Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Détecter et traiter les données sensibles
La transformation Detect PII identifie les informations personnelles identifiables (PII) dans votre source de données. Vous choisissez l'entité PII à identifier, la manière dont vous voulez que les données soient analysées et ce qui doit être fait avec l'entité PII qui a été identifiée par la transformation Detect PII.
La transformation Détecter les PII permet de détecter, masquer ou supprimer des entités que vous définissez ou qui sont prédéfinies par AWS. Cela vous permet d'accroître la conformité et de réduire la responsabilité. Par exemple, vous voudrez peut-être vous assurer qu'aucune information personnelle ne peut être lue dans vos données et masquer les numéros de sécurité sociale avec une chaîne fixe (telle que xxx-xx-xxxx), des numéros de téléphone ou des adresses.
Pour travailler avec des données sensibles en dehors de AWS Glue Studio, consultez Utilisation de la détection des données sensibles en dehors de AWS Glue Studio
Rubriques
Choix du mode d'analyse des données
Lorsque vous analysez votre jeu de données à la recherche de données sensibles telles que des données d'identification personnelle (PII), vous pouvez choisir de détecter les données d'identification personnelle dans chaque ligne ou de détecter les colonnes contenant des données d'identification personnelle.
Lorsque vous choisissez Detect PII in each cell (Détectez les PII dans chaque cellule), vous choisissez d'analyser toutes les lignes de la source de données. Il s'agit d'une analyse complète qui permet de s'assurer que les entités PII sont identifiées.
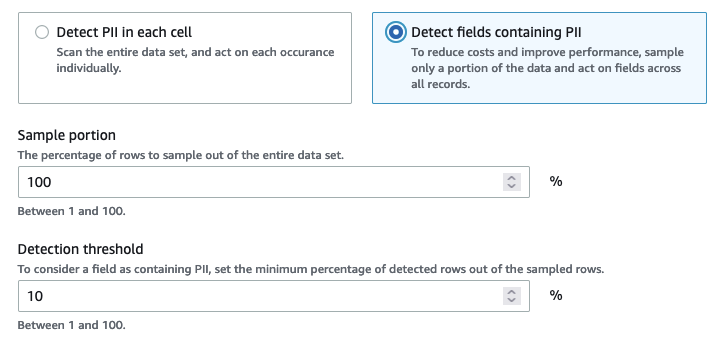
Lorsque vous choisissez Detect fields containing PII (Détecter les champs contenant des informations personnelles identifiables), vous choisissez d'analyser un échantillon de lignes à la recherche d'entités PII. Il s'agit d'un moyen de réduire les coûts et les ressources tout en identifiant les champs dans lesquels les entités PII sont trouvées.
Lorsque vous choisissez de détecter des champs contenant des informations personnelles, vous pouvez réduire les coûts et améliorer les performances en échantillonnant une partie de lignes. Le choix de cette option vous permettra de spécifier des options supplémentaires :
-
Portion d'échantillon : vous permet de spécifier le pourcentage de lignes à échantillonner. Par exemple, si vous saisissez « 50 », vous spécifiez que vous voulez que 50 % des lignes soient analysées pour l'entité PII.
-
Seuil de détection : vous permet de préciser le pourcentage de lignes contenant l'entité PII afin que la colonne entière soit identifiée comme ayant l'entité PII. Par exemple, si vous saisissez le nombre « 10 », vous spécifiez que le numéro de l'entité PII, US Phone, dans les lignes analysées doit être égal ou supérieur à 10 % pour que le champ soit identifié comme ayant l'entité PII, US Phone. Si le pourcentage de lignes contenant l'entité PII est inférieur à 10 %, ce champ ne sera pas étiqueté comme comportant l'entité PII, US Phone, dans celui-ci.
Choix des entités PII à détecter
Si vous avez choisi Detect PII in each cell (Détectez les PII dans chaque cellule), vous pouvez choisir parmi trois options :
-
Tous les modèles d'informations personnelles disponibles, y compris AWS les entités.
-
Sélectionnez des catégories : les modèles PII incluent automatiquement des modèles dans les catégories que vous sélectionnez.
-
Sélectionnez des modèles spécifiques : seuls les modèles que vous sélectionnez seront détectés.
Pour afficher la liste complète des types de données sensibles gérés, consultez Managed data types.
Choisir parmi tous les modèles PII disponibles
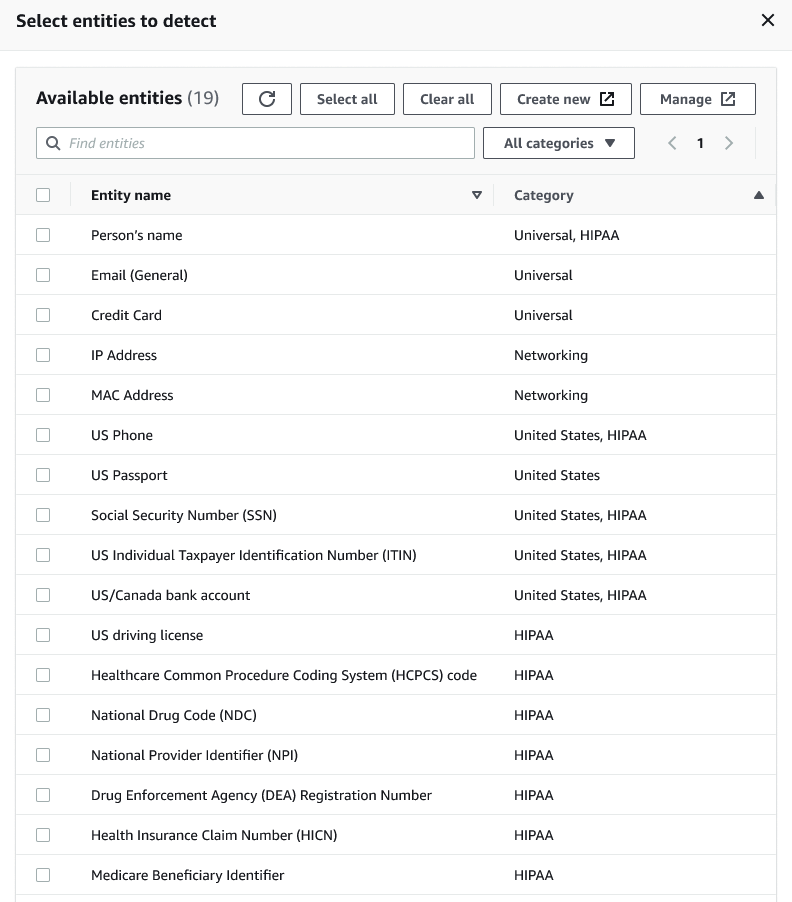
Si vous sélectionnez Tous les modèles d'informations personnelles disponibles, sélectionnez les entités prédéfinies par. AWS Vous pouvez sélectionner une, plusieurs ou toutes les entités.
Sélectionner des catégories
Si vous avez choisi Select categories (Sélectionner des catégories) comme les modèles PII à détecter, vous pouvez sélectionner les options du menu déroulant. Notez que certaines entités peuvent appartenir à plusieurs catégories. Par exemple, Nom de la personne est une entité appartenant aux catégories Universel et HIPAA.
-
Universel (exemples : e-mail, carte de crédit)
-
HIPAA (exemples : permis de conduire américain, code du Healthcare Common Procedure Coding System (HCPCS))
-
Réseaux (exemples : adresse IP, adresse MAC)
Argentine
Australie
Autriche
Belgique
Bosnie
Bulgarie
Canada
Chili
Colombie
Croatie
Chypre
Tchéquie
Danemark
Estonie
Finlande
France
Allemagne
Grèce
Hongrie
Irlande
Corée
Japon
Mexique
Pays-Bas
Nouvelle-Zélande
Norvège
Portugal
Roumanie
Singapour
Slovaquie
Slovénie
Espagne
Suède
Suisse
Turquie
Ukraine
États-Unis
Royaume-Uni
Venezuela
Sélectionner des modèles spécifiques
Si vous choisissez Select specific patterns (Sélectionner des modèles spécifiques) en tant que modèles PII à détecter, vous pouvez rechercher ou parcourir une liste de modèles que vous avez déjà créés, ou créer un modèle d'entité de détection.
Les étapes ci-dessous décrivent comment créer un nouveau modèle personnalisé pour détecter des données sensibles. Vous allez créer le modèle personnalisé en saisissant un nom pour le modèle personnalisé, en ajoutant une expression régulière et, éventuellement, en définissant des mots contextuels.
-
Pour créer un modèle, cliquez sur le bouton Créer un nouveau

-
Dans la page Créer une entité de détection, saisissez le nom de l'entité et une expression régulière. L'expression régulière (Regex) est ce que AWS Glue utilisera pour faire correspondre des entités.
-
Cliquez sur Valider. Si la validation est réussie, un message de confirmation s'affiche indiquant que la chaîne est une expression régulière valide. Si la validation échoue, vous verrez un message indiquant que la chaîne n'est pas conforme au formatage approprié et aux littéraux de caractères, aux opérateurs ou aux constructions acceptés.
-
Vous pouvez choisir d'ajouter des mots contextuels en plus de l'expression régulière. Les mots contextuels peuvent augmenter la probabilité d'une correspondance. Ils peuvent être utiles dans les cas où les noms des champs ne sont pas descriptifs de l'entité. Par exemple, les numéros de sécurité sociale peuvent être nommés « SSN » ou « SS ». L'ajout de ces mots contextuels peut aider à faire correspondre l'entité.
-
Cliquez sur Créer pour créer l'entité de détection. Toutes les entités créées sont visibles dans la console AWS Glue Studio. Cliquez sur Detection entities (Entités de détection) dans le menu de navigation de gauche.
Vous pouvez modifier, supprimer ou créer des entités de détection depuis la page Entités de détection. Vous pouvez également rechercher un modèle à l'aide du champ de recherche.
Spécification du niveau de sensibilité de détection
Vous pouvez définir le niveau de sensibilité lorsque vous utilisez la détection de données sensibles.
-
Élevé : (par défaut) détecte un plus grand nombre d'entités pour les cas d'utilisation nécessitant un niveau de sensibilité plus élevé. Toutes les tâches AWS Glue créés après novembre 2023 sont automatiquement activés pour ce paramètre.
-
Faible : détecte moins d'entités et réduit le nombre de faux positifs.

Choix de ce qu'il faut faire avec les données PII identifiées
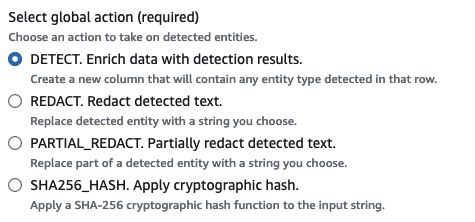
Si vous avez choisi de détecter les PII dans l'ensemble de la source de données, vous pouvez sélectionner une action globale à appliquer :
-
Enrichir les données avec des résultats de détection : Si vous avez choisi de détecter les PII dans chaque cellule, vous pouvez stocker les entités détectées dans une nouvelle colonne.
-
Remplacer le texte détecté : Vous pouvez remplacer la valeur de PII détectée par une chaîne que vous spécifiez dans le champ de saisie Remplacement de texte facultatif. Si aucune chaîne n'est spécifiée, l'entité PII détectée est remplacée par '*******'.
-
Censurer partiellement le texte détecté : vous pouvez remplacer une partie de la valeur PII détectée par une chaîne de votre choix. Deux options sont possibles : soit laisser les extrémités non masquées, soit les masquer en fournissant un modèle régulier explicite. Cette fonction n'est pas disponible dans AWS Glue 2.0.
-
Appliquer un hachage de chiffrement : vous pouvez transmettre la valeur PII détectée à une fonction de hachage de chiffrement SHA-256 et remplacer la valeur par la sortie de la fonction.
Différences entre les versions AWS Glue 2.0 et 3.0 et ultérieures
AWS GlueLes tâches 2.0 renverront une nouvelle DataFrame avec les informations PII détectées pour chaque colonne dans une colonne supplémentaire. Tout travail de censure ou de hachage est visible dans le script AWS Glue dans l'onglet visuel.
AWS GlueLes tâches 3.0 et 4.0 renverront une nouvelle DataFrame avec cette même colonne supplémentaire. Une nouvelle clé pour « actionUsed » est présente et peut être l'une des valeurs DETECT, REDACT, PARTIAL_REDACT ou SHA256_HASH. Si une action de masquage est sélectionnée, les données DataFrame seront renvoyées avec des données sensibles masquées.
Ajout des remplacements précis des actions
Des paramètres de détection et d'action supplémentaires peuvent être ajoutés à la table des remplacements précis des actions. Cela vous permet de :
-
Inclure ou exclure certaines colonnes de la détection : un schéma déduit sur la source de données remplira la table avec les colonnes disponibles.
-
Spécifier des paramètres spécifiques plus précis qu'en utilisant des actions globales : par exemple, vous pouvez spécifier différents paramètres de texte de censure pour différents types d'entités.
-
Spécifier une action différente de l'action globale : si une action différente doit être appliquée à un autre type de données sensibles, vous pouvez le faire ici. Notez que deux edit-in-place actions différentes (rédaction et hachage) ne peuvent pas être utilisées sur la même colonne, mais que la détection peut toujours être utilisée.