Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de robots d'exploration pour alimenter le catalogue de données
Vous pouvez utiliser an AWS Glue crawler pour les renseigner AWS Glue Data Catalog avec des bases de données et des tables. Il s'agit de la principale méthode utilisée par la plupart des AWS Glue utilisateurs. Un crawler peut analyser plusieurs magasins de données en une seule fois. À la fin de cette opération, l'crawler crée ou met à jour une ou plusieurs tables dans votre Data Catalog. Les tâches Extract-transform-load (ETL) que vous définissez dans AWS Glue utilisent ces tables Data Catalog en tant que sources et cibles. La tâche ETL lit et écrit dans les magasins de données qui sont spécifiés dans les tables Data Catalog sources et cibles.
Flux de travail
Le diagramme de flux de travail suivant montre comment les crawlers AWS Glue interagissent avec magasins de données et d'autres éléments pour remplir le catalogue de données.

Voici comment un crawler remplit le AWS Glue Data Catalog :
-
Un crawler exécute tous les classifieurs personnalisés que vous choisissez pour déduire le format et le schéma de vos données. Vous fournissez le code pour les classifieurs personnalisés, lesquels s'exécutent dans l'ordre que vous spécifiez.
Le premier classifieur personnalisé qui reconnaît avec succès la structure de vos données est utilisé pour créer un schéma. Les classifieurs personnalisés en bas de la liste sont ignorés.
-
Si aucun classifieur ne correspond au schéma de vos données, les classifieurs intégrés essaient de reconnaître le schéma de données. Un exemple de classifieur intégré est un classifieur qui reconnaît JSON.
-
L'crawler se connecte au magasin de données. Certains magasins de données nécessitent les propriétés de connexion pour l'accès de l'crawler.
-
Le schéma déduit est créé pour vos données.
-
L'crawler écrit les métadonnées dans le catalogue de données. Une définition de table contient les métadonnées sur les données de votre magasin de données. La table est écrite dans une base de données, qui est un conteneur de tables du catalogue de données. Les attributs d'une table incluent la classification, qui est une étiquette créé par le classifieur ayant déduit du schéma de la table.
Rubriques
Fonctionnement des crawlers
Lorsqu'un crawler s'exécute, il prend les actions suivantes pour interroger un magasin de données :
-
Classe les données pour déterminer le format, le schéma et les propriétés associées des données brutes – Vous pouvez configurer les résultats de la classification en créant un classifieur personnalisé.
-
Groupes les données en tables ou en partitions – Les données sont regroupées en fonction de l'heuristique de l'crawler.
-
Writes metadata to the Data Catalog (Écrit les métadonnées sur Data Catatlog) – vous pouvez configurer la façon dont l'crawler ajoute, met à jour et supprime les tables et les partitions.
Lorsque vous définissez un crawler, vous choisissez un ou plusieurs classifieurs qui évaluent le format de vos données pour déduire un schéma. Lorsque l'crawler s'exécute, le premier classifieur de la liste qui reconnaît correctement votre magasin de données est utilisé pour créer un schéma pour votre table. Vous pouvez utiliser des classifieurs intégrés ou définir les vôtres. Vous définissez vos classifieurs personnalisés dans une autre opération, avant de définir les crawlers. AWS Glue fournit des classifieurs intégrés pour déduire les schémas les plus répandus qui incluent les formats de fichiers JSON, CSV et Apache Avro. Pour obtenir la liste actuelle des classifieurs intégrés dans AWS Glue, consultez Classificateurs intégrés.
Les tables de métadonnées créées par un crawler sont contenues dans une base de données lorsque vous définissez un crawler. Si votre crawler ne spécifie pas de base de données, vos tables sont placées dans la base de données par défaut. En outre, chaque table dispose d'une colonne de classification remplie par le premier classifieur qui reconnaît correctement le magasin de données.
Si le fichier analysé est compressé, l'crawler doit le télécharger afin de le traiter. Lorsqu'un crawler s'exécute, il interroge les fichiers pour déterminer leur format et leur type de compression, et écrit ces propriétés dans Data Catalog. Certains formats de fichier (Apache Parquet, par exemple), vous permettent de compresser des parties du fichier au moment de son écriture. Pour ces fichiers, les données compressées sont un composant interne du fichier et AWS Glue ne renseigne pas la propriété compressionType lors de l'écriture des tables dans Data Catalog. En revanche, si un fichier complet est compressé par un algorithme de compression (par exemple, gzip), la propriété compressionType est alors renseignée lorsque les tables sont écrites dans Data Catalog.
L'crawler génère les noms pour les tables qu'il crée. Les noms des tables stockées dans le sont conformes aux AWS Glue Data Catalog règles suivantes :
-
Seuls les caractères alphanumériques et les traits de soulignement (
_) sont autorisés. -
Un préfixe personnalisé ne doit pas comporter plus de 64 caractères.
-
La longueur maximale du nom ne doit pas dépasser 128 caractères. L'crawler tronque les noms générés pour les ajuster à la limite.
-
En cas de noms de table en double, l'crawler ajoute un suffixe de chaîne de hachage au nom.
Si votre crawler s'exécute plusieurs fois, par exemple sur un calendrier, il recherche les tables et les fichiers nouveaux ou modifiés dans votre magasin de données. La sortie de l'crawler inclut les nouvelles tables et partitions trouvées depuis l'exécution précédente.
Comment un crawler détermine quand créer des partitions ?
Lorsqu'un AWS Glue robot d'exploration analyse la banque de données Amazon S3 et détecte plusieurs dossiers dans un compartiment, il détermine la racine d'une table dans la structure des dossiers et les dossiers qui sont des partitions d'une table. Le nom de la table est basé sur le préfixe Amazon S3 ou le nom de dossier. Vous fournissez un chemin Include qui pointe vers le niveau de dossier à analyser. Lorsque la majorité des schémas au niveau d'un dossier sont similaires, l'crawler crée les partitions d'une table au lieu de tables distinctes. Pour influencer l'crawler et créer des tables distincts, ajoutez le dossier racine de chaque table en tant que magasin de données séparé lorsque vous définissez l'crawler.
Prenons l'exemple de la structure de dossiers Amazon S3 suivante.
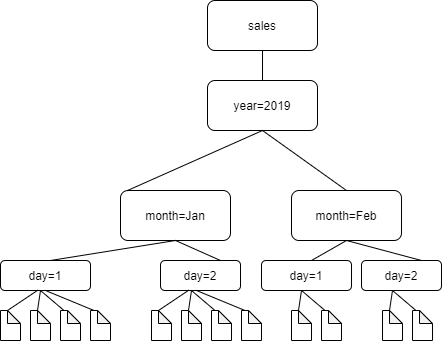
Les chemins d'accès aux quatre dossiers de niveau inférieur sont les suivants :
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
Supposons que la cible de l'crawler est définie sur Sales et que tous les fichiers des dossiers day=n ont le même format (par exemple, JSON, non chiffré) et ont des schémas identiques ou très similaires. L'crawler créera une seule table avec quatre partitions, avec les clés de partition year,month et day.
Dans l'exemple suivant, observez la structure Amazon S3 suivante :
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
Si les schémas pour les fichiers sous table1 et table2 sont similaires, et qu'un seul magasin de données est défini dans l'crawler avec Include path s3://bucket01/folder1/, l'crawler crée une seule table avec deux colonnes de clés de partition. La première colonne de clé de partition contient table1 et table2, et la deuxième colonne de clé de partition contient partition1 à partition3 pour la partition table1, et partition4 et partition5 pour la partition table2. Pour créer deux tables distinctes, définissez l'crawler avec deux magasins de données. Dans cet exemple, définissez le premier Include path comme s3://bucket01/folder1/table1/ et le second comme s3://bucket01/folder1/table2.
Note
Dans Amazon Athena, chaque table correspond à un préfixe Amazon S3 avec tous les objets qu'il contient. Si les objets ont des schémas différents, Athena ne reconnaît pas les différents objets au sein du même préfixe comme des tables distinctes. Cela peut se produire si un crawler crée plusieurs tables à partir du même préfixe Amazon S3. Il peut en résulter que des requêtes dans Athena ne renvoient aucun résultat. Pour qu'Athena reconnaisse et interroge correctement les tables, créez l'crawler avec un Include path (chemin d'inclusion) distinct pour chaque schéma de table différent dans la structure de dossier Amazon S3. Pour plus d'informations, consultez Bonnes pratiques lors de l'utilisation d'Athena avec AWS Glue et cet article du Centre de connaissances AWS
