Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillance de la progression des tâches multiples
Vous pouvez profiler plusieurs AWS Glue tâches ensemble et surveiller le flux de données entre elles. Il s'agit d'un modèle de flux de travail courant qui nécessite la surveillance de la progression de chaque tâche, du journal de traitement des données, du retraitement des données et des signets de tâche.
Rubriques
Code profilé
Ce flux de travail comprend deux tâches : une tâche d'entrée et une tâche de sortie. La tâche d'entrée est planifiée pour s'exécuter toutes les 30 minutes au moyen d'un déclencheur périodique. La tâche de sortie est planifiée pour s'exécuter après chaque exécution réussie de la tâche d'entrée. Ces tâches planifiées sont contrôlées au moyen de déclencheurs de tâche.

Input job (Tâche d’entrée) : cette tâche lit les données à partir d'un emplacement Amazon Simple Storage Service (Amazon S3), les transforme à l'aide d'ApplyMapping et les écrit à un emplacement Amazon S3 intermédiaire. Le code suivant est le code profilé pour la tâche d'entrée :
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": ["s3://input_path"], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": staging_path, "compression": "gzip"}, format = "json")
Output job (Tâche de sortie) : cette tâche lit la sortie de la tâche d'entrée à partir de l'emplacement intermédiaire dans Amazon S3, les transforme à nouveau et les écrit dans une destination :
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "json")
Visualisez les métriques profilées sur AWS Glue console
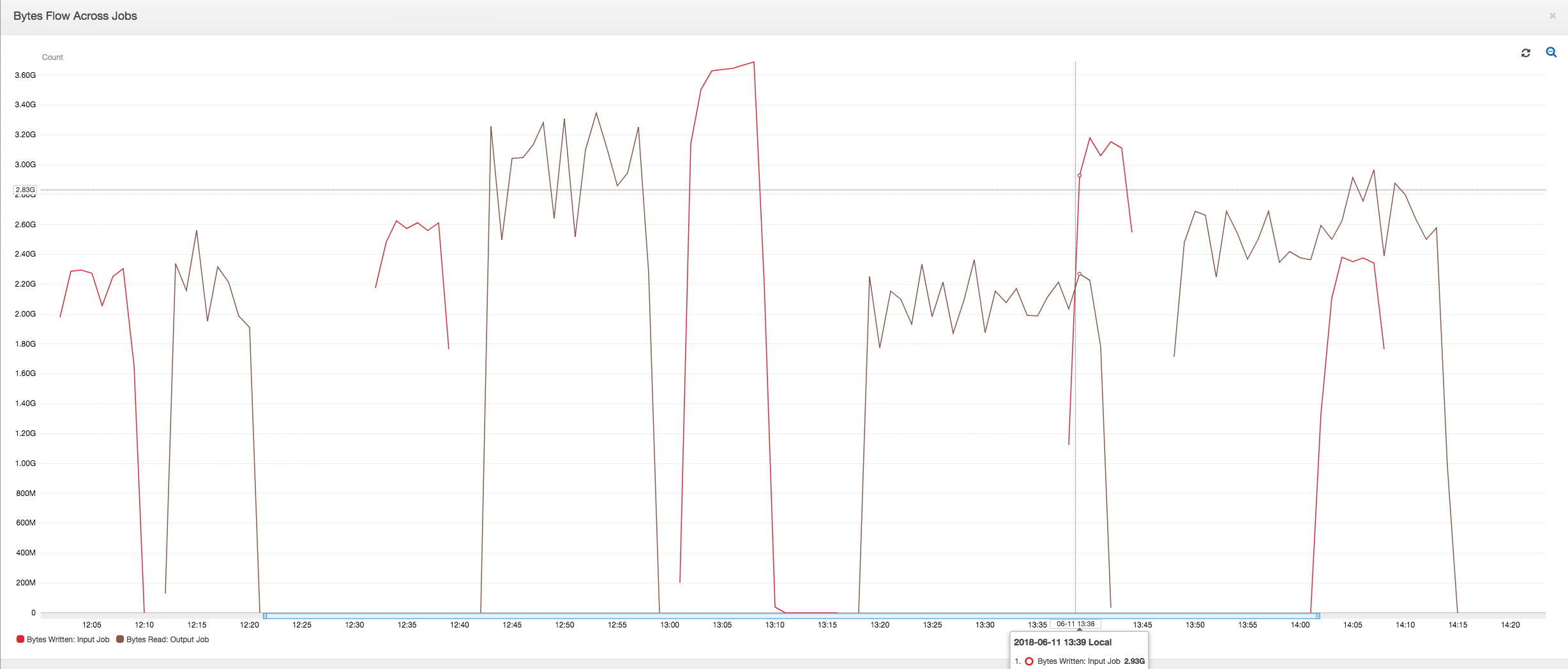
Le tableau de bord suivant superpose la métrique d'octets Amazon S3 écrits de la tâche d'entrée sur la métrique d'octets Amazon S3 lus selon la même chronologie pour la tâche de sortie. La chronologie montre différentes exécutions de tâche des tâches d'entrée et de sortie. La tâche d'entrée (en rouge) démarre toutes les 30 minutes. La tâche de sortie (en marron) démarre lorsque la tâche d'entrée se termine, avec une simultanéité max. de 1.
Dans cet exemple, les signets de tâche ne sont pas activés. Aucun contexte de transformation n'est utilisé pour activer les signets de tâche dans le code de script.
Historique de tâche : les tâches d'entrée et de sortie s'exécutent plusieurs fois, à partir de 12 h 00, comme le montre l'onglet Historique.
La tâche d'entrée sur AWS Glue la console ressemble à ceci :

L'image suivante montre la tâche de sortie :

Première exécution de tâche : comme le montre le graphique Octets de données lues et écrites ci-dessous, les premières exécutions des tâches d'entrée et de sortie entre 12 h 00 et 12 h 30 montrent à peu près la même zone sous les courbes. Ces zones représentent les octets Amazon S3 écrits par la tâche d'entrée et les octets Amazon S3 lus par la tâche de sortie. Ces données sont également confirmées par le taux d'octets Amazon S3 écrits (additionnés sur 30 minutes, la fréquence du déclencheur de tâche pour la tâche d'entrée). Le point de données pour le ratio d'exécution de la tâche d'entrée qui a commencé à 12 h 00 est également 1.
Le graphique suivant montre le taux de flux de données pour toutes les exécutions de tâches :
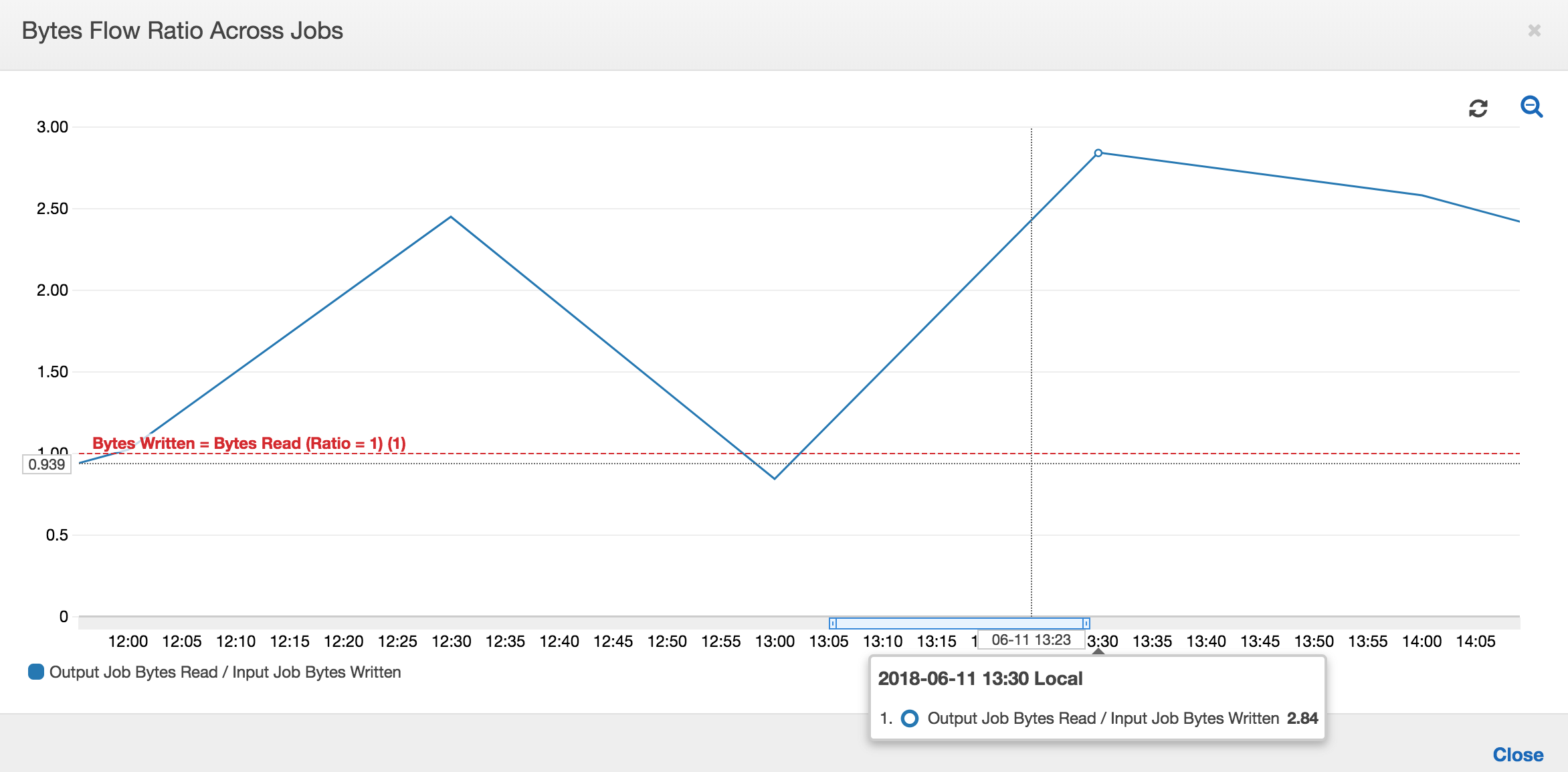
Deuxième exécution de tâche : dans la deuxième exécution de tâche, il existe une différence claire entre le nombre d'octets lus par la tâche de sortie et le nombre d'octets écrits par la tâche d'entrée. (Comparez la zone sous la courbe des deux exécutions de tâche de la tâche de sortie ou comparez les zones de la deuxième exécution des tâches d'entrée et de sortie.) Le ratio entre le nombre d'octets lus et écrits montre que la tâche de sortie lit environ 2,5x les données écrites par la tâche d'entrée dans la seconde période de 30 minutes, de 12 h 30 à 13 h 00. C'est parce que la tâche de sortie a retraité la sortie de la première exécution de la tâche d'entrée car les signets de tâche n'étaient pas activés. Un ratio supérieur à 1 indique qu'un backlog de données supplémentaire a été traité par la tâche de sortie.
Troisième exécution de tâche : la tâche d'entrée est assez cohérente quant au nombre d'octets écrits (voir la zone sous les courbes rouges). Toutefois, la troisième exécution de la tâche d'entrée a duré plus longtemps que prévu (voir la longue queue de la courbe rouge). Par conséquent, la troisième exécution de la tâche de sortie a démarré en retard. La troisième exécution de tâche n'a traité qu'une fraction des données cumulées à l'emplacement intermédiaire dans les 30 minutes restantes entre 13 h 00 et 13 h 30. Le taux de débit d'octets indique que seules 0,83 des données écrites ont été traitées par la troisième exécution de la tâche d'entrée (voir le ratio à 13 h 00).
Chevauchement des tâches d'entrée et de sortie : la quatrième exécution de la tâche d'entrée a démarré à 13 h 30 comme prévu, avant la fin de la troisième exécution de la tâche de sortie. Ces deux exécutions de tâche se chevauchement partiellement. Toutefois, la troisième exécution de la tâche de sortie ne capture que les fichiers répertoriés dans l'emplacement intermédiaire d'Amazon S3, lorsqu'elle a commencé vers 13:17. Cela comprend toutes les sorties de données de la première exécution de la tâche d'entrée. Le ratio réel à 13 h 30 est d'environ 2,75. La troisième exécution de la tâche de sortie a traité environ 2,75x de données écrites par la quatrième exécution de la tâche d'entrée, de 13 h 30 à 14 h 00.
Comme le montrent ces images, la tâche de sortie retraite des données de toutes les précédentes exécutions de la tâche d'entrée à partir de l'emplacement intermédiaire. Par conséquent, la quatrième exécution de la tâche de sortie est la plus longue et elle chevauche la totalité de la cinquième exécution de la tâche d'entrée.
Corriger le traitement des fichiers
Vous devez vous assurer que la tâche de sortie ne traite les fichiers qui n'ont pas été traités par de précédentes exécutions de la tâche de sortie. Pour ce faire, activez les signets de tâche et configurez le contexte de transformation dans la tâche de sortie de la façon suivante :
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json", transformation_ctx = "bookmark_ctx")
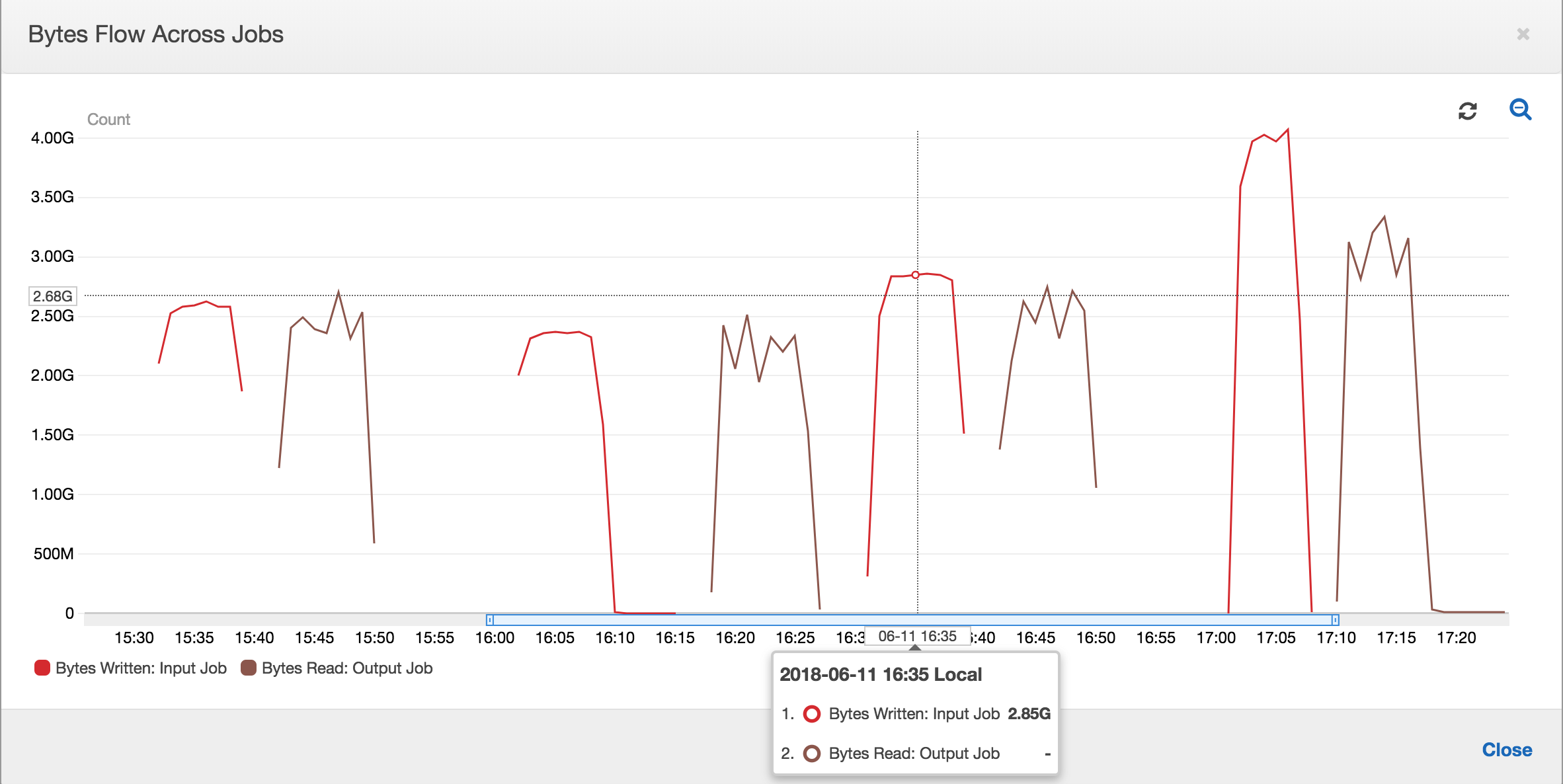
Lorsque les signets de tâche sont activés, la tâche de sortie ne retraite pas les données dans l'emplacement intermédiaire pour toutes les précédentes exécutions de la tâche d'entrée. Dans l'image suivante montrant les données lues et écrites, la zone sous la courbe marron est assez cohérente et similaire aux courbes rouges.
Le rapports du flux d'octets reste également proche de 1, car des données supplémentaires ne sont pas traitées.
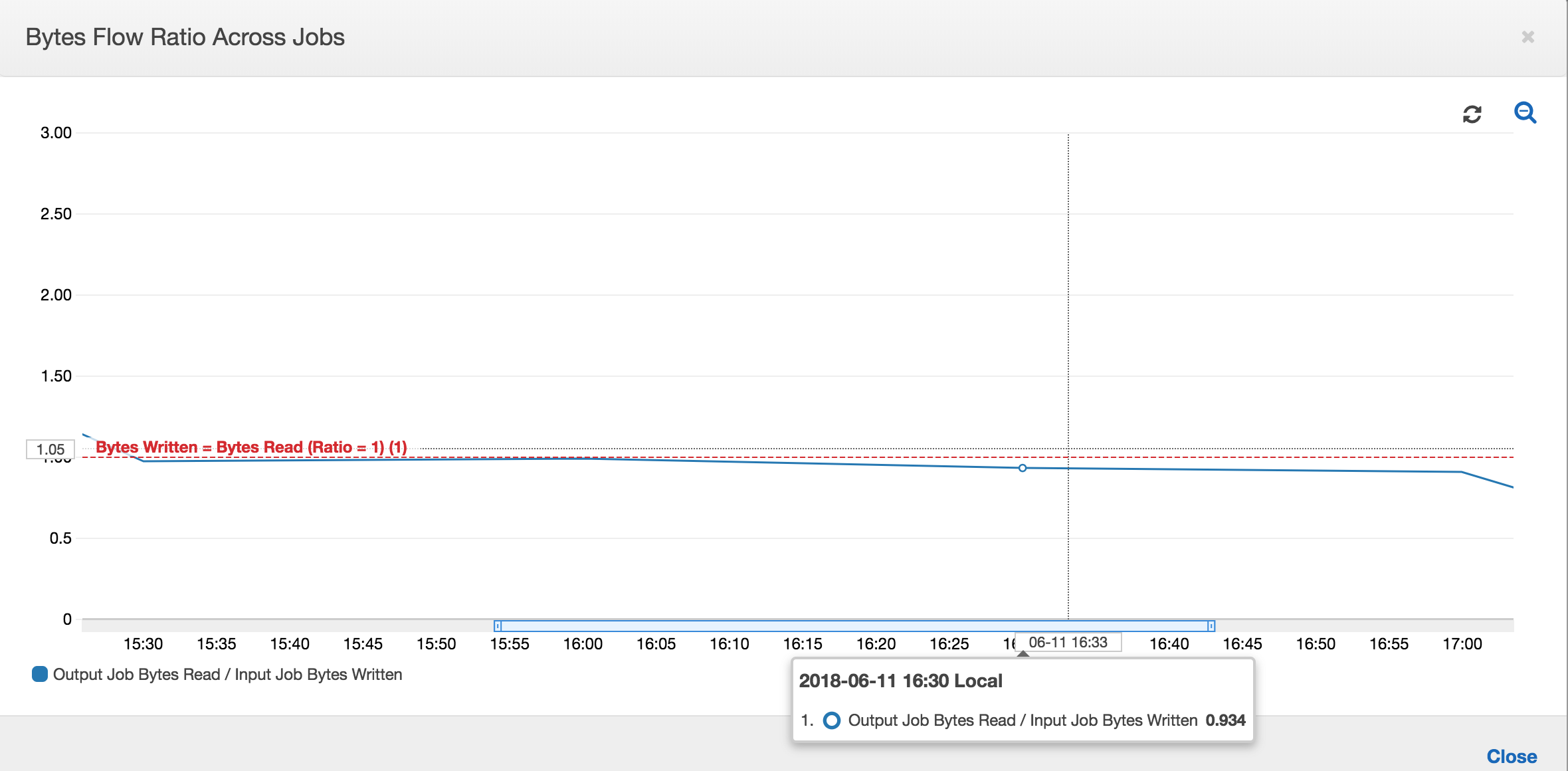
Une exécution de la tâche de sortie démarre et capture les fichiers dans l'emplacement intermédiaire avant que la prochaine exécution de la tâche d'entrée ne commence à placer d'autres données dans l'emplacement intermédiaire. Tant que c'est le cas, elle ne traite que les fichiers capturés lors de la précédente exécution de tâche de sortie, et le ratio reste proche de 1.
Supposons que la tâche d'entrée dure plus longtemps que prévu et que, par conséquent, la tâche de sortie capture des fichiers dans l'emplacement intermédiaire à partir de deux exécutions de tâche d'entrée. Le ratio est supérieur à 1 pour cette exécution de tâche de sortie. Toutefois, les exécutions de tâches de sortie suivantes ne traitent aucun fichier déjà traité par les précédentes exécutions de la tâche de sortie.
