Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comprendre comment créer et utiliser des clusters Amazon EMR
Cette rubrique fournit une présentation des clusters Amazon EMR, y compris de la façon de soumettre des tâches à un cluster, de la manière dont ces données sont traitées et des différents états par lesquels le cluster passe au cours de ce traitement.
Dans cette rubrique
Se familiariser avec les clusters et les nœuds
Le composant central d'Amazon EMR est le cluster. Un cluster est un ensemble d'instances Amazon Elastic Compute Cloud (Amazon EC2). Chaque instance dans le cluster est appelée un nœud. Chaque nœud dispose d'un rôle dans le cluster, qu'on appelle le type de nœud. Amazon EMR installe également des composants logiciels différents sur chaque type de nœud, conférant ainsi à chaque nœud un rôle dans une application distribuée telle qu'Apache Hadoop.
Les types de nœud dans Amazon EMR sont les suivants :
-
Nœud primaire : nœud qui gère le cluster en exécutant des composants logiciels pour coordonner la distribution des données et des tâches entre d'autres nœuds en vue de leur traitement. Le nœud primaire effectue le suivi du statut des tâches et surveille l'état du cluster. Chaque cluster a un nœud primaire ; il est possible de créer un cluster à nœud unique avec seulement le nœud primaire.
-
Nœud principal : Nœud doté de composants logiciels qui exécutent les tâches et stockent les données dans le système de fichiers distribué Hadoop (HDFS) sur votre cluster. Les clusters à plusieurs nœuds ont au moins un nœud principal.
-
Nœud de tâche : Nœud doté de composants logiciels qui exécutent uniquement des tâches et ne stockent pas les données dans HDFS. Les nœuds de tâches sont facultatifs.
Soumettre des tâches à un cluster
Lorsque vous exécutez un cluster sur Amazon EMR, vous avez plusieurs options quant à la façon de spécifier les tâches qui doivent être effectuées.
-
Fournissez la définition complète du travail à effectuer dans des fonctions que vous spécifiez en tant qu'étapes lorsque vous créez un cluster. Cette solution est privilégiée pour les clusters qui traitent une quantité déterminée de données, puis sont arrêtés une fois le traitement terminé.
-
Créez un cluster de longue durée et utilisez la console Amazon EMR, l'API Amazon EMR ou AWS CLI les étapes de soumission, qui peuvent contenir une ou plusieurs tâches. Pour de plus amples informations, veuillez consulter Soumettre un travail à un cluster Amazon EMR.
-
Créez un cluster, connectez-vous au nœud primaire et aux autres nœuds si nécessaire à l'aide de SSH, puis utilisez les interfaces que les applications installées fournissent pour effectuer des tâches et soumettre des requêtes, soit par l'intermédiaire de scripts soit de manière interactive. Pour plus d'informations, consultez le Guide de version Amazon EMR.
Traitement des données
Lorsque vous lancez votre cluster, vous choisissez les infrastructures et les applications à installer pour répondre à vos besoins de traitement des données. Pour traiter les données de votre cluster Amazon EMR, vous pouvez soumettre des tâches ou des requêtes directement aux applications installées, ou vous pouvez exécuter des étapes dans le cluster.
Soumettre des tâches directement aux applications
Vous pouvez soumettre des tâches et interagir directement avec le logiciel qui est installé dans votre cluster Amazon EMR. Pour cela, vous vous connectez généralement au nœud primaire via une connexion sécurisée et accédez aux interfaces et outils qui sont disponibles pour le logiciel qui s'exécute directement sur votre cluster. Pour de plus amples informations, veuillez consulter Connexion à un cluster Amazon EMR.
Exécuter des étapes pour traiter des données
Vous pouvez soumettre une ou plusieurs étapes ordonnées à un cluster Amazon EMR. Chaque étape est une unité de travail qui contient des instructions de manipulation des données qui doivent être traitées par le logiciel installé sur le cluster.
Voici un exemple de processus à quatre étapes :
-
Envoi d'un jeu de données d'entrée à traiter.
-
Traitement des données de sortie de la première étape à l'aide d'un programme Pig.
-
Traitement d'un second jeu de données d'entrée à l'aide d'un programme Hive.
-
Écriture d'un jeu de données de sortie.
En règle générale, lorsque vous traitez des données dans Amazon EMR, l'entrée correspond à des données stockées sous forme de fichiers dans votre système de fichiers sous-jacent choisi, tel qu'Amazon S3 ou HDFS. Ces données passent d'une étape à l'autre dans la séquence de traitement. L'étape finale écrit les données de sortie dans un emplacement spécifié, tel qu'un compartiment Amazon S3.
Les étapes sont exécutées dans l'ordre suivant :
-
Une demande est soumise pour commencer le traitement des étapes.
-
L'état de toutes les étapes est défini sur EN SUSPENS.
-
Lorsque la première étape de la séquence commence, son état passe à EN COURS D'EXÉCUTION. Les autres étapes restent à l'état EN SUSPENS.
-
Une fois la première étape terminée, son état devient TERMINÉ.
-
L'étape suivante de la séquence commence et son état passe à EN COURS D'EXÉCUTION. Une fois terminée, son état devient TERMINÉ.
-
Ce modèle se répète pour chaque étape jusqu'à ce qu'elles soient toutes terminées, puis le traitement se termine.
Le schéma suivant représente la séquence d'étapes et le changement d'état des étapes au fur et à mesure de leur traitement.

Si une étape échoue au cours du traitement, son état devient FAILED. Vous pouvez déterminer ce qui se passe ensuite pour chaque étape. Par défaut, les étapes restantes de la séquence sont définies sur CANCELLED et ne sont pas exécutées si une étape précédente échoue. Vous pouvez également choisir d'ignorer l'échec et d'autoriser l'exécution des étapes restantes, ou d'arrêter le cluster immédiatement.
Le schéma suivant représente la séquence des étapes et le changement d'état par défaut lorsqu'une étape échoue pendant le traitement.

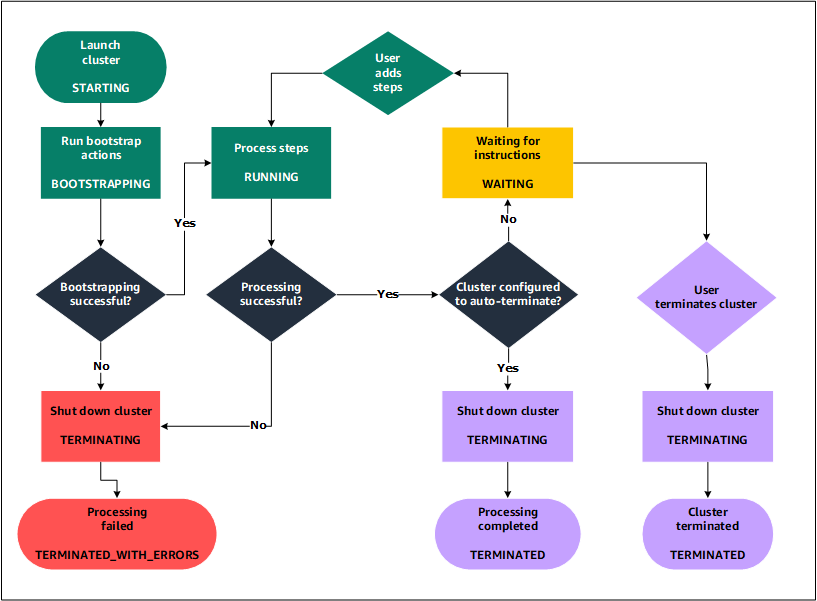
Présentation du cycle de vie du cluster
Un cluster Amazon EMR réussi suit ce processus :
-
Amazon EMR approvisionne d'abord EC2 les instances du cluster pour chaque instance conformément à vos spécifications. Pour de plus amples informations, veuillez consulter Configuration du matériel et du réseau du cluster Amazon EMR. Pour toutes les instances, Amazon EMR utilise l'AMI par défaut pour Amazon EMR ou une AMI Amazon Linux personnalisée que vous spécifiez. Pour de plus amples informations, veuillez consulter Utilisation d'une AMI personnalisée pour apporter plus de flexibilité à la configuration du cluster Amazon EMR. Au cours de cette phase, l'état du cluster est
STARTING. -
Amazon EMR exécute les actions d'amorçage que vous spécifiez sur chaque instance. Vous pouvez utiliser des actions d'amorçage pour installer des applications personnalisées et exécuter les personnalisations dont vous avez besoin. Pour de plus amples informations, veuillez consulter Créez des actions bootstrap pour installer des logiciels supplémentaires avec un cluster Amazon EMR. Au cours de cette phase, l'état du cluster est
BOOTSTRAPPING. -
Amazon EMR installe les applications natives que vous spécifiez lorsque vous créez le cluster, telles que Hive, Hadoop, Spark, etc.
-
Lorsque les actions d'amorçage sont terminées et que les applications natives sont installées, l'état du cluster est
RUNNING. À ce stade, vous pouvez vous connecter aux instances de cluster, et le cluster exécute de façon séquentielle toutes les étapes que vous avez spécifiées lorsque vous avez créé le cluster. Vous pouvez ajouter des étapes supplémentaires, qui s'exécuteront lorsque les étapes précédentes seront terminées. Pour de plus amples informations, veuillez consulter Soumettre un travail à un cluster Amazon EMR. -
Une fois que les étapes ont été exécutées avec succès, le cluster passe à l'état
WAITING. Si un cluster est configuré pour s'arrêter automatiquement après la dernière étape, il passe à l'étatTERMINATINGpuis à l'étatTERMINATED. Si le cluster est configuré pour attendre, vous devez l'arrêter manuellement lorsque vous n'en avez plus besoin. Après avoir arrêté manuellement le cluster, il passe à l'étatTERMINATINGpuis à l'étatTERMINATED.
En cas d'échec au cours du cycle de vie du cluster, Amazon EMR arrête le cluster et toutes ses instances, sauf si vous activez la protection contre l'arrêt. Si un cluster s'arrête en raison d'une défaillance, toutes les données stockées sur le cluster sont supprimées, et son état devient TERMINATED_WITH_ERRORS. Si vous avez activé la protection contre l'arrêt, vous pouvez récupérer les données à partir de votre cluster, puis supprimer la protection contre l'arrêt et arrêter le cluster. Pour de plus amples informations, veuillez consulter Utilisation de la protection contre la résiliation pour protéger vos clusters Amazon EMR d'un arrêt accidentel.
Le schéma suivant représente le cycle de vie d'un cluster et la façon dont chaque étape du cycle de vie correspond à un état de cluster particulier.