Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Efficacité des nœuds et des charges de travail
L'efficacité de nos charges de travail et de nos nœuds permet de réduire complexity/cost tout en augmentant les performances et l'évolutivité. De nombreux facteurs doivent être pris en compte lors de la planification de cette efficacité, et il est plus facile de penser en termes de compromis par rapport à un paramètre de meilleures pratiques pour chaque fonctionnalité. Examinons ces compromis en profondeur dans la section suivante.
Sélection du nœud
L'utilisation de nœuds légèrement plus grands (4 à 12 fois plus grands) augmente l'espace disponible pour faire fonctionner les pods, car cela réduit le pourcentage du nœud utilisé pour les « frais généraux », tels que les réserves
Note
Étant donné que k8s évolue horizontalement en règle générale, pour la plupart des applications, il n'est pas logique de prendre en compte l'impact sur les performances des nœuds de taille NUMA, d'où la recommandation d'une plage inférieure à cette taille de nœud.
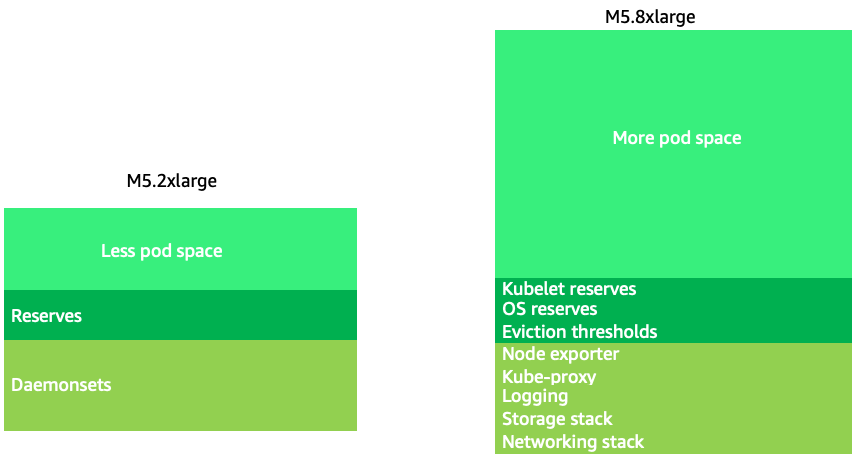
Les nœuds de grande taille nous permettent d'avoir un pourcentage plus élevé d'espace utilisable par nœud. Cependant, ce modèle peut être poussé à l'extrême en emballant le nœud avec un tel nombre de pods qu'il provoque des erreurs ou sature le nœud. La surveillance de la saturation des nœuds est essentielle pour utiliser avec succès des nœuds de plus grande taille.
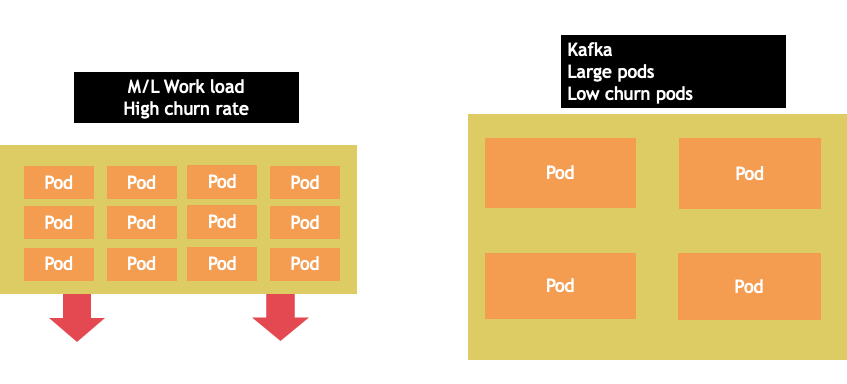
La sélection des nœuds est rarement une solution universelle. Il est souvent préférable de répartir les charges de travail présentant des taux de désabonnement radicalement différents entre différents groupes de nœuds. Les petites charges de travail par lots présentant un taux de désabonnement élevé seraient mieux prises en charge par la famille d'instances 4xlarge, tandis qu'une application à grande échelle telle que Kafka, qui utilise 8 vCPU et présente un faible taux de désabonnement, serait mieux servie par la famille 12xlarge.
Note
Un autre facteur à prendre en compte dans le cas de nœuds de très grande taille est que les CGROUPS ne cachent pas le nombre total de vCPU à l'application conteneurisée. Les environnements d'exécution dynamiques peuvent souvent générer un nombre involontaire de threads du système d'exploitation, ce qui crée une latence difficile à résoudre. Pour ces applications, l'épinglage du processeur
Nœud Bin-packing
Règles relatives à Kubernetes et à Linux
Nous devons tenir compte de deux ensembles de règles lorsque nous traitons des charges de travail sur Kubernetes. Les règles du planificateur Kubernetes, qui utilise la valeur de la requête pour planifier les pods sur un nœud, puis ce qui se passe une fois le pod planifié, relèvent du domaine de Linux, et non de Kubernetes.
Une fois le planificateur Kubernetes terminé, un nouvel ensemble de règles prend le relais, le Linux Completely Fair Scheduler (CFS). Le principal point à retenir est que Linux CFS n'a pas le concept de noyau. Nous expliquerons pourquoi une approche centrée sur les cœurs peut entraîner des problèmes majeurs liés à l'optimisation des charges de travail en vue de leur mise à l'échelle.
Penser en fonction des cœurs
La confusion commence parce que le planificateur Kubernetes utilise le concept de cœurs. Du point de vue du planificateur Kubernetes, si nous examinions un nœud avec 4 pods NGINX, chacun avec une demande d'un ensemble de cœurs, le nœud ressemblerait à ceci.
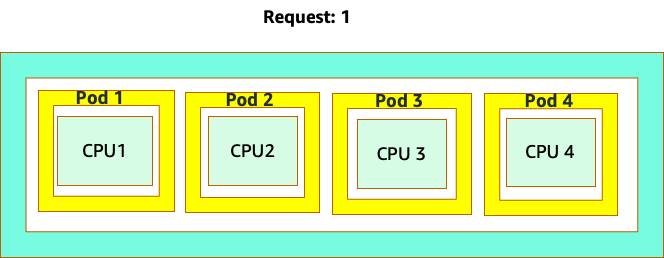
Cependant, faisons un essai de réflexion pour voir en quoi cela est différent du point de vue de Linux CFS. La chose la plus importante à retenir lorsque vous utilisez le système Linux CFS est que les conteneurs occupés (CGROUPS) sont les seuls conteneurs pris en compte dans le système de partage. Dans ce cas, seul le premier conteneur est occupé, il est donc autorisé à utiliser les 4 cœurs du nœud.
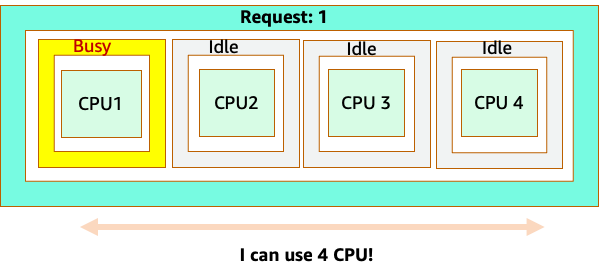
Pourquoi est-ce important ? Supposons que nous ayons effectué nos tests de performance dans un cluster de développement où une application NGINX était le seul conteneur occupé sur ce nœud. Lorsque nous passons l'application en production, voici ce qui se produit : l'application NGINX a besoin de 4 vCPU de ressources, mais comme tous les autres pods du nœud sont occupés, les performances de notre application sont limitées.
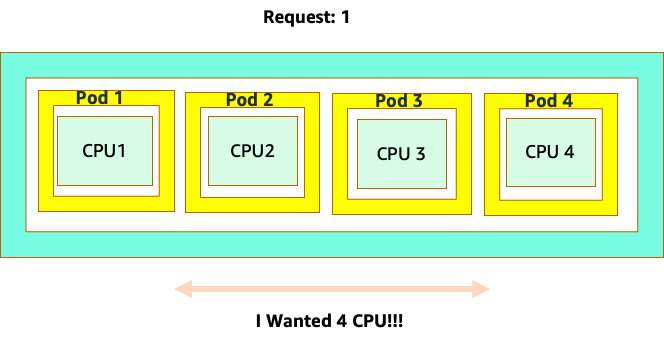
Cette situation nous conduirait à ajouter de nouveaux conteneurs inutilement, car nous ne permettions pas à nos applications d'atteindre leur « point idéal ». Explorons ce concept important d'un peu plus "sweet spot" en détail.
Dimensionnement adapté à l'application
Chaque application a un certain point où elle ne peut plus supporter de trafic. Le dépassement de ce point peut augmenter les délais de traitement et même réduire le trafic lorsqu'il est poussé bien au-delà de ce point. C'est ce que l'on appelle le point de saturation de l'application. Pour éviter les problèmes de mise à l'échelle, nous devons essayer de redimensionner l'application avant qu'elle n'atteigne son point de saturation. Appelons ce point le point idéal.
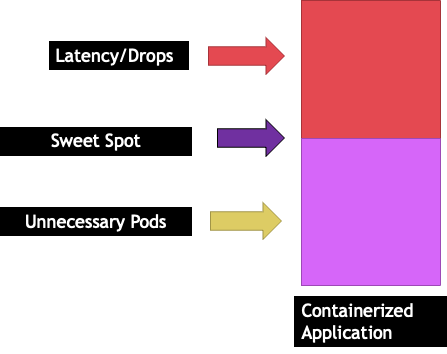
Nous devons tester chacune de nos applications pour comprendre leur point idéal. Il n'y aura pas de directives universelles ici car chaque application est différente. Au cours de ces tests, nous essayons de comprendre le meilleur indicateur indiquant le point de saturation de nos applications. Souvent, les métriques d'utilisation sont utilisées pour indiquer qu'une application est saturée, mais cela peut rapidement entraîner des problèmes de dimensionnement (nous aborderons cette rubrique en détail dans une section ultérieure). Une fois que nous aurons atteint ce « point idéal », nous pourrons l'utiliser pour augmenter efficacement nos charges de travail.
À l'inverse, que se passerait-il si nous agissions bien avant le point idéal et que nous créions des modules inutiles ? Découvrons-le dans la section suivante.
Étalement de la nacelle
Pour voir comment la création de modules inutiles peut rapidement devenir incontrôlable, examinons le premier exemple sur la gauche. L'échelle verticale correcte de ce conteneur utilise environ deux vCPU pour traiter 100 demandes par seconde. Cependant, si nous sous-provisionnions la valeur des demandes en définissant les demandes sur un demi-cœur, nous aurions désormais besoin de 4 modules pour chaque module dont nous avons réellement besoin. Ce problème est encore aggravé par le fait que si notre HPA
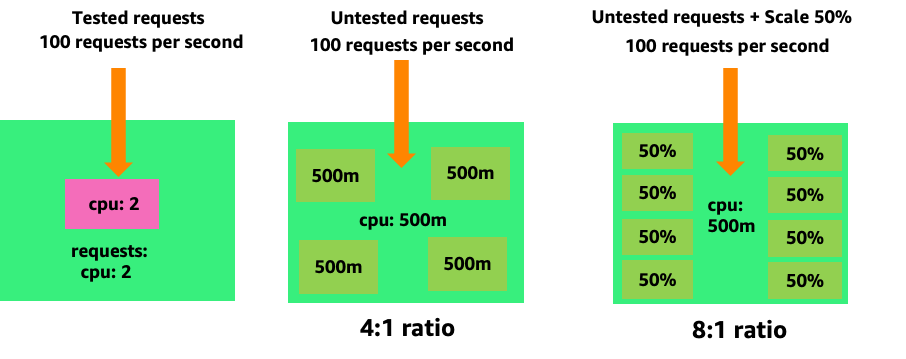
En aggravant ce problème, nous pouvons rapidement voir comment cela peut devenir incontrôlable. Un déploiement de dix modules dont le point idéal n'était pas réglé correctement pourrait rapidement atteindre 80 modules et l'infrastructure supplémentaire nécessaire pour les faire fonctionner.
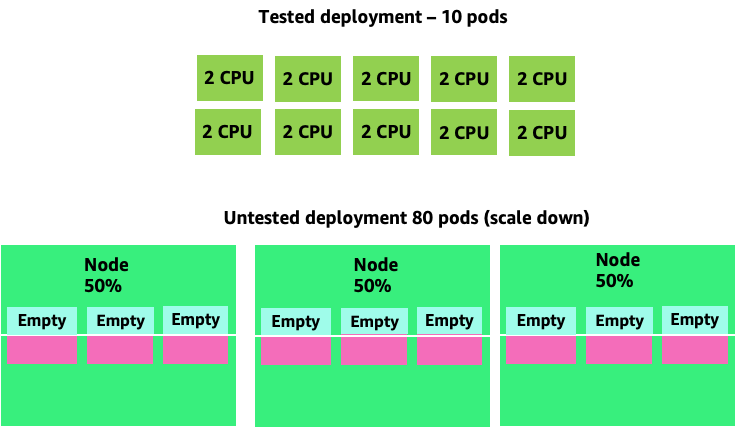
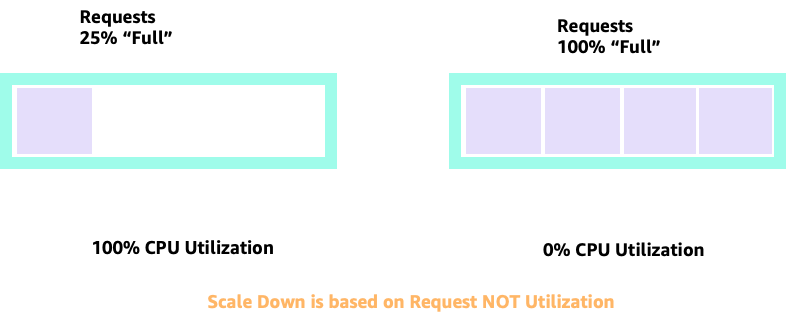
Maintenant que nous comprenons l'impact de ne pas autoriser les applications à fonctionner dans leur zone idéale, revenons au niveau des nœuds et demandons-nous pourquoi cette différence entre le planificateur Kubernetes et Linux CFS est si importante.
Lorsque nous augmentons ou diminuons avec HPA, nous pouvons avoir un scénario dans lequel nous disposons de beaucoup d'espace pour allouer plus de pods. Ce serait une mauvaise décision car le nœud représenté sur la gauche utilise déjà 100 % du processeur. Dans un scénario irréaliste mais théoriquement possible, nous pourrions avoir l'autre extrême où notre nœud est complètement plein, alors que l'utilisation de notre processeur est nulle.
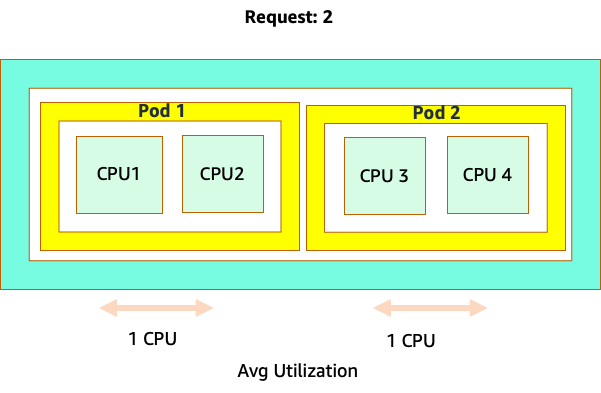
Configuration des demandes
Il serait tentant de définir la demande à la valeur « idéale » pour cette application, mais cela entraînerait des inefficiences, comme le montre le schéma ci-dessous. Ici, nous avons défini la valeur de la requête sur 2 vCPU, mais l'utilisation moyenne de ces pods ne fait fonctionner qu'un seul processeur la plupart du temps. Ce paramètre nous ferait perdre 50 % de nos cycles de processeur, ce qui serait inacceptable.
Cela nous amène à la réponse complexe au problème. L'utilisation des conteneurs ne peut être envisagée en vase clos ; il faut tenir compte des autres applications exécutées sur le nœud. Dans l'exemple suivant, les conteneurs surchargés sont mélangés à deux conteneurs à faible utilisation du processeur qui peuvent être limités en mémoire. De cette façon, nous permettons aux conteneurs d'atteindre leur point idéal sans surcharger le nœud.
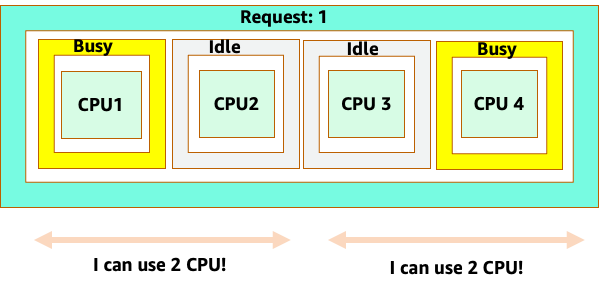
Le concept important à retenir de tout cela est que l'utilisation du concept de cœurs du planificateur Kubernetes pour comprendre les performances des conteneurs Linux peut entraîner de mauvaises prises de décisions car ils ne sont pas liés.
Note
Linux CFS a ses points forts. Cela est particulièrement vrai pour les charges de travail I/O basées. Toutefois, si votre application utilise des cœurs complets sans sidecars et qu'elle n'est pas I/O requise, l'épinglage du processeur peut considérablement compliquer ce processus. C'est pourquoi nous vous encourageons à le faire avec ces mises en garde.
Utilisation ou saturation
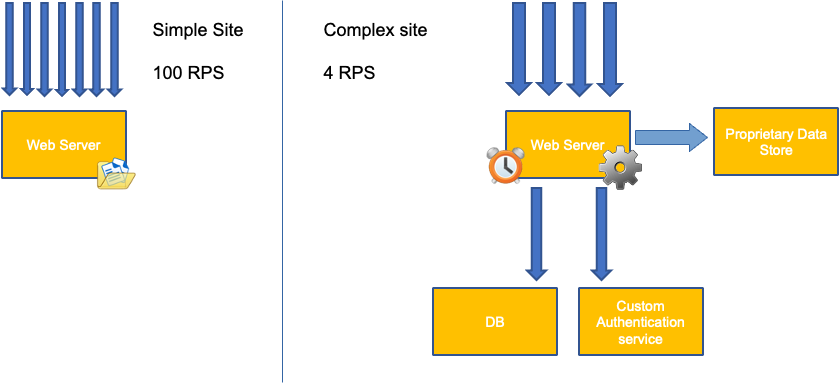
Une erreur courante lors de la mise à l'échelle des applications consiste à utiliser uniquement l'utilisation du processeur pour votre métrique de dimensionnement. Dans les applications complexes, il s'agit presque toujours d'un mauvais indicateur indiquant qu'une application est réellement saturée de demandes. Dans l'exemple de gauche, nous voyons que toutes nos requêtes arrivent réellement sur le serveur Web. L'utilisation du processeur suit donc bien le rythme de saturation.
Dans les applications du monde réel, il est probable que certaines de ces demandes soient traitées par une couche de base de données ou une couche d'authentification, etc. Dans ce cas plus courant, notez que le processeur ne suit pas la saturation car la demande est traitée par d'autres entités. Dans ce cas, le processeur est un très mauvais indicateur de saturation.
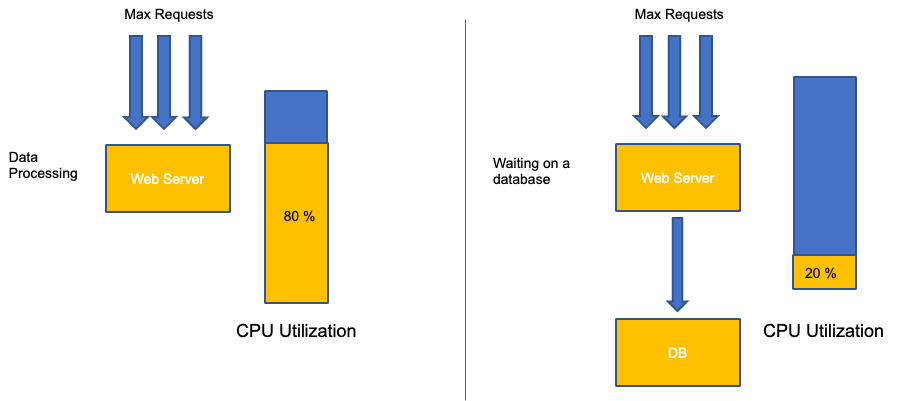
L'utilisation d'une métrique incorrecte dans les performances des applications est la principale raison du dimensionnement inutile et imprévisible de Kubernetes. Il faut choisir avec soin la bonne métrique de saturation pour le type d'application que vous utilisez. Il est important de noter qu'il n'existe pas de recommandation universelle qui puisse être donnée. En fonction de la langue utilisée et du type d'application en question, il existe un ensemble varié de mesures de saturation.
Nous pouvons penser que ce problème ne concerne que l'utilisation du processeur, mais d'autres métriques courantes, telles que le nombre de demandes par seconde, peuvent également être confrontées exactement au même problème que celui décrit ci-dessus. Notez que la demande peut également être envoyée aux couches de base de données, aux couches d'authentification, sans être directement traitée par notre serveur Web. Il s'agit donc d'une mauvaise métrique pour une véritable saturation du serveur Web lui-même.
Malheureusement, il n'existe pas de réponse facile lorsqu'il s'agit de choisir la bonne métrique de saturation. Voici quelques directives à prendre en compte :
-
Comprenez votre langage d'exécution : les langages dotés de plusieurs threads de système d'exploitation réagiront différemment des applications à thread unique, ce qui aura un impact différent sur le nœud.
-
Comprenez l'échelle verticale correcte : quelle quantité de mémoire tampon souhaitez-vous pour que vos applications mettent à l'échelle verticale avant de redimensionner un nouveau pod ?
-
Quelles mesures reflètent réellement la saturation de votre application ? La métrique de saturation d'un Kafka Producer serait très différente de celle d'une application Web complexe.
-
Comment toutes les autres applications du nœud s'influencent-elles ? Les performances des applications ne se font pas en vase clos, les autres charges de travail du nœud ont un impact majeur.
Pour clore cette section, il serait facile de rejeter ce qui précède en le qualifiant de trop complexe et inutile. Il arrive souvent que nous rencontrions un problème, mais nous n'en connaissons pas la véritable nature car nous examinons les mauvais indicateurs. Dans la section suivante, nous verrons comment cela pourrait se produire.
Saturation des nœuds
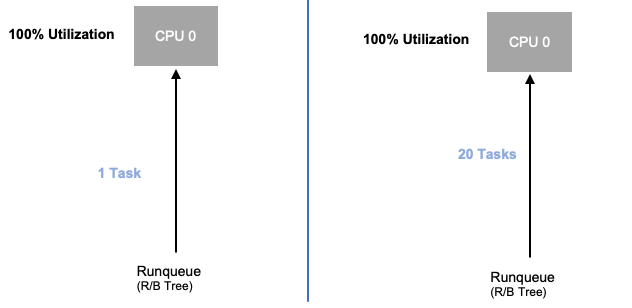
Maintenant que nous avons exploré la saturation des applications, examinons ce même concept du point de vue des nœuds. Prenons deux processeurs utilisés à 100 % pour voir la différence entre l'utilisation et la saturation.
Le vCPU de gauche est utilisé à 100 %, mais aucune autre tâche n'attend d'être exécutée sur ce vCPU, donc d'un point de vue purement théorique, c'est très efficace. Entre-temps, dans le deuxième exemple, 20 applications à thread unique attendent d'être traitées par un vCPU. Les 20 applications seront désormais confrontées à un certain type de latence en attendant leur tour pour être traitées par le vCPU. En d'autres termes, le vCPU de droite est saturé.
Non seulement nous ne verrions pas ce problème si nous nous contentons d'examiner l'utilisation, mais nous pourrions également attribuer cette latence à un élément sans rapport, tel que le réseau, ce qui nous conduirait sur la mauvaise voie.
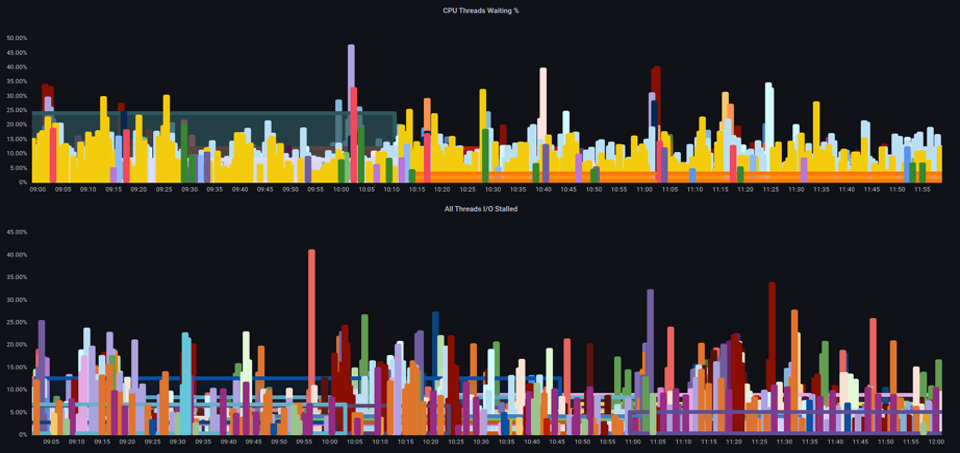
Il est important de consulter les métriques de saturation, et pas seulement les métriques d'utilisation, lorsque vous augmentez le nombre total de pods exécutés sur un nœud à un moment donné, car nous pouvons facilement passer à côté du fait que nous avons sursaturé un nœud. Pour cette tâche, nous pouvons utiliser les mesures d'information relatives au décrochage sous pression, comme indiqué dans le graphique ci-dessous.
ProMQL - Bloqué I/O
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
Note
Pour en savoir plus sur les mesures de décrochage sous pression, voir https://facebookmicrosites.github.io/psi/docs/overview *
Avec ces métriques, nous pouvons savoir si les threads attendent le processeur, ou même si chaque thread de la boîte est bloqué en attendant une ressource telle que la mémoire ou I/O. Par exemple, nous avons pu voir quel pourcentage chaque thread de l'instance était bloqué en I/O attente pendant une minute.
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
À l'aide de cette métrique, nous pouvons voir dans le graphique ci-dessus que chaque thread était bloqué 45 % du temps d'attente I/O au point culminant, ce qui signifie que nous avons gâché tous ces cycles de processeur au cours de cette minute. Le fait de comprendre que cela se produit peut nous aider à gagner beaucoup de temps sur le vCPU, rendant ainsi le dimensionnement plus efficace.
HPA V2
Il est recommandé d'utiliser la autoscaling/v2 version de l'API HPA. Les anciennes versions de l'API HPA pouvaient être bloquées dans certains cas extrêmes. Cela était également limité au fait que les pods ne doublaient que lors de chaque étape de mise à l'échelle, ce qui créait des problèmes pour les petits déploiements nécessitant une mise à l'échelle rapide.
Autoscaling/v2 nous donne plus de flexibilité pour inclure plusieurs critères sur lesquels nous pouvons évoluer et nous donne une grande flexibilité lors de l'utilisation de métriques personnalisées et externes (métriques non K8s).
À titre d'exemple, nous pouvons effectuer une mise à l'échelle sur la plus haute des trois valeurs (voir ci-dessous). Nous effectuons une mise à l'échelle si l'utilisation moyenne de tous les pods est supérieure à 50 %, si les métriques personnalisées indiquent que le nombre de paquets par seconde d'entrée dépasse une moyenne de 1 000 ou si le nombre d'objets entrants dépasse 10 000 demandes par seconde.
Note
C'est juste pour montrer la flexibilité de l'API d'auto-scaling. Nous vous recommandons d'éviter les règles trop complexes qui peuvent être difficiles à résoudre en production.
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
Cependant, nous avons découvert le danger d'utiliser de tels indicateurs pour des applications Web complexes. Dans ce cas, nous serions mieux servis en utilisant des métriques personnalisées ou externes qui reflètent avec précision la saturation de notre application par rapport à son utilisation. HPAv2 permet cela en ayant la capacité d'évoluer en fonction de n'importe quelle métrique, mais nous devons toujours trouver et exporter cette métrique vers Kubernetes pour l'utiliser.
Par exemple, nous pouvons examiner le nombre de files d'attente de threads actifs dans Apache. Cela crée souvent un profil de mise à l'échelle « plus fluide » (nous reviendrons bientôt sur ce terme). Si un thread est actif, peu importe qu'il attende une couche de base de données ou qu'il réponde à une demande localement. Si tous les threads de l'application sont utilisés, c'est une bonne indication que l'application est saturée.
Nous pouvons utiliser cet épuisement des threads comme signal pour créer un nouveau pod avec un pool de threads entièrement disponible. Cela nous permet également de contrôler la taille de la mémoire tampon que nous voulons que l'application absorbe en période de trafic intense. Par exemple, si nous avions un pool total de 10 threads, la mise à l'échelle à 4 threads utilisés contre 8 threads utilisés aurait un impact majeur sur la mémoire tampon dont nous disposons lors du dimensionnement de l'application. Un paramètre de 4 serait judicieux pour une application qui doit évoluer rapidement sous une charge importante, alors qu'un paramètre de 8 serait plus efficace avec nos ressources si nous avions suffisamment de temps pour le faire, étant donné que le nombre de demandes augmente lentement plutôt que fortement au fil du temps.
Qu'entendons-nous par le terme « fluide » lorsqu'il est question de mise à l'échelle ? Notez le graphique ci-dessous où nous utilisons le processeur comme métrique. Dans le cadre de ce déploiement, le nombre de capsules augmente en peu de temps, passant de 50 à 250 unités, pour ensuite être immédiatement réduites à nouveau. Cette mise à l'échelle très inefficace est la principale cause du taux de désabonnement des clusters.
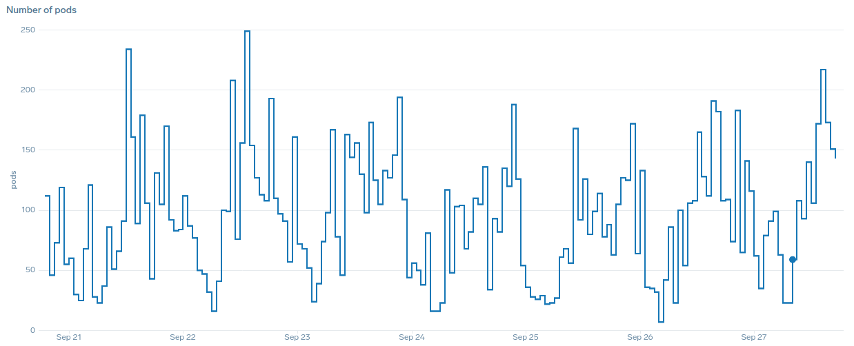
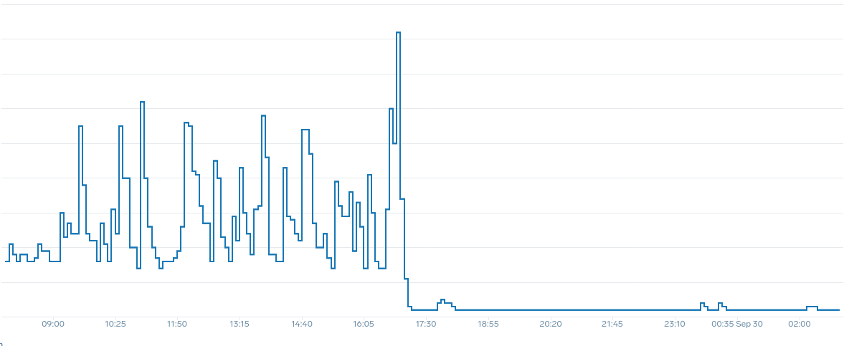
Remarquez qu'une fois que nous avons opté pour une métrique qui reflète le point idéal de notre application (partie centrale du graphique), nous sommes en mesure de procéder à une mise à l'échelle fluide. Notre mise à l'échelle est désormais efficace et nos pods peuvent s'adapter pleinement à la marge de manœuvre que nous avons fournie en ajustant les paramètres des demandes. Aujourd'hui, un petit groupe de capsules effectue le travail que des centaines de capsules effectuaient auparavant. Les données réelles montrent qu'il s'agit du principal facteur d'évolutivité des clusters Kubernetes.
Le principal point à retenir est que l'utilisation du processeur n'est qu'une dimension des performances des applications et des nœuds. L'utilisation du processeur comme seul indicateur de santé pour nos nœuds et applications pose des problèmes d'évolutivité, de performance et de coût, qui sont tous des concepts étroitement liés. Plus l'application et les nœuds sont performants, moins vous avez besoin d'évolutivité, ce qui réduit vos coûts.
La recherche et l'utilisation des mesures de saturation appropriées pour le dimensionnement de votre application particulière vous permettent également de surveiller les véritables goulots d'étranglement de cette application et de vous en avertir. Si cette étape critique est ignorée, les rapports faisant état de problèmes de performances seront difficiles, voire impossibles, à comprendre.
Configuration des limites du processeur
Pour compléter cette section sur les sujets mal compris, nous aborderons les limites du processeur. En bref, les limites sont des métadonnées associées au conteneur dont le compteur est réinitialisé toutes les 100 ms. Cela permet à Linux de suivre le nombre de ressources du processeur utilisées à l'échelle d'un nœud par un conteneur spécifique sur une période de 100 ms.
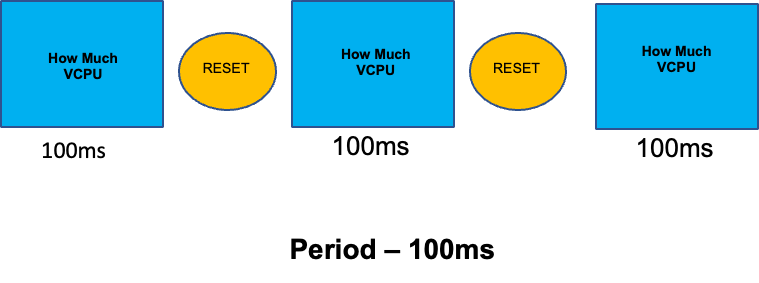
Une erreur courante lors de la définition des limites est de supposer que l'application est mono-thread et ne s'exécute que sur son vCPU « assigné ». Dans la section ci-dessus, nous avons appris que le CFS n'attribue pas de cœurs et qu'en réalité, un conteneur exécutant de grands pools de threads planifie l'utilisation de tous les vCPU disponibles sur le boîtier.
Si 64 threads du système d'exploitation s'exécutent sur 64 cœurs disponibles (du point de vue d'un nœud Linux), le temps processeur total utilisé sur une période de 100 ms sera assez élevé une fois le temps passé sur l'ensemble de ces 64 cœurs additionné. Comme cela ne se produit que pendant un processus de collecte des ordures, il peut être assez facile de rater quelque chose comme ça. C'est pourquoi il est nécessaire d'utiliser des métriques pour s'assurer que l'utilisation est correcte au fil du temps avant de tenter de fixer une limite.
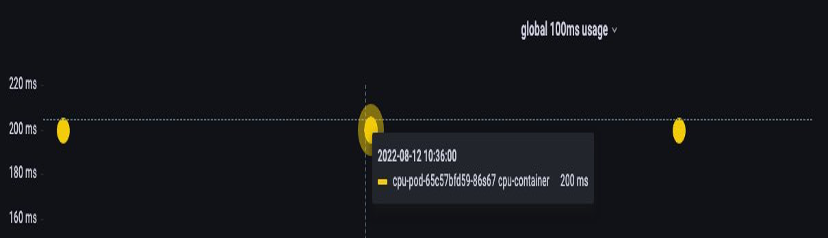
Heureusement, nous avons un moyen de voir exactement quelle quantité de vCPU est utilisée par tous les threads d'une application. Nous utiliserons la métrique container_cpu_usage_seconds_total à cette fin.
Comme la logique de régulation se produit toutes les 100 ms et que cette métrique est une métrique par seconde, nous allons ProMQL pour qu'il corresponde à cette période de 100 ms. Si vous souhaitez approfondir ce travail de déclaration ProMQL, veuillez consulter le blog suivant.
Requête ProMQL :
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

Une fois que nous avons le sentiment d'avoir la bonne valeur, nous pouvons fixer des limites à la production. Il devient alors nécessaire de voir si notre application est bloquée en raison d'un imprévu. Nous pouvons le faire en regardant container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
Mémoire
L'allocation de mémoire est un autre exemple où il est facile de confondre le comportement de planification de Kubernetes avec le comportement de Linux CGroup. Il s'agit d'un sujet plus nuancé car des changements majeurs ont été apportés à la façon dont CGroup v2 gère la mémoire sous Linux et Kubernetes a modifié sa syntaxe pour refléter cela ; lisez ce blog pour plus de détails.
Contrairement aux demandes du processeur, les demandes de mémoire ne sont pas utilisées une fois le processus de planification terminé. En effet, nous ne pouvons pas compresser la mémoire dans CGroup v1 de la même manière qu'avec le processeur. Cela ne nous laisse que des limites de mémoire, conçues pour empêcher les fuites de mémoire en mettant complètement le module hors service. Il s'agit d'une proposition de style « tout ou rien », mais nous avons maintenant de nouvelles façons de résoudre ce problème.
Tout d'abord, il est important de comprendre que définir la bonne quantité de mémoire pour les conteneurs n'est pas aussi simple qu'il y paraît. Le système de fichiers sous Linux utilisera la mémoire comme cache pour améliorer les performances. Ce cache augmentera au fil du temps, et il peut être difficile de savoir quelle quantité de mémoire est utile pour le cache, mais qui peut être récupérée sans que cela ait un impact significatif sur les performances des applications. Cela entraîne souvent une mauvaise interprétation de l'utilisation de la mémoire.
La capacité de « compresser » la mémoire était l'un des principaux moteurs de CGroup v2. Pour en savoir plus sur les raisons pour lesquelles CGroup V2 était nécessaire, veuillez consulter la présentation
Heureusement, Kubernetes possède désormais le concept de memory.min et en dessous. memory.high requests.memory Cela nous donne la possibilité de libérer de manière agressive cette mémoire cache pour que d'autres conteneurs puissent l'utiliser. Une fois que le conteneur atteint la limite maximale de mémoire, le noyau peut récupérer agressivement la mémoire de ce conteneur jusqu'à la valeur définie à. memory.min Cela nous donne plus de flexibilité lorsqu'un nœud est soumis à une pression de mémoire.
La question clé est la suivante : à quelle valeur memory.min définir ? C'est là que les métriques de blocage de la mémoire entrent en jeu. Nous pouvons utiliser ces métriques pour détecter le « battement » de mémoire au niveau du conteneur. Ensuite, nous pouvons utiliser des contrôleurs tels que fbtaxmemory.min en recherchant ce battement de mémoire, et définir dynamiquement la memory.min valeur sur ce paramètre.
Résumé
Pour résumer la section, il est facile de confondre les concepts suivants :
-
Utilisation et saturation
-
Règles de performance Linux avec la logique du planificateur Kubernetes
Il faut prendre grand soin de séparer ces concepts. La performance et l'échelle sont étroitement liées. Une mise à l'échelle inutile crée des problèmes de performance, qui à leur tour créent des problèmes de dimensionnement.
