Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fenêtres de maintenance pour le AWS Glue streaming
AWS Glue effectue périodiquement des activités de maintenance. Au cours de ces fenêtres de maintenance, vous AWS Glue devrez redémarrer vos tâches de streaming. Vous pouvez contrôler le moment où les tâches sont redémarrées en spécifiant des fenêtres de maintenance. Dans cette section, nous expliquons où vous pouvez configurer la fenêtre de maintenance et les comportements spécifiques à prendre en compte.
Rubriques
Configuration d'une fenêtre de maintenance
Vous pouvez configurer une fenêtre de maintenance à l'aide de AWS Glue Studio ou APIs.
Configuration d'une fenêtre de maintenance dans AWS Glue Studio
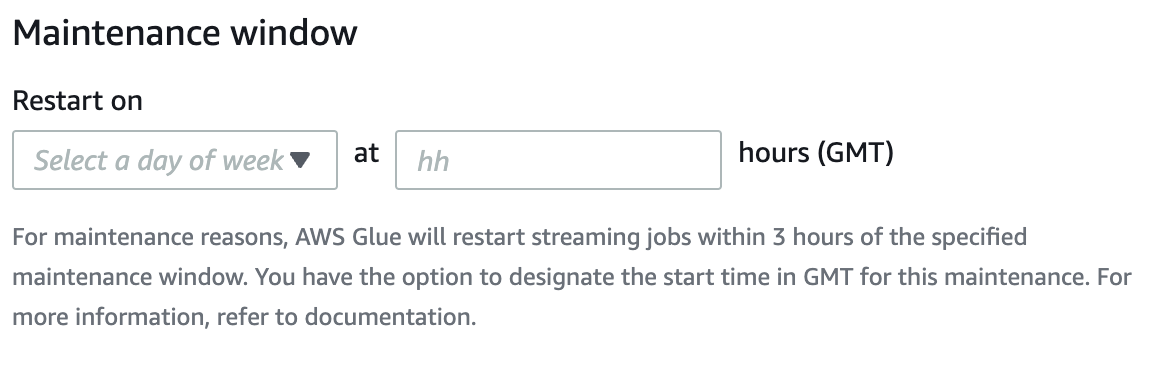
Vous pouvez spécifier une fenêtre de maintenance sur la page Détails de la tâche de AWS Glue streaming. Vous pouvez spécifier le jour et l'heure en GMT. AWS Glue redémarrera votre travail dans le délai imparti.
Configuration d'une fenêtre de maintenance dans l'API
Vous pouvez également configurer la fenêtre de maintenance dans l'API Create Job. Voici un exemple de configuration d'une fenêtre de maintenance via l'API.
aws glue create-job —name jobName —role roleArnForTheJob —command Name=gluestreaming,ScriptLocation=s3-path-to-the-script --maintenance-window="Sun:10"
Voici un exemple de commande :
aws glue create-job —name testMaintenance —role arn:aws:iam::012345678901:role/Glue_DefaultRole —command Name=gluestreaming,ScriptLocation=s3://glue-example-test/example.py —maintenance-window="Sun:10
Comportement des fenêtres de maintenance
AWS Glue passe par une série d'étapes pour décider à quel moment redémarrer une tâche :
Lorsqu'une nouvelle tâche de streaming est lancée, vérifiez AWS Glue d'abord si un délai d'expiration est associé à l'exécution de la tâche. Un délai d'attente vous permet de configurer l'heure de fin de la tâche. Si le délai d'expiration est inférieur à 7 jours, la tâche ne sera pas redémarrée.
Si le délai d'attente est supérieur à 7 jours, AWS Glue vérifie si la fenêtre de maintenance est configurée pour le travail. Si c'est le cas, cette fenêtre est sélectionnée et la fenêtre est affectée à l'exécution du travail. AWS Glue redémarrera le travail dans les 3 heures suivant la période de maintenance spécifiée. Par exemple, si vous configurez la fenêtre de maintenance pour le lundi à 10 h 00 GMT, vos tâches seront redémarrées entre 10 h 00 GMT et 13 h 00 GMT.
Si la fenêtre de maintenance n'est pas configurée, définit AWS Glue automatiquement l'heure de redémarrage sur 7 jours après le début de l'exécution du job. Par exemple, si vous avez lancé votre tâche le 1er juillet 2024 à 00h00 GMT et que vous n'avez pas spécifié de fenêtres de maintenance, votre tâche sera configurée pour redémarrer le 08/07/2024 à 00h00 GMT.
Note
Si vous exécutez déjà des jobs de streaming, cette modification aura un impact sur vous à compter du 1er juillet 2024. Vous aurez jusqu'au 30 juin pour configurer vos fenêtres de maintenance. Après le 1er juillet, toutes les tâches de streaming que vous lancez seront redémarrées conformément à cette documentation. Si vous avez besoin d'une assistance supplémentaire, vous pouvez contacter le AWS Support.
Parfois, il AWS Glue se peut que vous ne puissiez pas redémarrer le travail, en particulier lorsque le microlot en cours n'est pas traité. Dans ces cas, le travail ne sera pas interrompu. Dans ces cas, la tâche AWS Glue redémarrera au bout de 14 jours, et dans ce cas, la fenêtre de maintenance n'est pas respectée.
Surveillance des jobs
Vous pouvez surveiller les tâches sur la page AWS Glue Studio Monitoring.
Pour connaître l'heure prévue du prochain redémarrage des tâches de streaming, affichez la colonne du tableau des exécutions de tâches sur la page de surveillance.
Cliquez sur l'icône en forme d'engrenage en haut à droite du tableau.

Faites défiler la page vers le bas et activez la colonne Heure de redémarrage prévue. Les options UTC et heure locale sont disponibles.
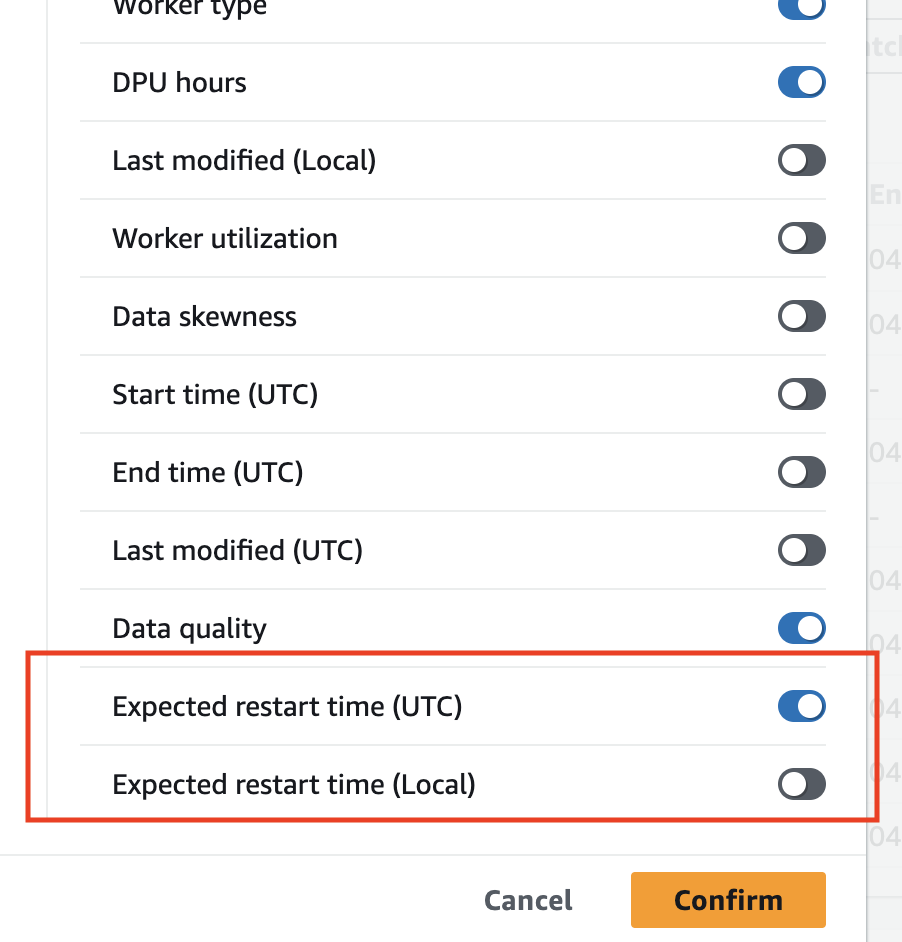
Vous pouvez ensuite afficher les colonnes du tableau.

La tâche d'origine aura le statut « EXPIRÉ » et la nouvelle instance de tâche aura le statut « EN COURS ». La nouvelle exécution de tâche qui a été redémarrée aura un ID d'exécution sous forme de concaténation de l'ID d'exécution initial et du préfixe « restart_ » représentant le nombre de redémarrages. Par exemple, si l'ID d'exécution initial de la tâche estjr_1234, l'exécution de la tâche redémarrée aura l'ID jr1234_restart_1 du premier redémarrage. Le deuxième redémarrage sera jr1234_restart_2 pour le deuxième redémarrage et ainsi de suite.
Votre nouvelle tentative ne sera pas affectée en raison des redémarrages. Si une exécution échoue et qu'une nouvelle exécution est lancée en raison d'une nouvelle tentative automatique, le compteur de redémarrage recommencera à 1. Par exemple, si une exécution échoue àjr_1234_attempt_3_restart_5, une nouvelle tentative automatique lancera une nouvelle exécution avec un ID : jr_id1_attempt_4 et lorsque cette tentative est redémarrée après 7 jours, le nouvel ID d'exécution sera. jr_id1_attempt_4_restart_1
Gestion des pertes de données
Lors des redémarrages de maintenance, AWS Glue Streaming suit un processus qui garantit l'intégrité des données et la cohérence entre le travail précédent et le travail redémarré. Notez que cela AWS Glue ne garantit pas l'intégrité et la cohérence des données entre les redémarrages des tâches et nous recommandons de prendre en compte l'architecture pour gérer les données dupliquées dans les tâches de streaming.
Détection des conditions de redémarrage pour maintenance : le AWS Glue streaming surveille les conditions qui indiquent quand un redémarrage pour maintenance doit être déclenché, par exemple lorsqu'une fenêtre de maintenance est atteinte après 7 jours ou qu'un redémarrage brutal est nécessaire après 14 jours.
Invoquer une résiliation progressive : lorsque les conditions de redémarrage pour maintenance sont remplies, AWS Glue Streaming lance un processus de résiliation progressive pour le travail en cours d'exécution. Ce processus comprend les étapes suivantes :
Arrêter l'ingestion de nouvelles données : la tâche de streaming arrête de consommer les nouvelles données provenant des sources d'entrée (par exemple, les sujets Kafka, les flux Kinesis ou les fichiers).
Traitement des données en attente : la tâche continue de traiter toutes les données déjà présentes dans ses tampons ou files d'attente internes.
Validation des décalages et des points de contrôle : la tâche valide les derniers décalages ou points de contrôle vers des systèmes externes (par exemple, Kafka, Kinesis ou Amazon S3) afin de garantir que la tâche redémarrée puisse reprendre là où la tâche précédente s'était arrêtée.
Redémarrage de la tâche : une fois le processus d'arrêt progressif terminé, AWS Glue Streaming redémarre la tâche en utilisant l'état préservé et les points de contrôle. La tâche redémarrée reprend le traitement à partir du dernier décalage ou point de contrôle validé, garantissant ainsi qu'aucune donnée n'est perdue ou dupliquée.
Reprise du traitement des données : La tâche redémarrée reprend le traitement des données à partir du point où la tâche précédente s'était arrêtée. Il continue à ingérer les nouvelles données provenant des sources d'entrée, à partir du dernier décalage ou point de contrôle validé, et traite les données conformément à la logique ETL définie.
