Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS Glue concepts
AWS Glue est un service ETL (extraction, transformation, chargement) entièrement géré qui vous permet de déplacer facilement des données entre différentes sources de données et cibles. Les principaux composants sont les suivants :
-
Catalogue de données : magasin de métadonnées contenant des définitions de tables, des définitions de tâches et d'autres informations de contrôle pour vos flux de travail ETL.
-
Crawlers : programmes qui se connectent à des sources de données, déduisent des schémas de données et créent des définitions de tables de métadonnées dans le catalogue de données.
-
Tâches ETL : logique métier permettant d'extraire les données des sources, de les transformer à l'aide de scripts Apache Spark et de les charger dans des cibles.
-
Déclencheurs : mécanismes permettant de lancer des exécutions de tâches en fonction de calendriers ou d'événements.
Le flux de travail typique implique :
-
Définissez les sources de données et les cibles dans le catalogue de données.
-
Utilisez les robots d'exploration pour renseigner le catalogue de données avec des métadonnées de table provenant de sources de données.
-
Définissez des tâches ETL à l'aide de scripts de transformation pour déplacer et traiter les données.
-
Exécutez des tâches à la demande ou en fonction de déclencheurs.
-
Surveillez les performances au travail à l'aide de tableaux de bord.
Le schéma suivant montre l'architecture d'un AWS Glue environnement.
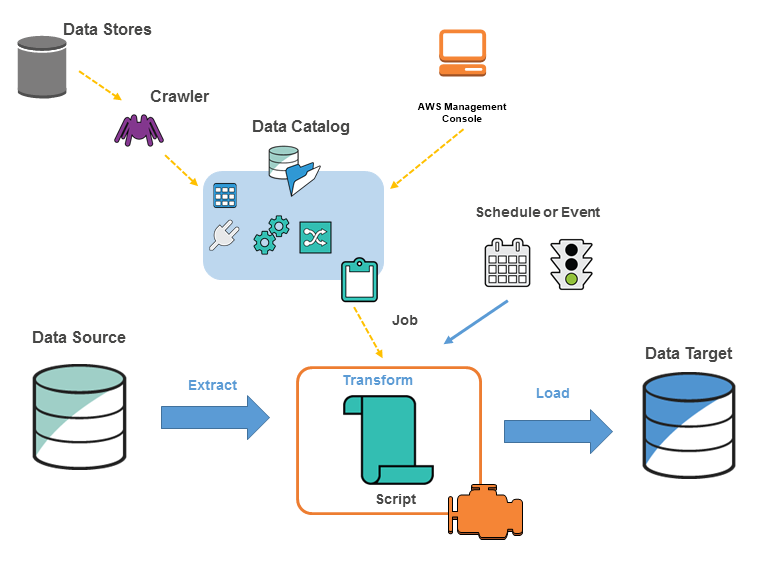
Vous définissez des tâches AWS Glue pour accomplir le travail requis pour extraire, transformer et charger des données (ETL) d'une source de données vers une cible de données. Généralement, vous effectuez les actions suivantes :
-
Pour les sources de magasins de données, vous définissez un crawler pour remplir votre AWS Glue Data Catalog avec les définitions de table des métadonnées. Vous associez votre crawler à un magasin de données, et le crawler crée les définitions de table dans le catalogue de données. Pour les sources en streaming, vous définissez manuellement les tables du catalogue de données et spécifiez les propriétés du flux des données.
Outre les définitions de tables, le AWS Glue Data Catalog contient d'autres métadonnées nécessaires pour définir les tâches ETL. Vous utilisez ces métadonnées lorsque vous définissez une tâche pour transformer vos données.
AWS Glue peut générer un script pour transformer vos données. Vous pouvez également fournir le script dans la AWS Glue console ou dans l'API.
-
Vous pouvez exécuter votre tâche à la demande ou la configurer pour qu'elle démarre lorsqu'un déclencheur spécifié est mis en action. Le déclencheur peut être une planification temporelle ou un événement.
Lorsque votre tâche s'exécute, un script extrait les données de la source de données, les transforme et les charge sur la cible de données. Le script s'exécute dans un environnement Apache Spark, dans AWS Glue.
Important
Les tables et les bases de données dans AWS Glue sont des objets dans le AWS Glue Data Catalog. Elles contiennent des métadonnées, mais aucune donnée d'un magasin de données.
|
Les données textuelles, telles que CSVs, doivent être codées |
AWS Glue terminologie
AWS Glue repose sur l'interaction de plusieurs composants pour créer et gérer votre flux de travail d'extraction, de transformation et de chargement (ETL).
AWS Glue Data Catalog
Les métadonnées persistantes sont stockées dans AWS Glue. Il contient des définitions de tables, des définitions de tâches et d'autres informations de contrôle pour gérer votre AWS Glue environnement. Chaque AWS compte en possède un AWS Glue Data Catalog par région.
Classifieur
Détermine le schéma de vos données. AWS Glue fournit des classificateurs pour les types de fichiers courants, tels que CSV, JSON, AVRO, XML, etc. Il fournit également les classifieurs des systèmes de gestion de base de données relationnelle (SGBDR) utilisant une connexion JDBC. Vous pouvez écrire votre propre classifieur à l'aide d'un modèle grok ou en spécifiant une balise de ligne dans un document XML.
Connexion
Un objet de catalogue de données qui contient les propriétés requises pour se connecter à un magasin de données particulier.
crawler
Programme qui se connecte à un magasin de données (source ou cible), parcourt la liste hiérarchisée des classifieurs pour déterminer le schéma de vos données, puis crée des tables de métadonnées dans l' AWS Glue Data Catalog.
Base de données
Ensemble de définitions de tables du catalogue de données associées, organisées en un groupe logique.
Stockage de données, source de données, cible de données
Un magasin de données est un référentiel qui permet de stocker vos données de façon permanente. Les exemples incluent les compartiments Amazon S3 et les bases de données relationnelles. Une source de données est un magasin de données qui est utilisé comme entrée d'un processus ou d'une transformation. Une cible de données est un magasin de données dans lequel écrit un processus ou une transformation.
Point de terminaison de développement
Un environnement que vous pouvez utiliser pour développer et tester vos scripts AWS Glue ETL.
Trame dynamique
Table distribuée qui prend en charge les données imbriquées telles que les structures et les tableaux. Chaque enregistrement est auto-descriptif, conçu pour une flexibilité de schéma avec des données semi-structurées. Chaque enregistrement contient à la fois les données et le schéma qui les décrit. Vous pouvez utiliser à la fois des cadres dynamiques et Apache Spark DataFrames dans vos scripts ETL, et effectuer des conversions entre eux. Les trames dynamiques fournissent un ensemble de transformations avancées pour le nettoyage des données, ainsi que pour l'extraction, le transfert et le chargement.
Tâche
Logique métier requise pour exécuter un travail d'extraction, de transformation et de chargement (ETL). Elle se compose d'un script de transformation, de sources de données et de cibles de données. Les exécutions des tâches sont initiées par les déclencheurs qui peuvent être planifiés ou mis en action par des événements.
Tableau de bord de performance de tâche
AWS Glue fournit un tableau de bord d'exécution complet pour vos tâches ETL. Le tableau de bord affiche des informations sur les exécutions de tâche à partir d'une période spécifique.
Interface de bloc-notes
Une expérience de bloc-notes améliorée grâce à une configuration en un clic pour faciliter la création des tâches et l'exploration des données. Le bloc-notes et les connexions sont configurés automatiquement pour vous. Vous pouvez utiliser l'interface du bloc-notes basée sur Jupyter Notebook pour développer, déboguer et déployer des scripts et des flux de travail de manière interactive à l'aide de l'infrastructure ETL Apache Spark AWS Glue sans serveur. Vous pouvez également effectuer des requêtes ad hoc, des analyses de données et des visualisations (par exemple, des tableaux et des graphiques) dans l'environnement de bloc-notes.
Script
Code qui extrait les données des sources, les transforme et les charge dans des cibles. AWS Glue génère PySpark ou des scripts Scala.
Tableau
Définition de métadonnées qui représente vos données. Que les données se trouvent dans un fichier Amazon Simple Storage Service (Amazon S3), une table Amazon Relational Database Service (Amazon RDS) ou un autre jeu de données, une table définit le schéma de vos données. Un tableau AWS Glue Data Catalog contient les noms des colonnes, les définitions des types de données, les informations de partition et les autres métadonnées relatives à un jeu de données de base. Le schéma de vos données est représenté dans la définition de votre AWS Glue table. Les données réelles restent dans leur magasin de données d'origine, qu'il s'agisse d'un fichier ou d'une table de base de données relationnelle. AWS Glue catalogue vos fichiers et vos tables de base de données relationnelle dans le. AWS Glue Data Catalog Ils sont utilisés comme sources et cibles lorsque vous créez une tâche ETL.
Transformation
Logique de code qui permet de manipuler les données dans un format différent.
Déclencheur
Démarre une tâche ETL. Les déclencheurs peuvent être définis selon une heure planifiée ou un événement.
Éditeur de tâche visuel
L'éditeur visuel est une interface graphique qui facilite la création, l'exécution et le contrôle des tâches d'Extraction, transformation et chargement (ETL) dans AWS Glue. Vous pouvez composer visuellement des flux de travail de transformation des données, les exécuter AWS Glue de manière fluide sur le moteur ETL sans serveur basé sur Apache Spark et inspecter le schéma et les résultats des données à chaque étape du travail.
Nœuds
Avec AWS Glue, vous ne payez que pour le temps nécessaire à l'exécution de votre tâche ETL. Il n'y a pas de ressources à gérer, pas de coûts initiaux et les temps de démarrage ou d'arrêt ne vous sont pas facturés. Un taux horaire vous est facturé en fonction du nombre d'unités de traitement des données (ou DPUs) utilisées pour exécuter votre tâche ETL. Une seule unité de traitement des données (DPU) est également appelée « travailleur ». AWS Glue propose plusieurs types de travailleurs pour vous aider à sélectionner la configuration qui répond à vos exigences en matière de latence et de coûts. Les utilisateurs sont disponibles dans des configurations Standard, G-1X, G.2X, G.4X, G.8X, G.12X, G.16X, G.025X, et des configurations R.1X, R.2X, R.4X, R.8X optimisées pour la mémoire.
