Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
HBase sur Amazon S3 (mode de stockage Amazon S3)
Lorsque vous exécutez Amazon EMR version 5.2.0 ou ultérieure, vous pouvez l'activer HBase sur Amazon HBase S3, ce qui offre les avantages suivants :
Le répertoire HBase racine est stocké dans Amazon S3, y compris les fichiers de HBase stockage et les métadonnées des tables. Ces données sont persistantes en dehors du cluster, disponibles dans toutes les zones de EC2 disponibilité Amazon, et vous n'avez pas besoin de les récupérer à l'aide de snapshots ou d'autres méthodes.
Avec des fichiers de stockage dans Amazon S3, vous pouvez dimensionner votre cluster Amazon EMR plutôt en fonction de vos besoins de calcul qu'en fonction de vos besoins de données, avec une réplication x3 dans HDFS.
En utilisant une version 5.7.0 ou ultérieure d'Amazon EMR, vous pouvez définir un cluster de réplica en lecture, ce qui vous permet de conserver des copies en lecture seule de données dans Amazon S3. Vous pouvez accéder aux données à partir du cluster de réplica en lecture pour réaliser des opérations de lecture simultanément et, dans le cas ou le cluster principal devient indisponible.
Dans les versions 6.2.0 à 7.3.0 d'Amazon EMR, le HFile suivi persistant utilise une table HBase système appelée
hbase:storefilepour suivre directement les HFile chemins utilisés pour les opérations de lecture. Cette fonctionnalité est activée par défaut et ne nécessite pas de migration manuelle. Dans les versions supérieures à 7.3.0, les HFile chemins sont suivis à l'aide d'un outil de suivi de fichiers, qui stocke HFile les chemins directement dans un méta-fichier, dans le répertoire du magasin.
Note
Pour les utilisateurs qui utilisent une version d'Amazon EMR antérieure à la version 7.4.0 et qui migrent vers EMR-7.4.0 ou version ultérieure, consultez la section Migration depuis les HBase versions précédentes et suivez la documentation de mise à niveau disponible pour garantir une transition fluide.
L'illustration suivante montre les HBase composants pertinents pour HBase Amazon S3.
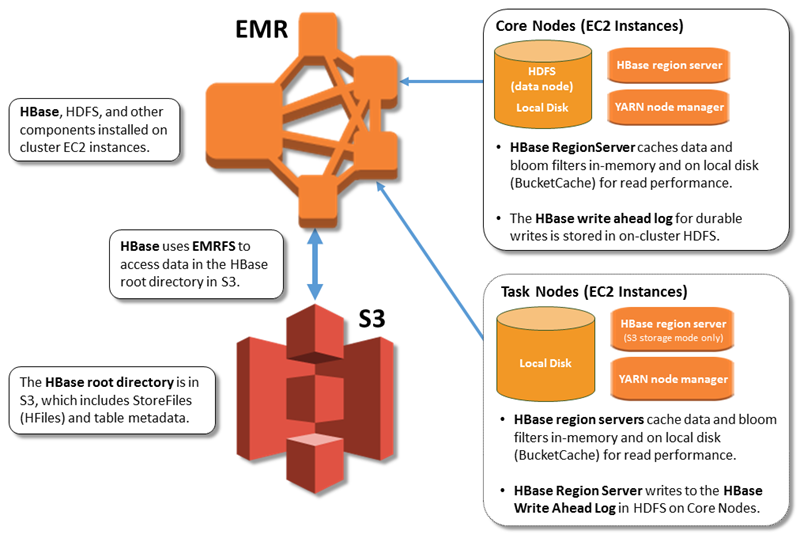
Activation HBase sur Amazon S3
Vous pouvez l'activer HBase sur Amazon S3 à l'aide de la console Amazon EMR, de ou de l' AWS CLI API Amazon EMR. La configuration est une option lors de la création du cluster. Lorsque vous utilisez la console, vous choisissez le paramètre à l'aide des Advanced options (Options avancées). Lorsque vous utilisez l' AWS CLI, utilisez l'option --configurations pour fournir un objet de configuration JSON. Les propriétés de l'objet de configuration précisent le mode de stockage et l'emplacement du répertoire racine dans Amazon S3. L'emplacement Amazon S3 que vous spécifiez doit être dans la même région que votre cluster Amazon EMR. Un seul cluster actif à la fois peut utiliser le même répertoire HBase racine dans Amazon S3. Pour les étapes de console et un exemple détaillé de création de cluster à l'aide du AWS CLI, voir. Création d'un cluster avec HBase Un exemple d'objet de configuration apparaît dans l'extrait JSON suivant.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
Note
Si vous utilisez un compartiment Amazon S3 comme formulaire rootdir HBase, vous devez ajouter une barre oblique à la fin de l'URI Amazon S3. Par exemple, vous devez utiliser "hbase.rootdir: s3://amzn-s3-demo-bucket/", au lieu de "hbase.rootdir: s3://amzn-s3-demo-bucket", pour éviter les problèmes.
Utilisation d'un cluster réplica en lecture
Après avoir configuré un cluster principal à l'aide d' HBase Amazon S3, vous pouvez créer et configurer un cluster en lecture seule qui fournit un accès en lecture seule aux mêmes données que le cluster principal. Cela est utile lorsque vous avez besoin d'un accès simultané à des données de requête ou d'un accès ininterrompu si le cluster principal devient indisponible. La fonctionnalité de réplica en lecture est disponible avec Amazon EMR version 5.7.0 et ultérieure.
Le cluster principal et le cluster de réplica en lecture sont définis de la même façon avec une différence significative. Les deux pointent le même emplacement hbase.rootdir. Cependant, la classification hbase pour le cluster de réplica en lecture comprend la propriété "hbase.emr.readreplica.enabled":"true".
Le cluster de répliques en lecture seule est conçu pour les opérations en lecture seule, et aucune action manuelle de compactage ou d'écriture ne doit être effectuée sur celui-ci. Pour les versions d'Amazon EMR antérieures à 7.4.0, il est recommandé de désactiver le compactage sur le cluster de lecture-réplique lorsque vous activez la fonctionnalité de lecture-réplique. Cette précaution est nécessaire car, lorsque la fonctionnalité de HFile suivi permanent est activée sur le cluster principal, il est possible que le cluster en lecture-réplique compresse les tables système, ce qui peut provoquer un FileNotFoundException dysfonctionnement du cluster principal. La désactivation du compactage sur le cluster en lecture permet d'éviter les incohérences de données entre le cluster principal et le cluster en lecture.
Par exemple, compte tenu de la classification JSON du cluster principal, comme indiqué précédemment dans cette rubrique, la configuration d'un cluster en lecture et en réplique pour les versions EMR antérieures à 7.4.0 est la suivante :
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
Pour les versions d'Amazon EMR ultérieures à 7.3.0, nous utilisons désormais Suivi des fichiers du magasin cette fonctionnalité. Il n'est donc pas nécessaire de désactiver les compactages.
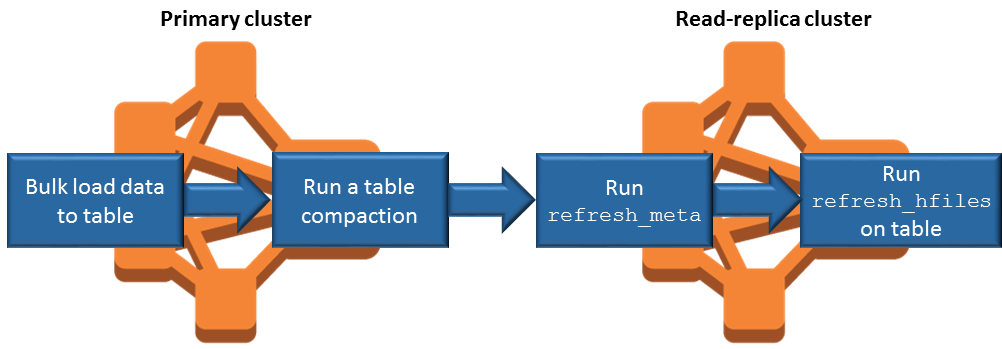
Synchronisation de réplica en lecture lors d'ajout de données
Étant donné que le réplica en lecture utilise HBase StoreFiles les métadonnées que le cluster principal écrit dans Amazon S3, le réplica en lecture est uniquement aussi actuel que le magasin de données Amazon S3. Les conseils suivants vous aident à minimiser le retard entre le cluster principal et la réplica en lecture lorsque vous écrivez des données.
Chargez des données en bloc sur le cluster principal chaque fois que possible. Pour plus d'informations, consultez la section Chargement groupé
dans la HBase documentation d'Apache. Un vidage qui écrit des fichiers de stockage dans Amazon S3 devrait être réalisé dès que possible après l'ajout des données. Procédez au vidage manuel ou configurez les paramètres de vidage pour minimiser le temps de retard.
Si les compactages doivent s'exécuter automatiquement, exécutez un compactage manuel afin d'éviter les incohérences lors du déclenchement des compactages.
Sur le cluster de lecture et de réplication, lorsque des métadonnées ont changé, par exemple en cas de division de HBase région ou de compactage, ou lorsque des tables sont ajoutées ou supprimées, exécutez la commande.
refresh_metaSur le cluster de réplica en lecture, exécutez la commande
refresh_hfileslorsque des enregistrements sont ajoutés vers ou modifiés dans une table.
HFile Suivi permanent
HFile Le suivi permanent utilise une table HBase système appelée hbase:storefile pour suivre directement les HFile chemins utilisés pour les opérations de lecture. De nouveaux HFile chemins sont ajoutés à la table au fur et à mesure que des données supplémentaires sont ajoutées HBase. Cela supprime les opérations de renommage en tant que mécanisme de validation dans les HBase opérations de chemin d'écriture critiques et améliore le temps de restauration lors de l'ouverture d'une HBase région en lisant dans la table hbase:storefile système plutôt que dans la liste des répertoires du système de fichiers. Cette fonctionnalité est activée par défaut sur les versions 6.2.0 à 7.3.0 d'Amazon EMR et ne nécessite aucune étape de migration manuelle.
Note
Le HFile suivi permanent à l'aide de la table système HBase Storefile ne prend pas en charge la fonctionnalité de réplication HBase régionale. Pour plus d'informations sur HBase la réplication régionale, voir Lectures à haute disponibilité cohérentes avec la chronologie
Désactiver le suivi permanent HFile
Le HFile suivi permanent est activé par défaut à partir de la version 6.2.0 d'Amazon EMR. Pour désactiver le HFile suivi permanent, spécifiez la modification de configuration suivante lors du lancement d'un cluster :
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
Note
Lors de la reconfiguration du cluster Amazon EMR, tous les groupes d'instances doivent être mis à jour.
Synchronisation manuelle de la table Storefile
La table Storefile est mise à jour à mesure que de nouvelles HFile instances sont créées. Toutefois, si la table Storefile n'est plus synchronisée avec les fichiers de données pour une raison quelconque, les commandes suivantes peuvent être utilisées pour synchroniser manuellement les données :
Synchroniser la table Storefile dans une région en ligne :
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
Synchroniser la table Storefile dans une région hors connexion :
Supprimez la table Storefile znode.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]Attribuez la région (exécutez dans « hbase shell »).
hbase cli> assign '<region name>'Si l'assignation échoue.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
Mise à l'échelle de la table Storefile
La table Storefile est divisée en quatre régions par défaut. Si la table Storefile est toujours soumise à une charge d'écriture importante, elle peut être divisée manuellement davantage.
Pour diviser une région chaude spécifique, utilisez la commande suivante (exécutée dans « hbase shell »).
hbase cli> split '<region name>'
Pour diviser la table, utilisez la commande suivante (exécutée dans « hbase shell »).
hbase cli> split 'hbase:storefile'
Suivi des fichiers du magasin
Par défaut, nous utilisons l'FileBasedStoreFileTrackerimplémentation. Cette implémentation crée de nouveaux fichiers directement dans le répertoire du magasin, évitant ainsi d'avoir à effectuer des opérations de renommage. Il conserve une liste des instances de hfile validées en mémoire, soutenue par des méta-fichiers dans chaque répertoire de magasin. Chaque fois qu'un nouveau hfile est validé, la liste des fichiers suivis dans le magasin concerné est mise à jour et un nouveau méta-fichier est écrit avec le contenu de la liste et en supprimant le méta-fichier précédent, qui contient une liste obsolète. Pour plus d'informations sur le suivi des fichiers en magasin, consultez la section Suivi des fichiers en magasin
L'implémentation du FileBasedStoreFile tracker est activée par défaut, à partir de la version 7.4.0 d'Amazon EMR :
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" }
Pour désactiver l' FileBasedStoreFileTracker implémentation, spécifiez la modification de configuration suivante lors du lancement d'un cluster :
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" }
Note
Lors de la reconfiguration du cluster Amazon EMR, tous les groupes d'instances doivent être mis à jour.
Considérations opérationnelles
HBase les serveurs régionaux sont utilisés BlockCache pour stocker les lectures de données en mémoire et BucketCache pour stocker les lectures de données sur le disque local. En outre, les serveurs régionaux stockent les écritures de données en mémoire et utilisent les journaux d'écriture anticipée pour stocker les écritures de données dans HDFS avant que les données ne soient écrites dans Amazon HBase StoreFiles S3. MemStore Les performances de lecture de votre cluster dépendent de la fréquence à laquelle un enregistrement peut être récupéré à partir des caches en mémoire ou sur le disque. Une erreur de cache entraîne la lecture de l' StoreFile enregistrement depuis Amazon S3, ce qui présente une latence et un écart-type nettement supérieurs à ceux de la lecture depuis HDFS. De plus, les taux de demandes maximal pour Amazon S3 sont inférieurs à ce qui peut être réalisé à partir du cache local, la mise en cache de données peut donc être importante pour les charges de travail avec une forte densité de lectures. Pour plus d'informations sur les performances d'Amazon S3, consultez la section Optimisation des performances dans le Guide de l'utilisateur Amazon Simple Storage Service.
Pour améliorer les performances, nous vous recommandons de mettre en cache la plus grande partie possible de votre ensemble de données dans le stockage d'EC2 instance. Comme il BucketCache utilise le stockage d' EC2 instance du serveur régional, vous pouvez choisir un type d' EC2 instance avec un stockage d'instance suffisant et ajouter du stockage Amazon EBS pour répondre à la taille de cache requise. Vous pouvez également augmenter la BucketCache taille des magasins d'instances attachés et des volumes EBS à l'aide de cette hbase.bucketcache.size propriété. Le paramètre par défaut est 8 192 MB.
En ce qui concerne les écritures, la fréquence des MemStore purges d'eau et le nombre de personnes StoreFiles présentes lors de compactages mineurs ou majeurs peuvent contribuer de manière significative à l'augmentation des temps de réponse des serveurs régionaux. Pour des performances optimales, pensez à augmenter la taille du MemStore purgeur et du multiplicateur de HRegion blocs, ce qui augmente le temps écoulé entre les compactages majeurs, mais augmente également le retard de cohérence si vous utilisez une réplique en lecture. Dans certains cas, vous pouvez obtenir de meilleures performances en utilisant des tailles de blocs de fichiers plus importantes (néanmoins inférieures à 5 Go) pour déclencher la fonction de chargement partitionné d'Amazon S3 dans EMRFS. La taille de bloc par défaut d'Amazon EMR est de 128 Mo. Pour de plus amples informations, veuillez consulter Configuration HDFS. Nous voyons rarement des clients dépasser une taille de bloc de 1 Go lorsque nous comparons les performances avec des vidages et des compactages. De plus, HBase les compactages et les serveurs régionaux fonctionnent de manière optimale lorsqu'il est StoreFiles nécessaire de compacter moins de serveurs.
Les tables peuvent mettre du temps pour arriver dans Amazon S3, car des répertoires volumineux doivent être renommés. Envisagez la désactivation des tables plutôt que leur suppression.
Il existe un HBase processus de nettoyage qui nettoie les anciens fichiers WAL et stocke les fichiers. Avec les version 5.17.0 et ultérieures d'Amazon EMR, l'appareil est activé dans le monde entier et les propriétés de configuration suivantes peuvent être utilisées pour contrôler un comportement plus propre.
| Propriété de configuration | Valeur par défaut | Description |
|---|---|---|
|
|
1 |
Le nombre de threads alloués au nettoyage a expiré en grande quantité HFiles. |
|
|
1 |
Le nombre de threads alloués au nettoyage a expiré petit HFiles. |
|
|
Défini sur un quart de tous les noyaux disponibles. |
Le nombre de threads à analyser dans les anciens WALs répertoires. |
|
|
2 |
Le nombre de threads à nettoyer WALs dans l'ancien WALs répertoire. |
Avec les versions 5.17.0 et ultérieures d'Amazon EMR, l'opération de nettoyage peut voir un impact sur les performances de requêtes lors de l'exécution d'importantes charges de travail. Nous vous recommandons donc d'activer le nettoyeur uniquement pendant les heures creuses. Le nettoyeur possède les commandes HBase shell suivantes :
cleaner_chore_enabledvérifie si l'appareil est activé.cleaner_chore_runexécute manuellement le nettoyeur pour supprimer les fichiers.cleaner_chore_switchactive ou désactive le nettoyeur et le remet à son état précédent. Par exemple,cleaner_chore_switch trueactive le nettoyeur.
Propriétés pour HBase le réglage des performances sur Amazon S3
Les paramètres suivants peuvent être ajustés pour optimiser les performances de votre charge de travail lorsque vous l'utilisez HBase sur Amazon S3.
| Propriété de configuration | Valeur par défaut | Description |
|---|---|---|
|
|
8 192 |
La quantité d'espace disque, en Mo, réservée sur le serveur régional, sur les stockages d' EC2 instances Amazon et sur les volumes EBS pour le BucketCache stockage. Le paramètre s'applique à toutes les instances de serveur de la région. Des BucketCache tailles plus grandes correspondent généralement à de meilleures performances |
|
|
134217728 |
La limite des données, en octets, à laquelle le vidage d'un memstore vers Amazon S3 est déclenché. |
|
|
4 |
Un multiplicateur qui détermine la limite MemStore supérieure à laquelle les mises à jour sont bloquées. Si les MemStore dépassements |
|
|
10 |
Le nombre maximum de ces informations peut exister dans un magasin avant StoreFiles que les mises à jour ne soient bloquées. |
|
|
10737418240 |
La taille maximale d'une région avant que la région ne soit fractionnée. |
Arrêt et restauration d'un cluster sans perte de données
Pour arrêter un cluster Amazon EMR sans perdre de données qui n'ont pas été écrites sur Amazon S3, vous devez vider votre MemStore cache sur Amazon S3 pour y écrire de nouveaux fichiers de boutique. Tout d'abord, vous devez désactiver toutes les tables. La configuration de l'étape suivante peut être utilisée lorsque vous ajoutez une étape au cluster. Pour plus d'informations, consultez Utilisation des étapes à de l' AWS CLI et de la console dans le Guide de gestion d'Amazon EMR.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
Vous pouvez également exécuter la commande bash suivante directement.
bash /usr/lib/hbase/bin/disable_all_tables.sh
Après avoir désactivé toutes les tables, videz-les à l'hbase:metaaide du HBase shell et de la commande suivante.
flush 'hbase:meta'
Vous pouvez ensuite exécuter un script shell fourni sur le cluster Amazon EMR pour vider le cache. MemStore Vous pouvez l'ajouter soit comme une étape, soit en l'exécutant directement à l'aide d' AWS CLI sur le cluster. Le script désactive toutes les HBase tables, ce qui MemStore entraîne le transfert du serveur de chaque région vers Amazon S3. Si le script se termine avec succès, les données persistent dans Amazon S3 et le cluster peut être arrêté.
Pour redémarrer un cluster avec les mêmes HBase données, spécifiez le même emplacement Amazon S3 que le cluster précédent dans AWS Management Console ou à l'aide de la propriété hbase.rootdir de configuration.
