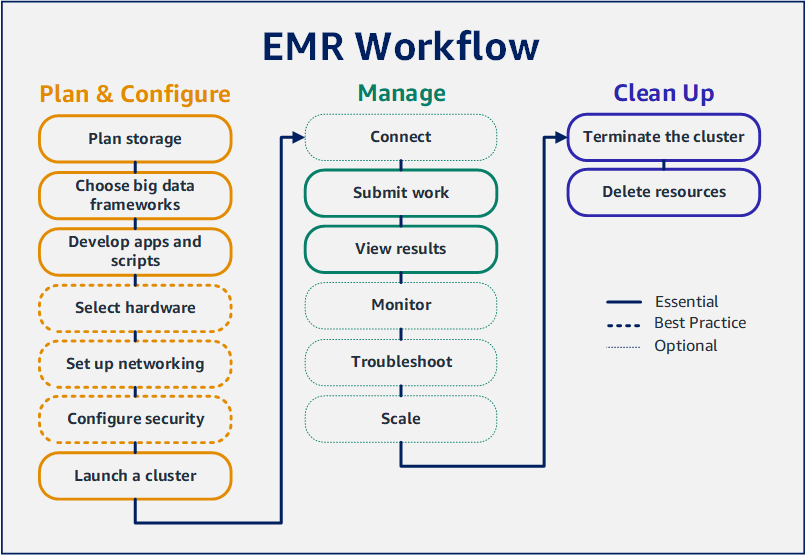
Didacticiel : Les premiers pas avec Amazon EMR
Présentation
Avec Amazon EMR, vous pouvez configurer un cluster pour traiter et analyser des données avec des environnements de big data en quelques minutes seulement. Ce didacticiel explique comment lancer un exemple de cluster à l'aide de Spark et comment exécuter un script PySpark simple stocké dans un compartiment Amazon S3. Il couvre les tâches essentielles d'Amazon EMR dans trois catégories principales de flux de travail : planification et configuration, gestion et nettoyage.
Vous trouverez des liens vers des sujets plus détaillés au fur et à mesure que vous avancerez dans le didacticiel, ainsi que des idées d'étapes supplémentaires dans la section Étapes suivantes. Si vous avez des questions ou rencontrez des difficultés, contactez l'équipe d'Amazon EMR sur notre Forum de discussion.
Coût
-
L'exemple de cluster que vous créez s'exécute dans un environnement en direct. Le cluster enregistre des frais minimes. Pour éviter des frais supplémentaires, assurez-vous d'effectuer les tâches de nettoyage de la dernière étape de ce didacticiel. Les frais sont calculés au tarif par seconde conformément à la tarification Amazon EMR. Les frais varient également selon la région. Pour de plus amples informations, consultez la tarification Amazon EMR.
-
Des frais minimes pourraient s'accumuler pour les petits fichiers que vous stockez dans Amazon S3. Certains ou tous les frais d'Amazon S3 peuvent être annulés si vous ne dépassez pas les limites d'utilisation du niveau gratuit AWS. Pour plus d'informations, consultez la rubrique Tarification Amazon S3 et Niveau gratuit AWS.
Préparation du stockage pour Amazon EMR
Lorsque vous utilisez Amazon EMR, vous pouvez choisir parmi différents systèmes de fichiers pour stocker les données d'entrée, les données de sortie et les fichiers journaux. Dans ce didacticiel, vous utilisez EMRFS pour stocker des données dans un compartiment S3. EMRFS est une implémentation du système de fichiers Hadoop qui permet de lire et d'écrire des fichiers normaux sur Amazon S3. Pour de plus amples informations, veuillez consulter Gestion du stockage et des systèmes de fichiers.
Pour créer un compartiment pour ce didacticiel, suivez les instructions de la rubrique Comment créer un compartiment S3 ? dans le Guide de l'utilisateur de la console Amazon Simple Storage Service. Créez le compartiment dans la région AWS où vous souhaitez lancer votre cluster Amazon EMR. Par exemple, USA Ouest (Oregon) us-west-2.
Les compartiments et dossiers que vous utilisez avec Amazon EMR présentent les limites suivantes :
-
Les noms peuvent être composés de lettres minuscules, de chiffres, de points (.) et de traits d'union (-).
-
Les noms ne peuvent pas se terminer par des chiffres.
-
Le nom d'un compartiment doit être unique pour tous les comptes AWS.
-
Le dossier de sortie doit être vide.
Préparation d'une application avec des données d'entrée pour Amazon EMR
La façon la plus courante de préparer une application pour Amazon EMR consiste à télécharger l'application et ses données d'entrée sur Amazon S3. Ensuite, lorsque vous soumettez du travail à votre cluster, vous indiquez les emplacements Amazon S3 pour votre script et vos données.
Dans cette étape, vous téléchargez un exemple de script PySpark dans votre compartiment Amazon S3. Nous vous avons fourni un script PySpark que vous pouvez utiliser. Le script traite les données d'inspection des établissements alimentaires et renvoie un fichier de résultats dans votre compartiment S3. Le fichier des résultats répertorie les dix établissements ayant enregistré le plus grand nombre d'infractions de type « rouge ».
Vous chargez également des exemples de données d'entrée sur Amazon S3 pour que le script PySpark les traite. Les données d'entrée sont une version modifiée des résultats des inspections effectuées par le ministère de la Santé du comté de King, Washington, entre 2006 et 2020. Pour plus d'informations, consultez la rubrique Données ouvertes du comté de King : données sur l'inspection des établissements alimentaires. Voici des exemples de lignes du jeu de données.
name, inspection_result, inspection_closed_business, violation_type, violation_points
100 LB CLAM, Unsatisfactory, FALSE, BLUE, 5
100 PERCENT NUTRICION, Unsatisfactory, FALSE, BLUE, 5
7-ELEVEN #2361-39423A, Complete, FALSE, , 0
Préparation de l'exemple de script PySpark pour EMR
-
Copiez l'exemple de code ci-dessous dans un nouveau fichier dans l'éditeur de votre choix.
import argparse
from pyspark.sql import SparkSession
def calculate_red_violations(data_source, output_uri):
"""
Processes sample food establishment inspection data and queries the data to find the top 10 establishments
with the most Red violations from 2006 to 2020.
:param data_source: The URI of your food establishment data CSV, such as 's3://DOC-EXAMPLE-BUCKET/food-establishment-data.csv'.
:param output_uri: The URI where output is written, such as 's3://DOC-EXAMPLE-BUCKET/restaurant_violation_results'.
"""
with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark:
# Load the restaurant violation CSV data
if data_source is not None:
restaurants_df = spark.read.option("header", "true").csv(data_source)
# Create an in-memory DataFrame to query
restaurants_df.createOrReplaceTempView("restaurant_violations")
# Create a DataFrame of the top 10 restaurants with the most Red violations
top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations
FROM restaurant_violations
WHERE violation_type = 'RED'
GROUP BY name
ORDER BY total_red_violations DESC LIMIT 10""")
# Write the results to the specified output URI
top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.")
parser.add_argument(
'--output_uri', help="The URI where output is saved, like an S3 bucket location.")
args = parser.parse_args()
calculate_red_violations(args.data_source, args.output_uri)
-
Enregistrez le fichier sous le nom health_violations.py.
-
Chargez health_violations.py sur Amazon S3 dans le compartiment que vous avez créé pour ce didacticiel. Pour obtenir des instructions, consultez la rubrique Chargement d'un objet dans un compartiment dans le Guide de démarrage Amazon Simple Storage Service.
Préparation des exemples de données d'entrée pour EMR
-
Téléchargez le fichier zip food_establishment_data.zip.
-
Décompressez et enregistrez food_establishment_data.zip sous le nom food_establishment_data.csv sur votre machine.
-
Chargez le fichier CSV sur Amazon S3 dans le compartiment que vous avez créé pour ce didacticiel. Pour obtenir des instructions, consultez la rubrique Chargement d'un objet dans un compartiment dans le Guide de démarrage Amazon Simple Storage Service.
Pour plus d'informations sur la configuration des données pour EMR, consultez Préparation des données d'entrée.
Lancement d'un cluster Amazon EMR
Après avoir préparé un emplacement de stockage et votre application, vous pouvez lancer un exemple de cluster Amazon EMR. Au cours de cette étape, vous lancez un cluster Apache Spark à l'aide de la dernière version d'Amazon EMR.
- New console
-
Lancement d'un cluster avec Spark installé à l'aide de la nouvelle console
-
Connectez-vous à la AWS Management Console et ouvrez la console Amazon EMR à l'adresse https://console.aws.amazon.com/emr.
-
Dans le volet de navigation, sous EMR on EC2, sélectionnez Clusters, puis Créer un cluster.
-
Sur la page Créer un cluster, notez les valeurs par défaut pour la version, le type d'instance, le nombre d'instances et les autorisations. Ces champs sont automatiquement renseignés avec des valeurs qui fonctionnent pour les clusters à usage général.
-
Dans le champ Nom du cluster, saisissez un nom de cluster unique pour vous aider à identifier votre cluster, tel que Mon premier cluster.
-
Sous Applications, choisissez l'option Spark pour installer Spark sur votre cluster.
Choisissez les applications que vous souhaitez installer sur votre cluster Amazon EMR avant de lancer ce cluster. Il est impossible d'ajouter ou de supprimer des applications d'un cluster après son lancement.
-
Sous Journaux du cluster, cochez la case Publier les journaux spécifiques au cluster sur Amazon S3. Remplacez la valeur de l'emplacement Amazon S3 par le compartiment Amazon S3 que vous avez créé, suivi de /logs. Par exemple, s3://DOC-EXAMPLE-BUCKET/logs. L'ajout de /logs crée un nouveau dossier appelé « journaux » dans votre compartiment, dans lequel Amazon EMR peut copier les fichiers journaux de votre cluster.
-
Sous Configuration de sécurité et autorisations, choisissez votre paire de clés EC2. Dans la même section, sélectionnez le menu déroulant Fonction du service pour Amazon EMR, puis choisissez EMR_DefaultRole. Sélectionnez ensuite le menu déroulant du rôle IAM pour le profil d'instance et choisissez EMR_EC2_DefaultRole.
-
Choisissez Créer un cluster pour lancer le cluster et ouvrir la page des détails du cluster.
-
Trouvez l'état du cluster à côté du nom du cluster. L'état passe de En cours de démarrage à En cours d'exécution, puis à En attente, à mesure qu'Amazon EMR approvisionne le cluster. Vous devrez peut-être choisir l'icône d'actualisation sur la droite ou actualiser votre navigateur pour voir les mises à jour de l'état.
L'état de votre cluster passe à En attente lorsque le cluster est opérationnel et prêt à accepter du travail. Pour plus d'informations sur la lecture d'un résumé de cluster, consultez Afficher l'état et les détails d'un cluster. Pour plus d'informations sur l'état du cluster, consultez Présentation du cycle de vie du cluster.
- Old console
-
Lancement d'un cluster avec Spark installé à l'aide de l'ancienne console
Accédez à la nouvelle console Amazon EMR et sélectionnez Basculer vers l'ancienne console depuis le menu latéral. Pour plus d'informations sur ce qui vous attend lorsque vous passez à l'ancienne console, consultez la rubrique Utilisation de l'ancienne console.
-
Choisissez Créer un cluster pour ouvrir l'assistant d'options rapides.
-
Sur la page Créer un cluster - Options rapides, notez les valeurs par défaut pour la version, le type d'instance, le nombre d'instances et les autorisations. Ces champs se remplissent automatiquement avec des valeurs qui conviennent aux clusters à usage général.
-
Saisissez un nom de cluster pour vous aider à identifier le cluster. Par exemple, Mon premier cluster.
-
Laissez la journalisation activée, mais remplacez la valeur du dossier S3 par le compartiment Amazon S3 que vous avez créé, suivi de /logs. Par exemple, s3://DOC-EXAMPLE-BUCKET/logs. L'ajout de /logs crée un nouveau dossier appelé « journaux » dans votre compartiment, dans lequel EMR peut copier les fichiers journaux de votre cluster.
-
Choisissez l'option Spark sous Applications pour installer Spark sur votre cluster.
Choisissez les applications que vous souhaitez installer sur votre cluster Amazon EMR avant de lancer ce cluster. Il est impossible d'ajouter ou de supprimer des applications d'un cluster après son lancement.
-
Sous Sécurité et accès, choisissez votre paire de clés EC2.
-
Choisissez Créer un cluster pour lancer le cluster et ouvrir la page d'état du cluster.
-
Trouvez l'état du cluster à côté du nom du cluster. L'état passe de En cours de démarrage à En cours d'exécution, puis à En attente, à mesure qu'Amazon EMR approvisionne le cluster. Vous devrez peut-être choisir l'icône d'actualisation sur la droite ou actualiser votre navigateur pour voir les mises à jour de l'état.
L'état de votre cluster passe à En attente lorsque le cluster est opérationnel et prêt à accepter du travail. Pour plus d'informations sur la lecture d'un résumé de cluster, consultez Afficher l'état et les détails d'un cluster. Pour plus d'informations sur l'état du cluster, consultez Présentation du cycle de vie du cluster.
- CLI
-
Lancement d'un cluster avec Spark installé à l'aide de la AWS CLI
-
Créez des rôles IAM par défaut que vous pouvez ensuite utiliser pour créer votre cluster à l'aide de la commande suivante.
aws emr create-default-roles
Pour plus d'informations sur create-default-roles, consultez la rubrique Référence des commandes de la AWS CLI.
-
Créez un cluster Spark à l'aide de la commande suivante. Saisissez le nom de votre cluster à l'aide de l'option --name et indique le nom de votre paire de clés EC2 à l'aide de l'option --ec2-attributes.
aws emr create-cluster \
--name "<My First EMR Cluster>" \
--release-label <emr-5.36.1> \
--applications Name=Spark \
--ec2-attributes KeyName=<myEMRKeyPairName> \
--instance-type m5.xlarge \
--instance-count 3 \
--use-default-roles
Notez les autres valeurs requises pour --instance-type, --instance-count et --use-default-roles. Ces valeurs ont été choisies pour les clusters à usage général. Pour plus d'informations sur create-cluster, consultez la rubrique Référence des commandes de la AWS CLI.
Les caractères de continuation de ligne Linux (\) sont inclus pour des raisons de lisibilité. Ils peuvent être supprimés ou utilisés dans les commandes Linux. Pour Windows, supprimez-les ou remplacez-les par un caret (^).
Vous devriez voir une sortie semblable à la suivante. Le résultat généré indique le ClusterId et le ClusterArn de votre nouveau cluster. Notez votre ClusterId. Vous utilisez le ClusterId pour vérifier l'état du cluster et pour soumettre des travaux.
{
"ClusterId": "myClusterId",
"ClusterArn": "myClusterArn"
}
-
Vérifiez l'état de votre cluster à l'aide de la commande suivante.
aws emr describe-cluster --cluster-id <myClusterId>
Vous devriez voir un résultat comme le suivant avec l'objet Status de votre nouveau cluster.
{
"Cluster": {
"Id": "myClusterId",
"Name": "My First EMR Cluster",
"Status": {
"State": "STARTING",
"StateChangeReason": {
"Message": "Configuring cluster software"
}
}
}
}
La valeur State passe de STARTING à RUNNING, puis à WAITING, lorsqu'Amazon EMR approvisionne le cluster.
L'état du cluster passe à WAITING lorsque le cluster est opérationnel et prêt à accepter du travail. Pour plus d'informations sur l'état du cluster, consultez Présentation du cycle de vie du cluster.
Étape 2 : Gérer votre cluster Amazon EMR
Soumission de travail à Amazon EMR
Après avoir lancé un cluster, vous pouvez soumettre du travail au cluster en cours d'exécution pour traiter et analyser des données. Vous soumettez votre travail à un cluster Amazon EMR en tant qu'étape. L'étape est une unité de travail composée d'une ou plusieurs actions. Par exemple, vous pouvez soumettre une étape pour calculer des valeurs ou pour transférer et traiter des données. Vous pouvez soumettre des étapes lors de la création d'un cluster ou à un cluster en cours d'exécution. Dans cette partie du didacticiel, vous soumettez health_violations.py en tant qu'étape à votre cluster en cours d'exécution. Pour en savoir plus sur les étapes, consultez Soumission de travail à un cluster.
- New console
-
Soumission d'une application Spark en tant qu'étape à l'aide de la nouvelle console
-
Connectez-vous à la AWS Management Console et ouvrez la console Amazon EMR à l'adresse https://console.aws.amazon.com/emr.
-
Dans le volet de navigation de gauche, sous EMR on EC2, choisissez Clusters, puis sélectionnez le cluster dans lequel vous souhaitez soumettre du travail. L'état du cluster doit être En attente.
-
Sélectionnez l'onglet Étapes, puis sélectionnez Ajouter une étape.
-
Configurez l'étape en fonction des consignes suivantes :
-
Pour Type, choisissez Application Spark. Vous devriez voir des champs supplémentaires pour le mode de déploiement, l'emplacement de l'application et les options Spark-submit.
-
Dans le champ Nom, saisissez un nouveau nom. Si vous avez de nombreuses étapes dans un cluster, le fait de nommer chaque étape vous aide à en garder la trace.
-
Pour le mode de déploiement, laissez la valeur par défaut Mode cluster. Pour plus d'informations sur les modes de déploiement de Spark, consultez la rubrique Présentation du mode cluster dans la documentation Apache Spark.
-
Dans le champ Emplacement de l'application, saisissez l'emplacement de votre script health_violations.py dans Amazon S3, par exemple s3://DOC-EXAMPLE-BUCKET/health_violations.py.
-
Laissez le champ des options Spark-submit vide. Pour plus d'informations sur les options spark-submit, consultez la rubrique Lancement d'applications à l'aide de spark-submit.
-
Dans le champ Arguments, saisissez les arguments et les valeurs suivants :
--data_source s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv
--output_uri s3://DOC-EXAMPLE-BUCKET/myOutputFolder
Remplacez s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv par l'URI du compartiment S3 des données d'entrée que vous avez préparées dans Préparation d'une application avec des données d'entrée pour Amazon EMR.
Remplacez DOC-EXAMPLE-BUCKET par le nom du compartiment que vous avez créé pour ce didacticiel, et remplacez MyOutputFolder par le nom du dossier de sortie de votre cluster.
-
Pour l'action en cas d'échec de l'étape, acceptez l'option par défaut Continuer. Ainsi, en cas d'échec de l'étape, le cluster continue de fonctionner.
-
Choisissez Ajouter pour soumettre l'étape. L'étape devrait apparaître dans la console avec l'état En attente.
-
Surveillez l'état de l'étape. Il devrait passer de En attente à En cours d'exécution, puis à Terminé. Pour actualiser l'état dans la console, cliquez sur l'icône d'actualisation à droite de Filtre. L'exécution du script prend environ une minute. Lorsque l'état devient Terminé, l'étape s'est achevée avec succès.
- Old console
-
Soumission d'une application Spark en tant qu'étape à l'aide de l'ancienne console
Accédez à la nouvelle console Amazon EMR et sélectionnez Basculer vers l'ancienne console depuis le menu latéral. Pour plus d'informations sur ce qui vous attend lorsque vous passez à l'ancienne console, consultez la rubrique Utilisation de l'ancienne console.
-
Dans la Liste de clusters, sélectionnez le nom de votre cluster. L'état du cluster doit être En attente.
-
Cliquez sur Steps (Étapes), puis sur Add step (Ajouter une étape).
-
Configurez l'étape en fonction des consignes suivantes :
-
Pour Type d'étape, choisissez Spark application. Vous devriez voir apparaître des champs supplémentaires pour le mode de déploiement, les options Spark-submit et l'emplacement de l'application.
-
Pour Nom, laissez la valeur par défaut ou saisissez un nouveau nom. Si vous avez de nombreuses étapes dans un cluster, le fait de nommer chaque étape vous aide à en garder la trace.
-
Pour Mode de déploiement, laissez la valeur par défaut Cluster. Pour plus d'informations sur les modes de déploiement de Spark, consultez la rubrique Présentation du mode cluster dans la documentation Apache Spark.
-
Laissez le champ des options Spark-submit vide. Pour plus d'informations sur les options spark-submit, consultez la rubrique Lancement d'applications à l'aide de spark-submit.
-
Pour Emplacement de l'application, saisissez l'emplacement de votre script health_violations.py dans Amazon S3. Par exemple, s3://DOC-EXAMPLE-BUCKET/health_violations.py.
-
Dans le champ Arguments, saisissez les arguments et les valeurs suivants :
--data_source s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv
--output_uri s3://DOC-EXAMPLE-BUCKET/myOutputFolder
Remplacez s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv par l'URI S3 des données d'entrée que vous avez préparées dans Préparation d'une application avec des données d'entrée pour Amazon EMR.
Remplacez DOC-EXAMPLE-BUCKET par le nom du compartiment que vous avez créé pour ce didacticiel, et MyOutputFolder par le nom du dossier de sortie de votre cluster.
-
Pour Action en cas d'échec, acceptez l'option par défaut Continuer afin qu'en cas d'échec de l'étape, le cluster continue de s'exécuter.
-
Choisissez Ajouter pour soumettre l'étape. L'étape devrait apparaître dans la console avec l'état En attente.
-
Vérifiez que l'etat de l'étape passe de En attente à En cours d'exécution, puis à Terminé. Pour actualiser l'état dans la console, choisissez l'icône d'actualisation à droite de Filtre. L'exécution du script prend environ une minute.
Vous saurez que l'étape s'est terminée correctement lorsque l'état passe à Terminé.
- CLI
-
Soumission d'une application Spark en tant qu'étape à l'aide de la AWS CLI
-
Assurez-vous d'avoir le ClusterId du cluster que vous avez lancé dans Lancement d'un cluster Amazon EMR. Vous pouvez également récupérer l'identifiant de votre cluster à l'aide de la commande suivante.
aws emr list-clusters --cluster-states WAITING
-
Soumettez health_violations.py en tant qu'étape à l'aide de la commande add-steps et de votre ClusterId.
-
Vous pouvez donner un nom à votre étape en remplaçant « Mon application Spark ». Dans le tableau Args, remplacez s3://DOC-EXAMPLE-BUCKET/health_violations.py par l'emplacement de votre application health_violations.py.
-
Remplacez s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv par l'emplacement S3 de votre jeu de données food_establishment_data.csv.
-
Remplacez s3://DOC-EXAMPLE-BUCKET/MyOutputFolder par le chemin S3 du compartiment que vous avez indiqué et le nom du dossier de sortie de votre cluster.
-
ActionOnFailure=CONTINUE signifie que le cluster continue à s'exécuter si l'étape échoue.
aws emr add-steps \
--cluster-id <myClusterId> \
--steps Type=Spark,Name="<My Spark Application>",ActionOnFailure=CONTINUE,Args=[<s3://DOC-EXAMPLE-BUCKET/health_violations.py>,--data_source,<s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv>,--output_uri,<s3://DOC-EXAMPLE-BUCKET/MyOutputFolder>]
Pour plus d'informations sur la soumission d'étapes à l'aide de la CLI, consultez la Référence de commandes de la AWS CLI.
Une fois que vous avez soumis l'étape, vous devriez voir un résultat comme le suivant, avec une liste de StepIds. Puisque vous n'avez soumis qu'une seule étape, vous ne verrez qu'un seul identifiant dans la liste. Copiez votre identifiant d'étape. Utilisez votre identifiant d'étape pour vérifier l'état de l'étape.
{
"StepIds": [
"s-1XXXXXXXXXXA"
]
}
-
Vérifiez l'état de votre étape à l'aide de la commande describe-step.
aws emr describe-step --cluster-id <myClusterId> --step-id <s-1XXXXXXXXXXA>
Vous devriez voir un résultat comme le suivant, avec des informations sur votre étape.
{
"Step": {
"Id": "s-1XXXXXXXXXXA",
"Name": "My Spark Application",
"Config": {
"Jar": "command-runner.jar",
"Properties": {},
"Args": [
"spark-submit",
"s3://DOC-EXAMPLE-BUCKET/health_violations.py",
"--data_source",
"s3://DOC-EXAMPLE-BUCKET/food_establishment_data.csv",
"--output_uri",
"s3://DOC-EXAMPLE-BUCKET/myOutputFolder"
]
},
"ActionOnFailure": "CONTINUE",
"Status": {
"State": "COMPLETED"
}
}
}
La valeur State de l'étape passe de PENDING à RUNNING, puis à COMPLETED, au fur et à mesure que l'étape s'exécute. L'exécution de l'étape prend environ une minute, il se peut donc que vous deviez vérifier l'état à plusieurs reprises.
Vous saurez que l'étape s'est terminée correctement lorsque le State passe à COMPLETED.
Pour plus d'informations sur le cycle de vie des étapes, consultez Exécuter des étapes pour traiter des données.
Affichage des résultats
Une fois qu'une étape s'est exécutée avec succès, vous pouvez consulter ses résultats dans votre dossier de sortie Amazon S3.
Affichage des résultats de health_violations.py
Ouvrez la console Amazon S3 sur https://console.aws.amazon.com/s3/.
-
Choisissez le nom du compartiment, puis le dossier de sortie que vous avez spécifié lorsque vous avez soumis l'étape. Par exemple, DOC-EXAMPLE-BUCKET, puis myOutputFolder.
-
Vérifiez que les éléments suivants apparaissent dans votre dossier de sortie :
-
Choisissez l'objet contenant vos résultats, puis choisissez Télécharger pour enregistrer les résultats dans votre système de fichiers local.
-
Ouvrez le résultats dans l'éditeur de votre choix. Le fichier de sortie répertorie les dix établissements ayant enregistré le plus grand nombre d'infractions rouges. Le fichier de sortie indique également le nombre total d'infractions rouges pour chaque établissement.
Voici un exemple de résultats health_violations.py.
name, total_red_violations
SUBWAY, 322
T-MOBILE PARK, 315
WHOLE FOODS MARKET, 299
PCC COMMUNITY MARKETS, 251
TACO TIME, 240
MCDONALD'S, 177
THAI GINGER, 153
SAFEWAY INC #1508, 143
TAQUERIA EL RINCONSITO, 134
HIMITSU TERIYAKI, 128
Pour plus d'informations sur la sortie des clusters Amazon EMR, consultez Configuration d'un emplacement de sortie.
Lorsque vous utilisez Amazon EMR, vous souhaiterez peut-être vous connecter à un cluster en cours d'exécution pour lire les fichiers journaux, déboguer le cluster ou utiliser des outils de la CLI tels que le shell de Spark. Amazon EMR vous permet de vous connecter à un cluster à l'aide du protocole Secure Shell (SSH). Cette section explique comment configurer SSH, vous connecter à votre cluster et consulter les fichiers journaux de Spark. Pour plus d'informations sur la connexion à un cluster, consultez Authentification auprès des nœuds de cluster Amazon EMR.
Autorisation des connexions SSH à votre cluster
Avant de vous connecter à votre cluster, vous devez modifier les groupes de sécurité de votre cluster pour autoriser les connexions SSH entrantes. Les groupes de sécurité Amazon EC2 agissent en tant que pares-feux virtuels pour contrôler le trafic entrant et sortant de votre cluster. Lorsque vous avez créé votre cluster pour ce didacticiel, Amazon EMR a créé les groupes de sécurité suivants en votre nom :
- ElasticMapReduce-master
-
Le groupe de sécurité gérés Amazon EMR par défaut, associé au nœud primaire. Dans un cluster Amazon EMR, le nœud primaire est une instance Amazon EC2 qui gère le cluster.
- ElasticMapReduce-slave
-
Groupe de sécurité par défaut associé aux nœuds principaux et aux nœuds de tâches.
- New console
-
Autorisation de l'accès SSH des sources fiables au groupe de sécurité principal à l'aide de la nouvelle console
Pour modifier vos groupes de sécurité, vous devez avoir l'autorisation de gérer les groupes de sécurité pour le VPC dans lequel se trouve le cluster. Pour plus d'informations, consultez Modification des autorisations d'un utilisateur et l'exemple de politique permettant de gérer les groupes de sécurité EC2 dans le Guide de l'utilisateur IAM.
-
Connectez-vous à la AWS Management Console et ouvrez la console Amazon EMR à l'adresse https://console.aws.amazon.com/emr.
-
Dans le volet de navigation de gauche, sous EMR on EC2, choisissez Clusters, puis le cluster que vous souhaitez mettre à jour. La page de détails du cluster s'ouvre. L'onglet Propriétés de cette page devrait être présélectionné.
-
Sous Mise en réseau dans l'onglet Propriétés, sélectionnez la flèche à côté des groupes de sécurité EC2 (pare-feu) pour développer cette section. Sous Nœud primaire, sélectionnez le lien du groupe de sécurité. Lorsque vous avez effectué les étapes suivantes, vous avez la possibilité de revenir à cette étape, de sélectionner les Nœuds principaux et de tâche, et de répéter les étapes suivantes pour permettre l'accès du client SSH aux nœuds principaux et de tâche.
-
Ceci ouvre la console EC2. Sélectionnez l'onglet Règles entrantes, puis Modifier les règles entrantes.
-
Vérifiez s'il existe une règle entrante qui autorise l'accès public avec les paramètres suivants. Si elle existe, choisissez Supprimer pour la supprimer.
-
Type
SSH
-
Port
22
-
Source
Personnalisé 0.0.0.0/0
Avant décembre 2020, le groupe de sécurité ElasticMapReduce-master disposait d'une règle préconfigurée pour autoriser le trafic entrant sur le port 22 en provenance de toutes les sources. Cette règle a été créée pour simplifier les connexions SSH initiales au nœud principal. Nous vous recommandons vivement de supprimer cette règle d'entrée et de limiter le trafic aux sources fiables.
-
Faites défiler la liste des règles jusqu'en bas et sélectionnez Ajouter une règle.
-
Dans le champ Type, sélectionnez SSH. En sélectionnant SSH, vous saisissez automatiquement TCP pour le protocole et 22 pour la plage de ports.
-
Pour source, sélectionnez Mon adresse IP pour ajouter automatiquement votre adresse IP en tant qu'adresse source. Vous pouvez également ajouter une plage d'adresses IP de clients fiables personnalisées ou créer des règles supplémentaires pour d'autres clients. De nombreux environnements réseau allouent des adresses IP de manière dynamique. Il se peut donc que vous deviez mettre à jour vos adresses IP pour les clients fiables à l'avenir.
-
Choisissez Save (Enregistrer).
-
Choisissez éventuellement les nœuds principaux et de tâches dans la liste et répétez les étapes ci-dessus pour autoriser l'accès du client SSH aux nœuds principaux et aux nœuds de tâches.
- Old console
-
Autorisation de l'accès SSH des sources fiables au groupe de sécurité principal à l'aide de l'ancienne console
Pour modifier vos groupes de sécurité, vous devez avoir l'autorisation de gérer les groupes de sécurité pour le VPC dans lequel se trouve le cluster. Pour plus d'informations, consultez Modification des autorisations d'un utilisateur et l'exemple de politique permettant de gérer les groupes de sécurité EC2 dans le Guide de l'utilisateur IAM.
Accédez à la nouvelle console Amazon EMR et sélectionnez Basculer vers l'ancienne console depuis le menu latéral. Pour plus d'informations sur ce qui vous attend lorsque vous passez à l'ancienne console, consultez la rubrique Utilisation de l'ancienne console.
Choisissez Clusters. Dans la liste des clusters, choisissez le nom du cluster que vous souhaitez modifier.
Sous Sécurité et accès, choisissez le lien Groupes de sécurité pour le principal.
Choisissez ElasticMapReduce-master dans la liste.
Sélectionnez l'onglet Règles entrantes, puis Modifier les règles entrantes.
Vérifiez s'il existe une règle entrante qui autorise l'accès public avec les paramètres suivants. Si elle existe, choisissez Supprimer pour la supprimer.
-
Type
SSH
-
Port
22
-
Source
Personnalisé 0.0.0.0/0
Avant décembre 2020, le groupe de sécurité ElasticMapReduce-Master disposait d'une règle préconfigurée pour autoriser le trafic entrant sur le port 22 en provenance de toutes les sources. Cette règle a été créée pour simplifier les connexions SSH initiales au nœud primaire. Nous vous recommandons vivement de supprimer cette règle d'entrée et de limiter le trafic aux sources fiables.
Faites défiler la liste des règles jusqu'en bas et sélectionnez Ajouter une règle.
-
Dans le champ Type, sélectionnez SSH.
En sélectionnant SSH, vous saisissez automatiquement TCP pour le protocole et 22 pour la plage de ports.
-
Pour source, sélectionnez Mon adresse IP pour ajouter automatiquement votre adresse IP en tant qu'adresse source. Vous pouvez également ajouter une plage d'adresses IP de clients fiables personnalisées ou créer des règles supplémentaires pour d'autres clients. De nombreux environnements réseau allouent des adresses IP de manière dynamique. Il se peut donc que vous deviez mettre à jour vos adresses IP pour les clients fiables à l'avenir.
Choisissez Save (Enregistrer).
En option, choisissez ElasticMapReduce-slave dans la liste et répétez les étapes ci-dessus pour autoriser l'accès du client SSH aux nœuds principaux et aux nœuds de tâches.
Connexion à votre cluster à l'aide de la AWS CLI
Quel que soit votre système d'exploitation, vous pouvez créer une connexion SSH à votre cluster à l'aide de la AWS CLI.
Connexion à votre cluster et visualisation des fichiers journaux à l'aide de la AWS CLI
-
Utilisez la commande suivante pour ouvrir une connexion SSH à votre cluster. Remplacez <mykeypair.key> par le chemin d'accès complet et le nom du fichier de votre paire de clés. Par exemple, C:\Users\<username>\.ssh\mykeypair.pem.
aws emr ssh --cluster-id <j-2AL4XXXXXX5T9> --key-pair-file <~/mykeypair.key>
-
Naviguez vers /mnt/var/log/spark pour accéder aux journaux Spark sur le nœud principal de votre cluster. Affichez ensuite les fichiers qui se trouvent à cet emplacement. Pour obtenir la liste des fichiers journaux supplémentaires sur le nœud principal, consultez Affichage des fichiers journaux sur le nœud primaire.
cd /mnt/var/log/spark
ls
Étape 3 : Nettoyer vos ressources Amazon EMR
Arrêt de votre cluster
Maintenant que vous avez soumis du travail à votre cluster et que vous avez vu les résultats de votre application PySpark, vous pouvez arrêter le cluster. L'arrêt du cluster arrête toutes les charges Amazon EMR et les instances Amazon EC2 qui lui sont associées.
Lorsque vous arrêtez un cluster, Amazon EMR conserve gratuitement les métadonnées relatives au cluster pendant deux mois. Les métadonnées archivées vous permettent de cloner le cluster pour une nouvelle tâche ou de retenir la configuration du cluster à des fins de référence. Les métadonnées n'incluent pas les données que le cluster écrit dans S3, ni les données stockées dans HDFS sur le cluster.
La console Amazon EMR ne vous permet pas de supprimer un cluster de la vue de la liste après avoir arrêté le cluster. Le cluster arrêté disparaît de la console lorsqu'Amazon EMR efface ses métadonnées.
- New console
-
Arrêt du cluster à l'aide de la nouvelle console
-
Connectez-vous à la AWS Management Console et ouvrez la console Amazon EMR à l'adresse https://console.aws.amazon.com/emr.
-
Choisissez Clusters, puis sélectionnez le cluster que vous voulez arrêter.
-
Dans le menu déroulant Actions, choisissez Arrêter le cluster.
-
Dans la boîte de dialogue, choisissez Arrêter. Selon la configuration du cluster, l'arrêt peut prendre de 5 à 10 minutes. Pour plus d'informations sur la création de clusters Amazon EMR, consultez Arrêter un cluster.
- Old console
-
Arrêt du cluster à l'aide de l'ancienne console
Accédez à la nouvelle console Amazon EMR et sélectionnez Basculer vers l'ancienne console depuis le menu latéral. Pour plus d'informations sur ce qui vous attend lorsque vous passez à l'ancienne console, consultez la rubrique Utilisation de l'ancienne console.
-
Choisissez Clusters, puis sélectionnez le cluster que vous voulez arrêter. Par exemple, Mon premier cluster EMR.
-
Choisissez Arrêter pour ouvrir l'invite Arrêter le cluster.
-
Dans l'invite qui s'affiche, choisissez Arrêter. Selon la configuration du cluster, l'arrêt peut prendre de 5 à 10 minutes. Pour plus d'informations sur l'arrêt des clusters Amazon EMR, consultez Arrêter un cluster.
Si vous avez suivi le didacticiel à la lettre, la protection contre l'arrêt devrait être désactivée. La protection contre l'arrêt du cluster permet d'éviter les arrêts accidentels. Si la protection contre l'arrêt est activée, vous verrez une invite à modifier le paramètre avant d'arrêter le cluster. Choisissez Changer, puis Désactivé.
- CLI
-
Arrêt du cluster à l'aide de la AWS CLI
-
Lancez le processus d'arrêt du cluster à l'aide de la commande suivante. Remplacez <myClusterId> par l'identifiant de votre exemple de cluster. La commande ne renvoie pas de résultat.
aws emr terminate-clusters --cluster-ids <myClusterId>
-
Pour vérifier que le processus d'arrêt du cluster est en cours, vérifiez l'état du cluster à l'aide de la commande suivante.
aws emr describe-cluster --cluster-id <myClusterId>
Voici un exemple de résultat au format JSON. Le Status du cluster doit passer de TERMINATING à TERMINATED. Selon la configuration de votre cluster, l'arrêt peut prendre de 5 à 10 minutes. Pour plus d'informations sur l'arrêt d'un cluster Amazon EMR, consultez Arrêter un cluster.
{
"Cluster": {
"Id": "j-xxxxxxxxxxxxx",
"Name": "My Cluster Name",
"Status": {
"State": "TERMINATED",
"StateChangeReason": {
"Code": "USER_REQUEST",
"Message": "Terminated by user request"
}
}
}
}
Suppression des ressources S3
Pour éviter des frais supplémentaires, vous devez supprimer votre compartiment Amazon S3. La suppression du compartiment entraîne la suppression de toutes les ressources Amazon S3 pour ce didacticiel. Votre compartiment doit contenir :
-
Le script PySpark
-
Le jeu de données d'entrée
-
Votre dossier de résultats de sortie
-
Votre dossier de fichiers journaux
Vous devrez peut-être prendre des mesures supplémentaires pour supprimer les fichiers stockés si vous avez enregistré votre script PySpark ou votre résultat dans un autre emplacement.
Votre cluster doit être arrêté avant que vous ne supprimiez votre compartiment. Sinon, vous risquez de ne pas être autorisé à vider le compartiment.
Pour supprimer votre compartiment, suivez les instructions de la rubrique Comment supprimer un compartiment S3 ? dans le Guide de l'utilisateur Amazon Simple Storage Service.
Étapes suivantes
Vous venez de lancer votre premier cluster Amazon EMR du début à la fin. Vous avez également effectué des tâches EMR essentielles telles que la préparation et la soumission des applications de big data, la visualisation des résultats et l'arrêt d'un cluster.
Consultez les rubriques suivantes pour en savoir plus sur la manière dont vous pouvez personnaliser votre flux de travail Amazon EMR.
Découvrez les applications de big data pour Amazon EMR
Découvrez et comparez les applications de big data que vous pouvez installer sur un cluster dans le Guide de mise à jour d'Amazon EMR. Le guide de mise à jour détaille chaque version EMR et comprend des conseils pour l'utilisation d'environnements tels que Spark et Hadoop sur Amazon EMR.
Planification du matériel, de la mise en réseau et de la sécurité du cluster
Dans ce didacticiel, vous avez créé un cluster EMR simple sans configurer d'options avancées. Les options avancées vous permettent de spécifier les types d'instances Amazon EC2, le réseau du cluster et la sécurité du cluster. Pour plus d'informations sur la planification et le lancement d'un cluster répondant à vos besoins, consultez Planification et configuration des clusters et Sécurité dans Amazon EMR.
Gestion des clusters
Approfondissez l'utilisation de clusters en cours d'exécution dans Gestion des clusters. Pour gérer un cluster, vous pouvez vous connecter au cluster, effectuer les étapes de débogage et suivre les activités et l'état du cluster. Vous pouvez également ajuster les ressources du cluster en fonction des demandes de charge de travail grâce à la mise à l'échelle gérée par EMR.
Utilisation d'une interface différente
Outre la console Amazon EMR, vous pouvez gérer Amazon EMR à l'aide de la AWS Command Line Interface, de l'API du service web ou de l'un des nombreux kits SDK AWS pris en charge. Pour de plus amples informations, veuillez consulter Interfaces de gestion.
Vous pouvez également interagir avec les applications installées sur les clusters Amazon EMR de plusieurs façons. Certaines applications, comme Apache Hadoop, publient des interfaces web que vous pouvez consulter. Pour de plus amples informations, veuillez consulter Affichage des interfaces Web hébergées sur des clusters Amazon EMR.
Consultation du blog technique EMR
Pour des exemples de démonstration et des discussions techniques approfondies sur les nouvelles fonctionnalités d'Amazon EMR, consultez le blog AWS big data.