Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation des plans dans AWS Glue
Note
La fonctionnalité Blueprints n'est actuellement pas disponible dans les régions suivantes de la console AWS Glue : Asie-Pacifique (Jakarta) et Moyen-Orient (Émirats arabes unis).
Les plans AWS Glue offrent un moyen de créer et de partager des flux de travail AWS Glue. Lorsqu'il existe un processus ETL complexe qui pourrait être utilisé pour des cas d'utilisation similaires, plutôt que de créer un flux de travail AWS Glue pour chaque cas d'utilisation, vous pouvez créer un seul plan.
Le modèle spécifie les tâches et les crawlers à inclure dans un flux de travail, et spécifie les paramètres que l'utilisateur du flux de travail fournit lorsqu'il exécute le modèle pour créer un flux de travail. L'utilisation de paramètres permet à un seul modèle de générer des flux de travail pour les différents cas d'utilisation similaires. Pour de plus amples informations sur les flux de travail, veuillez consulter Présentation des flux de travail dans AWS Glue.
Voici quelques exemples de cas d'utilisation pour les modèles :
-
Vous souhaitez partitionner un jeu de données existant. Les paramètres d'entrée du modèle sont Amazon Simple Storage Service (Amazon S3) et une liste pour les colonnes de partition.
-
Vous souhaitez créer un instantané d'une table Amazon DynamoDB dans un magasin de données SQL comme Amazon Redshift. Les paramètres d'entrée du plan sont le nom de la table DynamoDB et une connexion AWS Glue, qui désigne un cluster Amazon Redshift et une base de données de destination.
-
Vous souhaitez convertir les données CSV dans plusieurs chemins Amazon S3 en Parquet. Vous souhaitez que le flux de travail AWS Glue inclue un crawler et une tâche distincts pour chaque chemin. Les paramètres d'entrée sont la base de données de destination dans le catalogue de données AWS Glue et une liste délimitée par des virgules de chemins Amazon S3. Notez que dans ce cas, le nombre d'crawlers et de tâches créés par le flux de travail est variable.
Composants du plan
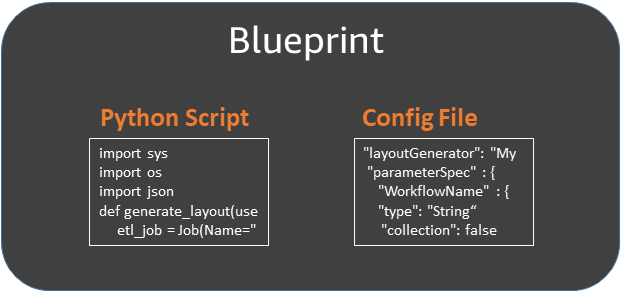
Un modèle est une archive ZIP qui contient les composants suivants :
-
Un script de générateur de mise en page Python
Contient une fonction qui spécifie la disposition du flux de travail : les crawlers et les tâches à créer pour le flux de travail, les propriétés de la tâche et de l'crawler et les dépendances entre les tâches et les crawlers. La fonction accepte les paramètres de plan et renvoie une structure de flux de travail (objet JSON) que AWS Glue utilise pour générer le flux de travail. Étant donné que vous utilisez un script Python pour générer le flux de travail, vous pouvez ajouter votre propre logique adaptée à vos cas d'utilisation.
-
Un fichier de configuration
Spécifie le nom complet de la fonction Python qui génère la disposition du flux de travail. Spécifie également les noms, types de données et autres propriétés de tous les paramètres de modèle utilisés par le script.
-
(Facultatif) scripts ETL et fichiers de support
En tant que cas d'utilisation avancé, vous pouvez paramétrer l'emplacement des scripts ETL que vos tâches utilisent. Vous pouvez inclure des fichiers de script de tâche dans l'archive ZIP et spécifier un paramètre de modèle pour un emplacement Amazon S3 vers lequel les scripts doivent être copiés. Le script du générateur de mise en page peut copier les scripts ETL à l'emplacement désigné et spécifier cet emplacement en tant que propriété d'emplacement du script de tâche. Vous pouvez également inclure des bibliothèques ou d'autres fichiers de support, à condition que votre script les gère.
Exécutions de modèle
Lorsque vous créez un flux de travail à partir d'un plan, AWS Glue exécute le plan, qui démarre un processus asynchrone pour créer le flux de travail et les tâches, les moteurs d'exploration et les déclencheurs que le flux de travail encapsule. AWS Glue utilise l'exécution du plan pour orchestrer la création du flux de travail et de ses composantes. Vous affichez le statut du processus de création en affichant le statut d'exécution du modèle. L'exécution du modèle stocke également les valeurs que vous avez fournies pour les paramètres du modèle.
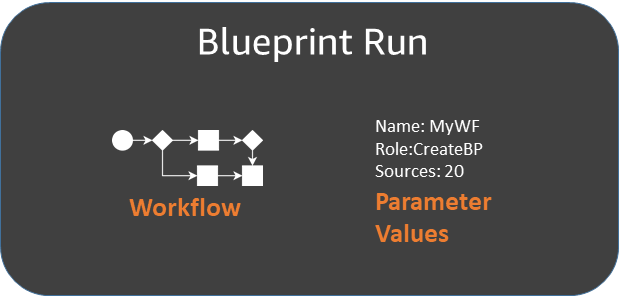
Vous pouvez afficher les exécutions du plan à l'aide de la AWS Glue console ou AWS Command Line Interface (AWS CLI). Lors de l'affichage ou du dépannage d'un flux de travail, vous pouvez toujours revenir à l'exécution du modèle pour afficher les valeurs des paramètres de modèle qui ont été utilisées pour créer le flux de travail.
Cycle de vie d'un plan
Les plans sont développés, testés, enregistrés auprès de AWS Glue et exécutés pour créer des flux de travail. Il existe généralement trois personas impliquées dans le cycle de vie du modèle.
| Persona | Tâches |
|---|---|
| Développeur AWS Glue |
|
| administrateur AWS Glue |
|
| Analyste des données |
|
Consultez aussi
