Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Travailler avec les jobs Flink de Zeppelin dans Amazon EMR
Introduction
Les versions 6.10.0 et supérieures d'Amazon EMR prennent en charge l'intégration Apache Zeppelin avec Apache Flink. Vous pouvez soumettre des jobs Flink de manière interactive via les blocs-notes Zeppelin. Avec l'interpréteur Flink, vous pouvez exécuter des requêtes Flink, définir des tâches de streaming et de traitement par lots Flink, et visualiser le résultat dans les blocs-notes Zeppelin. L'interpréteur Flink est basé sur Flink REST API. Cela vous permet d'accéder aux tâches Flink et de les manipuler depuis l'environnement Zeppelin pour effectuer un traitement et une analyse des données en temps réel.
Il existe quatre sous-interprètes dans Flink Interpreter. Ils ont des objectifs différents, mais ils se trouvent tous dans la JVM et partagent les mêmes points d'entrée préconfigurés vers Flink (ExecutionEnviroment, StreamExecutionEnvironment, BatchTableEnvironment, StreamTableEnvironment). Les interprètes sont les suivants :
-
%flink– CréeExecutionEnvironment,StreamExecutionEnvironment,BatchTableEnvironment,StreamTableEnvironment, et fournit un environnement Scala -
%flink.pyflink– Fournit un environnement Python -
%flink.ssql– Fournit un environnement SQL de streaming -
%flink.bsql– Fournit un environnement SQL par lots
Prérequis
-
L'intégration de Zeppelin à Flink est prise en charge pour les clusters créés avec Amazon EMR 6.10.0 et versions ultérieures.
-
Pour afficher les interfaces Web hébergées sur des clusters EMR conformément à ces étapes, vous devez configurer un tunnel SSH pour autoriser l'accès entrant. Pour plus d'informations, consultez la rubrique Configuration des paramètres de proxy pour afficher les sites web hébergés sur le nœud primaire.
Configurer Zeppelin-Flink sur un cluster EMR
Procédez comme suit pour configurer Apache Flink sur Apache Zeppelin afin qu'il s'exécute sur un cluster EMR :
-
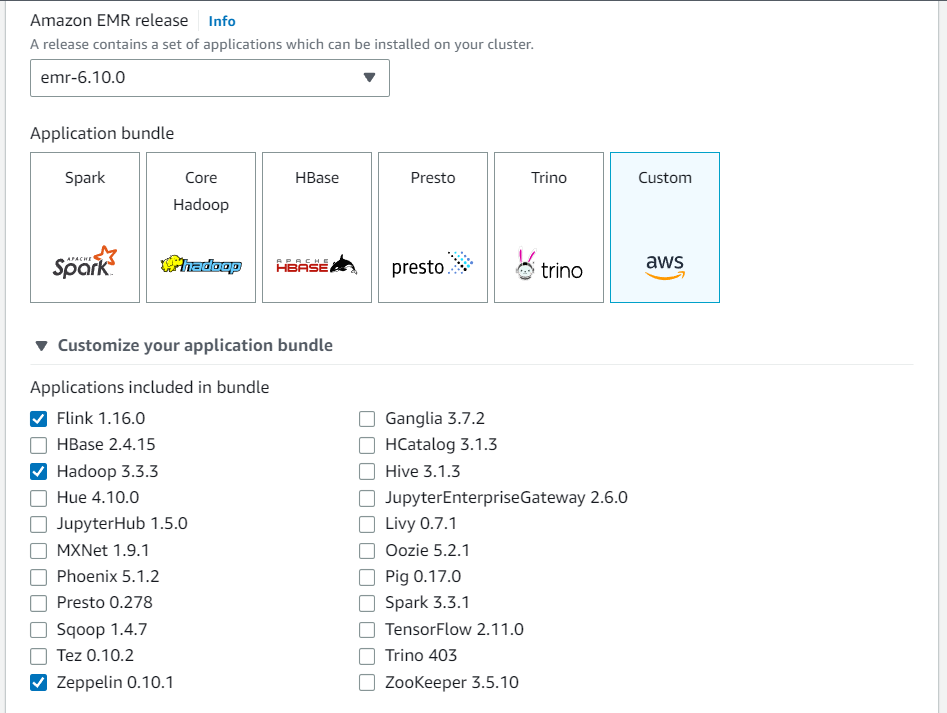
Créez un nouveau cluster depuis la console Amazon EMR. Sélectionnez emr-6.10.0 ou supérieur pour la version Amazon EMR. Choisissez ensuite de personnaliser votre bundle d'applications avec l'option Personnaliser. Incluez au moins Flink, Hadoop et Zeppelin dans votre offre groupée.
-
Créez le reste de votre cluster avec les paramètres que vous préférez.
-
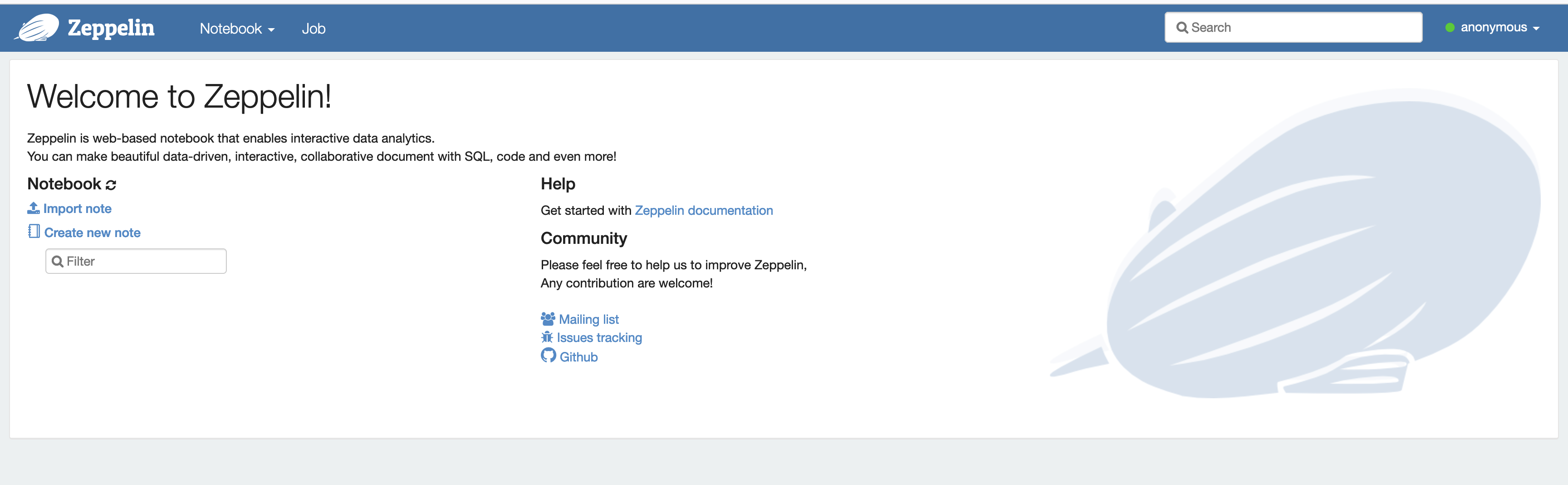
Une fois que votre cluster est en cours d'exécution, sélectionnez-le dans la console pour afficher ses détails et ouvrez l'onglet Applications. Sélectionnez Zeppelin dans la section Interfaces utilisateur de l'application pour ouvrir l'interface Web Zeppelin. Assurez-vous d'avoir configuré l'accès à l'interface Web Zeppelin avec un tunnel SSH vers le nœud primaire et une connexion proxy, comme décrit dans le Prérequis.
-
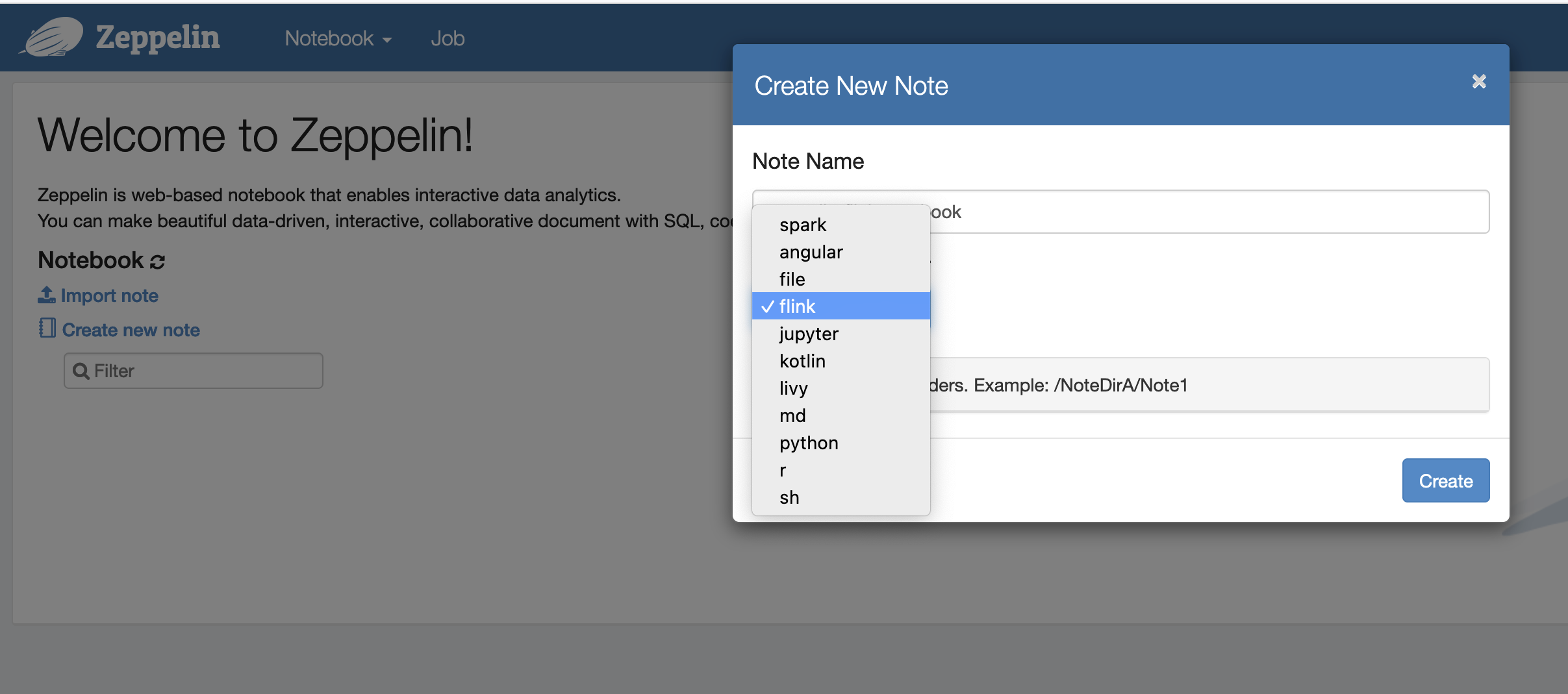
Vous pouvez désormais créer une nouvelle note dans un carnet Zeppelin avec Flink comme interpréteur par défaut.
-
Reportez-vous aux exemples de code suivants qui montrent comment exécuter des tâches Flink à partir d'un bloc-notes Zeppelin.
Exécuter des tâches Flink avec Zeppelin-Flink sur un cluster EMR
-
Exemple 1, Flink Scala
a) WordCount Exemple de lot (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) WordCount Exemple de streaming (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()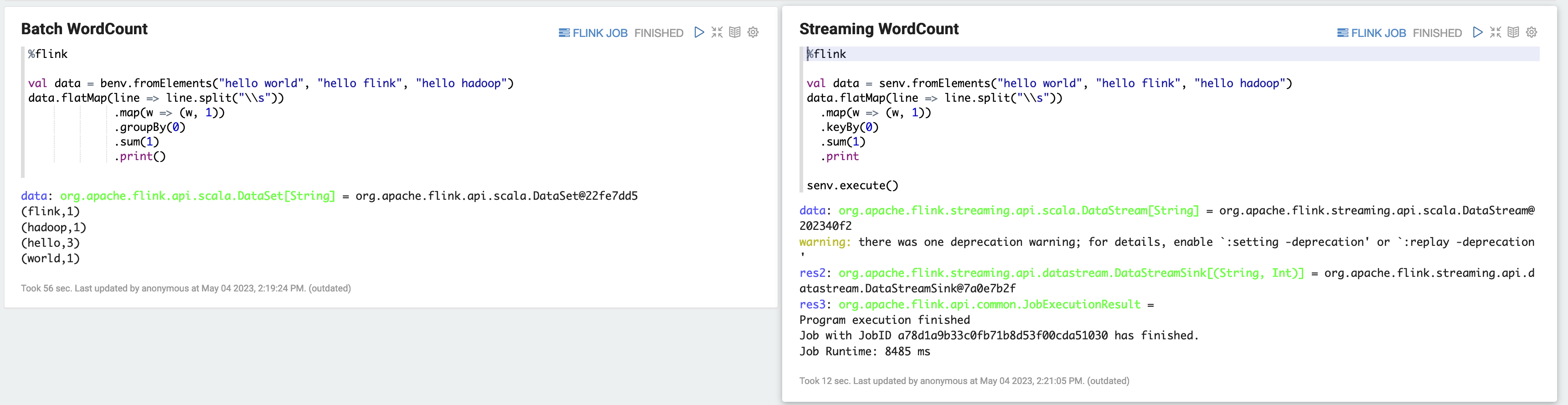
-
Exemple 2, Flink Streaming SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;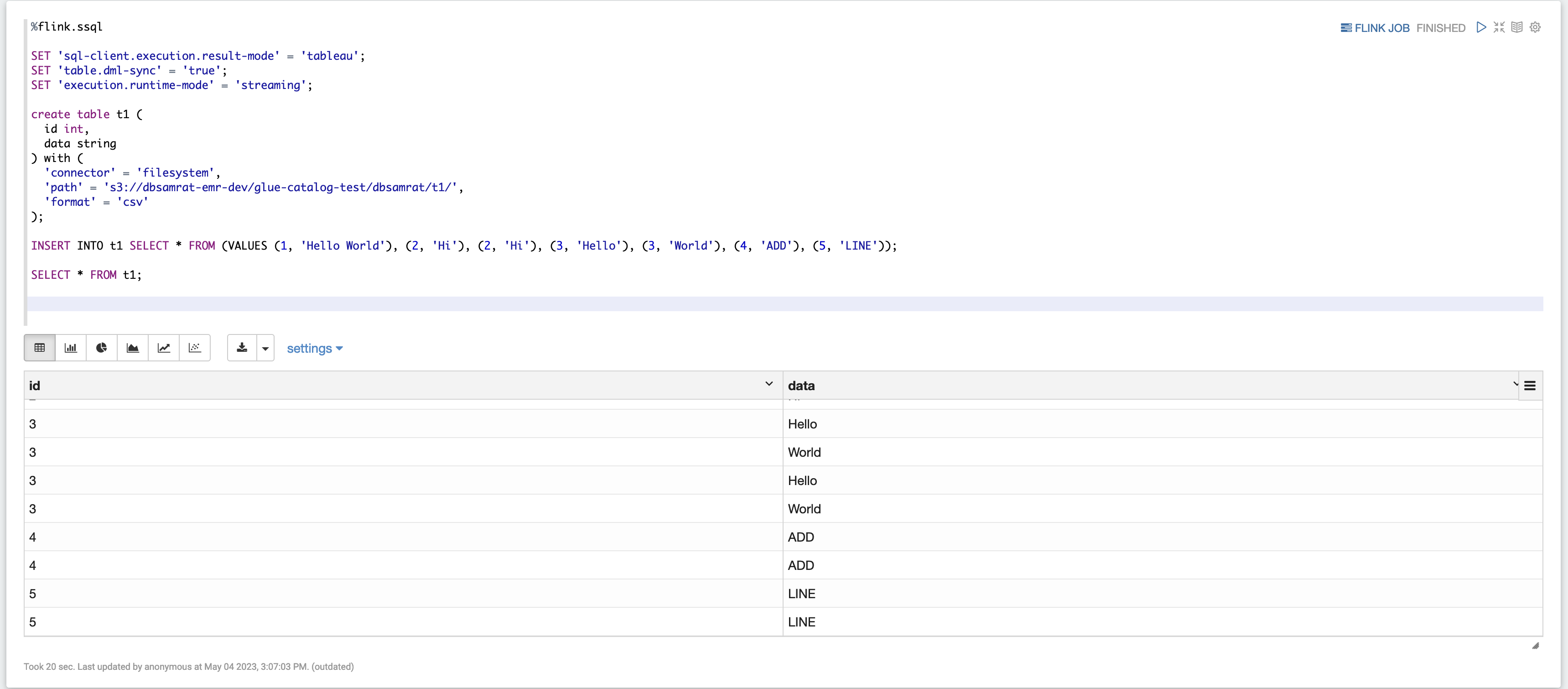
-
Exemple 3, Pyflink. Notez que vous devez télécharger votre propre exemple de fichier texte nommé
word.txtdans votre compartiment S3.%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
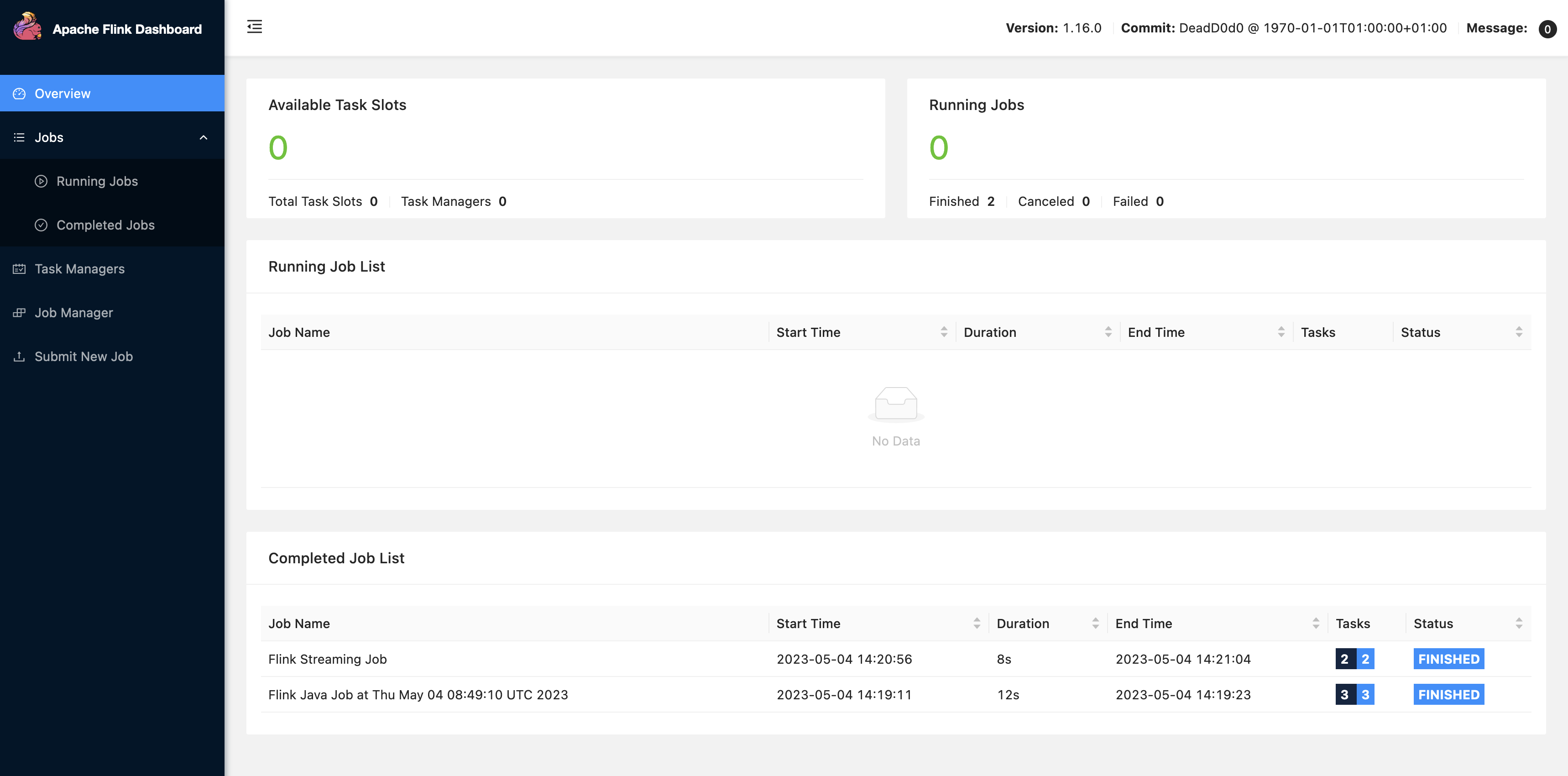
Choisissez FLINK JOB dans l'interface utilisateur Zeppelin pour accéder à l'interface utilisateur Web de Flink et l'afficher.

-
Lorsque vous choisissez FLINK JOB, vous accédez à la console Web Flink dans un autre onglet de votre navigateur.