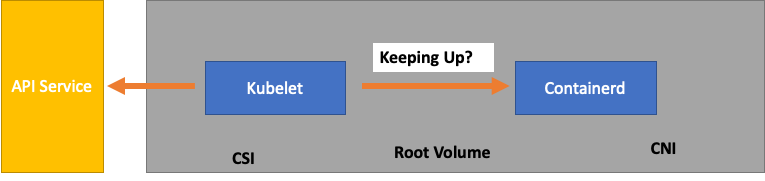
Pour simplifier à l'excès, le Kubelet obtient l'état des pods à partir du runtime du conteneur (dans notre cas, Containerd). Et si trop de pods changeaient de statut trop rapidement ? Si le taux de modification est trop élevé, les demandes [adressées au moteur d'exécution du conteneur] peuvent expirer.
Note
Kubernetes est en constante évolution, ce sous-système est actuellement en cours de modification. https://github.com/kubernetes/améliorations/problèmes/3386

Dans le graphique ci-dessus, nous voyons une ligne plate indiquant que nous venons d'atteindre la valeur du délai d'expiration pour la métrique de durée de génération des événements du cycle de vie du pod. Si vous souhaitez voir cela dans votre propre cluster, vous pouvez utiliser la syntaxe ProMQL suivante.
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
Si nous sommes témoins de ce comportement de temporisation, nous savons que nous avons poussé le nœud au-delà de la limite dont il était capable. Nous devons corriger la cause du délai d'attente avant de poursuivre. Cela peut être réalisé en réduisant le nombre de pods par nœud ou en recherchant les erreurs susceptibles de provoquer un volume élevé de tentatives (affectant ainsi le taux de désabonnement). L'important à retenir est que les métriques sont le meilleur moyen de comprendre si un nœud est capable de gérer le taux de désabonnement des pods assignés par rapport à l'utilisation d'un nombre fixe.
Échelle par métriques
Bien que le concept d'utilisation de métriques pour optimiser les systèmes soit ancien, il est souvent négligé lorsque les utilisateurs commencent leur parcours vers Kubernetes. Au lieu de nous concentrer sur des chiffres spécifiques (110 pods par nœud), nous concentrons nos efforts sur la recherche des indicateurs qui nous aident à identifier les goulots d'étranglement dans notre système. Comprendre les bons seuils pour ces indicateurs peut nous donner un degré élevé de confiance dans la configuration optimale de notre système.
L'impact des changements
Une tendance courante qui peut nous causer des problèmes consiste à nous concentrer sur la première erreur de métrique ou de journal qui semble suspecte. Lorsque nous avons constaté que le Kubelet avait expiré plus tôt, nous avons pu essayer des choses aléatoires, comme augmenter le taux par seconde que le Kubelet est autorisé à envoyer, etc. Cependant, il est sage de regarder la situation dans son ensemble en aval de l'erreur détectée en premier. Apportez chaque modification dans un but précis et en vous appuyant sur des données.
En aval du Kubelet se trouve le runtime Containerd (erreurs du pod), DaemonSets tel que le pilote de stockage (CSI) et le pilote réseau (CNI) qui communiquent avec l'API, etc. EC2
Continuons notre exemple précédent où le Kubelet ne suit pas le rythme du temps d'exécution. Il existe un certain nombre de points où nous pouvons regrouper un nœud si densément qu'il déclenche des erreurs.
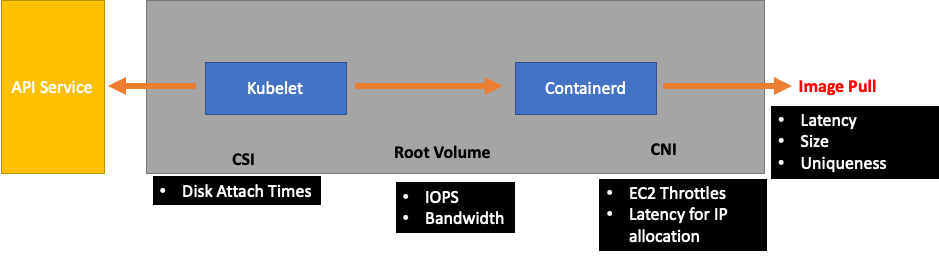
Lorsque nous concevons la bonne taille de nœud pour nos charges de travail, ces easy-to-overlook signaux peuvent exercer une pression inutile sur le système, limitant ainsi à la fois notre échelle et nos performances.
Le coût des erreurs inutiles
Les contrôleurs Kubernetes excellent lorsqu'il s'agit de réessayer en cas d'erreur, mais cela a un coût. Ces nouvelles tentatives peuvent augmenter la pression sur des composants tels que le Kube Controller Manager. La surveillance de telles erreurs est un élément important des tests à grande échelle.
Lorsque moins d'erreurs se produisent, il est plus facile de détecter les problèmes dans le système. En veillant régulièrement à ce que nos clusters soient exempts d'erreurs avant les opérations majeures (telles que les mises à niveau), nous pouvons simplifier les journaux de dépannage en cas d'événements imprévus.
Élargir notre vision
Dans les clusters à grande échelle comportant des milliers de nœuds, nous ne voulons pas rechercher les goulots d'étranglement individuellement. Dans ProMQL, nous pouvons trouver les valeurs les plus élevées d'un ensemble de données à l'aide d'une fonction appelée topk ; K étant une variable, nous plaçons le nombre d'éléments souhaités. Ici, nous utilisons trois nœuds pour savoir si tous les Kubelets du cluster sont saturés. Nous avons étudié la latence jusqu'à présent. Voyons maintenant si le Kubelet supprime les événements.
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
Décomposer cette déclaration.
-
Nous utilisons la variable Grafana pour nous
$__rate_intervalassurer qu'elle obtient les quatre échantillons dont elle a besoin. Cela permet de contourner un sujet complexe en matière de surveillance grâce à une variable simple. -
topkne nous donnez que les meilleurs résultats et le chiffre 3 limite ces résultats à trois. Il s'agit d'une fonction utile pour les métriques à l'échelle du cluster. -
{}dites-nous qu'il n'y a pas de filtres. Normalement, vous devez saisir le nom de la tâche quelle que soit la règle de scraping, mais comme ces noms varient, nous le laisserons vide.
Diviser le problème en deux
Pour remédier à un goulot d'étranglement dans le système, nous adopterons une approche qui consiste à trouver un indicateur indiquant l'existence d'un problème en amont ou en aval, car cela nous permettra de le diviser en deux. Ce sera également un principe fondamental de la façon dont nous affichons nos données métriques.
Le serveur d'API est un bon point de départ pour ce processus, car il nous permet de voir s'il y a un problème avec une application cliente ou avec le plan de contrôle.
