Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillance avec AWS Glue Métriques d'observabilité
Note
AWS Glue Les métriques d'observabilité sont disponibles sur AWS Glue Versions 4.0 et ultérieures.
Utiliser AWS Glue Des indicateurs d'observabilité pour obtenir des informations sur ce qui se passe au sein de votre AWS Glue pour les tâches Apache Spark afin d'améliorer le triage et l'analyse des problèmes. Les métriques d'observabilité sont visualisées via des tableaux de bord Amazon CloudWatch et peuvent être utilisées pour analyser les causes racines des erreurs et pour diagnostiquer les goulots d'étranglement en matière de performance. Vous pouvez réduire le temps passé à déboguer les problèmes à l'échelle afin de vous concentrer sur leur résolution plus rapide et plus efficace.
AWS Glue L'observabilité fournit des Amazon CloudWatch métriques classées dans les quatre groupes suivants :
-
Fiabilité (par exemple, classes d'erreurs) : identifier facilement les motifs d'échec les plus courants sur une plage de temps donnée que vous souhaiterez remédier.
-
Performance (par exemple, asymétrie) : identifier un goulot d'étranglement en matière de performance et appliquer des techniques de réglage. Par exemple, lorsque vos performances sont dégradées en raison de l'asymétrie des tâches, vous pouvez activer l'Exécution adaptative des requêtes Spark et affiner le seuil de jointure asymétrique.
-
Débit (c'est-à-dire le débit par source/récepteur) : surveiller les tendances en matière de lecture et d'écriture de données. Vous pouvez également configurer des Amazon CloudWatch alarmes en cas d'anomalie.
-
Utilisation des ressources (c'est-à-dire utilisation du personnel, de la mémoire et du disque) : trouver de manière efficace les tâches dont l'utilisation des capacités est faible. Vous souhaiterez peut-être activer AWS Glue auto-scaling pour ces tâches.
Démarrage avec AWS Glue Métriques d'observabilité
Note
Les nouvelles métriques sont activées par défaut dans AWS Glue Studio console.
Pour configurer les métriques d'observabilité dans AWS Glue Studio:
-
Connectez-vous au AWS Glue console et choisissez les tâches ETL dans le menu de la console.
-
Choisissez une tâche en cliquant sur le nom de la tâche dans la section Vos tâches.
-
Sélectionnez l'onglet Job details (Détails de la tâche).
-
Faites défiler l'écran vers le bas et choisissez Propriétés avancées, puis Metriques d'observabilité de la tâche.
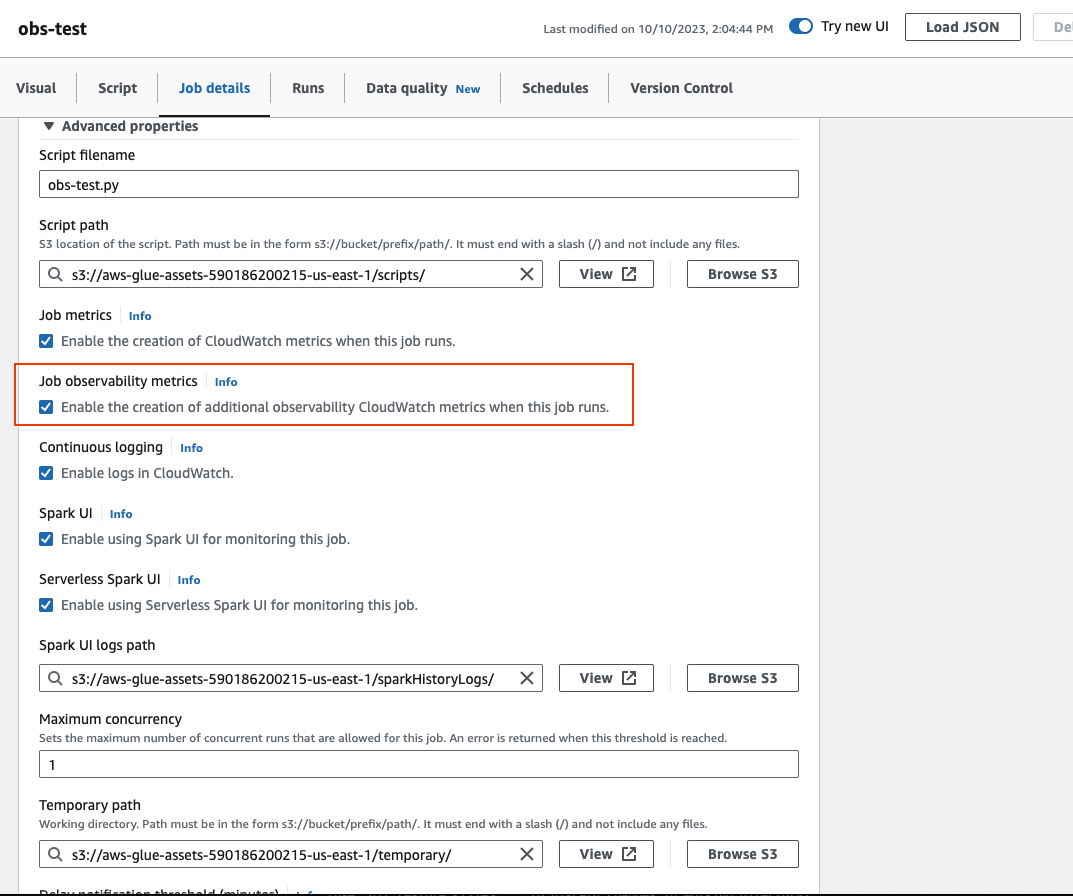
Pour activer AWS Glue Mesures d'observabilité utilisant AWS CLI :
-
Ajoutez à la carte
--default-argumentsla valeur clé suivante dans le fichier JSON d'entrée :--enable-observability-metrics, true
Utilisation AWS Glue observabilité
Parce que le AWS Glue les métriques d'observabilité sont fournies via la Amazon CloudWatch console Amazon CloudWatch AWS CLI, le SDK ou l'API pour interroger les points de données des métriques d'observabilité. Voir Using Glue Observability pour surveiller l'utilisation des ressources afin de réduire les coûts
Utilisation AWS Glue observabilité dans la console Amazon CloudWatch
Pour interroger et visualiser les métriques dans la Amazon CloudWatch console, procédez comme suit :
-
Ouvrez la Amazon CloudWatch console et choisissez Toutes les mesures.
-
Sous espaces de noms personnalisés, choisissez AWS Glue.
-
Choisissez les métriques d'observabilité de la tâche, les métriques d'observabilité par source ou les métriques d'observabilité par récepteur.
-
Recherchez le nom de la métrique, le nom de la tâche, l'ID d'exécution de la tâche spécifiques, puis sélectionnez-les.
-
Sous l'onglet Métriques sous forme de graphique, configurez vos statistiques, périodes et autres options préférées.
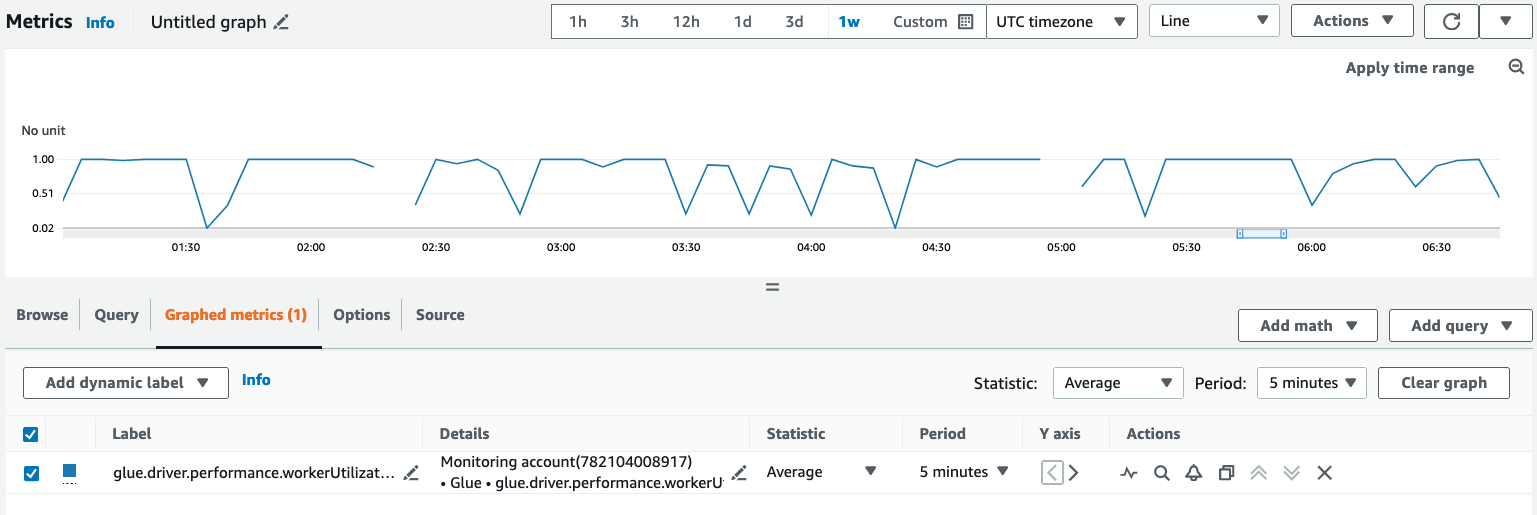
Pour interroger une métrique d'observabilité à l'aide AWS CLI de :
-
Créez un fichier JSON de définition de métrique et remplacez
your-Glue-job-nameetyour-Glue-job-run-idpar les vôtres.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
Exécutez la commande
get-metric-data:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
Métriques d'observabilité
AWS Glue L'observabilité établit des profils et envoie les mesures suivantes Amazon CloudWatch toutes les 30 secondes. Certaines de ces mesures peuvent être visibles dans le AWS Glue Studio Page de surveillance des exécutions de tâches.
| Métrique | Description | Catégorie |
|---|---|---|
| glue.driver.skewness.stage |
Catégorie de métrique : job_performance Asymétrie de l’exécution des étapes Spark : cette métrique capture l’asymétrie d’exécution, qui peut être causée par une asymétrie des données d’entrée ou par une transformation (par exemple, une jointure asymétrique). Les valeurs de cette métrique se situent dans l’intervalle [0, infini], où 0 signifie que le rapport entre le temps d’exécution maximum et médian des tâches, parmi toutes les tâches de l’étape, est inférieur à un certain facteur d’asymétrie d’étape. Le facteur d’asymétrie d’étape par défaut est « 5 » et il peut être modifié via la configuration Spark : spark.metrics.conf.driver.source.glue.jobPerformance.skewnessFactor Une valeur d’asymétrie d’étape de 1 signifie que le rapport est le double du facteur d’asymétrie d’étape. La valeur de l'asymétrie de la scène est mise à jour toutes les 30 secondes pour refléter l'asymétrie actuelle. La valeur à la fin de l'étape reflète l'asymétrie de l'étape finale. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (job_performance) Statistiques valides : moyenne, maximum, minimum, centile Unité : nombre |
job_performance |
| glue.driver.skewness.job |
Catégorie de métrique : job_performance L’asymétrie de la tâche est la moyenne pondérée de l’asymétrie des étapes de la tâche. La moyenne pondérée donne plus de poids aux étapes dont l’exécution prend plus de temps. Cela permet d’éviter le cas particulier où une étape très asymétrique s’exécute en réalité pendant un temps très court par rapport aux autres étapes (et donc son asymétrie n’est pas significative pour la performance globale de la tâche et ne mérite pas l’effort de tenter de corriger son asymétrie). Cette métrique est mise à jour à la fin de chaque étape. La dernière valeur reflète donc l’asymétrie globale réelle de la tâche. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (job_performance) Statistiques valides : moyenne, maximum, minimum, centile Unité : nombre |
job_performance |
| glue.succeed.ALL |
Catégorie de métrique : erreur Nombre total d’exécutions de tâches réussies, pour compléter le tableau des catégories d’échec Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun identifiant ou ALL), le type (nombre) et ObservabilityGroup (erreur) Statistiques valides : SUM Unité : nombre |
error |
| glue.error.ALL |
Catégorie de métrique : erreur Nombre total d’erreurs d’exécution de tâche, pour compléter le tableau des catégories d’échec Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun identifiant ou ALL), le type (nombre) et ObservabilityGroup (erreur) Statistiques valides : SUM Unité : nombre |
error |
| glue.error.[error category] |
Catégorie de métrique : erreur Il s’agit en fait d’un ensemble de métriques, qui sont mises à jour uniquement lorsqu’une exécution de tâche échoue. La catégorisation des erreurs facilite le triage et le débogage. Lorsqu’une exécution de tâche échoue, l’erreur à l’origine de l’échec est catégorisée et la métrique de la catégorie d’erreur correspondante est définie à 1. Cela permet d'effectuer une analyse des défaillances au fil du temps, ainsi qu'une analyse des erreurs sur l'ensemble des tâches afin d'identifier les catégories de défaillances les plus courantes et de commencer à y remédier. AWS Glue comporte 28 catégories d'erreurs, dont les catégories OUT_OF_MEMORY (pilote et exécuteur), PERMISSION, SYNTAX et THROTTLING. Les catégories d’erreur incluent également les catégories d’erreur COMPILATION, LAUNCH et TIMEOUT. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun identifiant ou ALL), le type (nombre) et ObservabilityGroup (erreur) Statistiques valides : SUM Unité : nombre |
error |
| glue.driver.workerUtilization |
Catégorie de métrique : resource_utilization Le pourcentage des travailleurs affectés qui sont réellement utilisés. Si ce n’est pas bon, l’autoscaling peut vous aider. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne, maximum, minimum, centile Unité : pourcentage |
resource_utilization |
| glue.driver.memory.heap.[available | used] |
Catégorie de métrique : resource_utilization Tas disponible/utilisé par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation de la mémoire, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à la mémoire. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : octets |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
Catégorie de métrique : resource_utilization Tas utilisé (%) par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation de la mémoire, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à la mémoire. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.driver.memory.non-heap.[available | used] |
Catégorie de métrique : resource_utilization Mémoire hors tas disponible/utilisée par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation de la mémoire, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à la mémoire. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : octets |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
Catégorie de métrique : resource_utilization Mémoire hors tas utilisée (%) par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation de la mémoire, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à la mémoire. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.driver.memory.total.[available | used] |
Catégorie de métrique : resource_utilization Mémoire totale disponible/utilisée par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation de la mémoire, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à la mémoire. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : octets |
resource_utilization |
| glue.driver.memory.total.used.percentage |
Catégorie de métrique : resource_utilization Mémoire totale utilisée (%) par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation de la mémoire, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à la mémoire. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.ALL.memory.heap.[available | used] |
Catégorie de métrique : resource_utilization Tas disponible/utilisé par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : octets |
resource_utilization |
| glue.ALL.memory.heap.used.percentage |
Catégorie de métrique : resource_utilization Tas utilisé (%) par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.ALL.memory.non-heap.[available | used] |
Catégorie de métrique : resource_utilization Mémoire hors tas disponible/utilisée par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : octets |
resource_utilization |
| glue.ALL.memory.non-heap.used.percentage |
Catégorie de métrique : resource_utilization Mémoire hors tas /utilisée (%) par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.ALL.memory.total.[available | used] |
Catégorie de métrique : resource_utilization Mémoire totale disponible/utilisée par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : octets |
resource_utilization |
| glue.ALL.memory.total.used.percentage |
Catégorie de métrique : resource_utilization Mémoire totale utilisée (%) par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.driver.disk.[available_GB | used_GB] |
Catégorie de métrique : resource_utilization Espace disque disponible/utilisé par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation du disque, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à un espace disque insuffisant. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : gigaoctets |
resource_utilization |
| glue.driver.disk.used.percentage] |
Catégorie de métrique : resource_utilization Espace disque disponible/utilisé par le pilote pendant l’exécution de la tâche. Cela aide à comprendre les tendances d’utilisation du disque, particulièrement au fil du temps, ce qui peut contribuer à éviter des échecs potentiels, en plus de déboguer les échecs liés à un espace disque insuffisant. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.ALL.disk.[available_GB | used_GB] |
Catégorie de métrique : resource_utilization Espace disque disponible/utilisé par les exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : gigaoctets |
resource_utilization |
| glue.ALL.disk.used.percentage |
Catégorie de métrique : resource_utilization Espace disque available/used/used (%) des exécuteurs. ALL signifie tous les exécuteurs. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge) et ObservabilityGroup (resource_utilization) Statistiques valides : moyenne Unité : pourcentage |
resource_utilization |
| glue.driver.bytesRead |
Catégorie de métrique : débit Nombre d’octets lus par source d’entrée lors de cette exécution de tâche, ainsi que pour TOUTES les sources. Cela aide à comprendre le volume de données et ses variations au fil du temps, ce qui est utile pour résoudre des problèmes tels que l’asymétrie des données. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun identifiant ou ALL), le type (jauge), ObservabilityGroup (resource_utilization) et la source (emplacement des données source) Statistiques valides : moyenne Unité : octets |
débit |
| glue.driver.[recordsRead | filesRead] |
Catégorie de métrique : débit Nombre d’enregistrements/fichiers lus par source d’entrée lors de cette exécution de tâche, ainsi que pour TOUTES les sources. Cela aide à comprendre le volume de données et ses variations au fil du temps, ce qui est utile pour résoudre des problèmes tels que l’asymétrie des données. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun identifiant ou ALL), le type (jauge), ObservabilityGroup (resource_utilization) et la source (emplacement des données source) Statistiques valides : moyenne Unité : nombre |
débit |
| glue.driver.partitionsRead |
Catégorie de métrique : débit Nombre de partitions lues par source d’entrée Amazon S3 dans cette exécution de tâche, ainsi que pour TOUTES les sources. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun identifiant ou ALL), le type (jauge), ObservabilityGroup (resource_utilization) et la source (emplacement des données source) Statistiques valides : moyenne Unité : nombre |
débit |
| glue.driver.bytesWrittten |
Catégorie de métrique : débit Nombre d’octets écrits par récepteur de sortie dans cette exécution de tâche, ainsi que pour TOUS les récepteurs. Cela aide à comprendre le volume de données et son évolution au fil du temps, ce qui est utile pour résoudre des problèmes tels que l’asymétrie de traitement. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) et Sink (emplacement des données du puits) Statistiques valides : moyenne Unité : octets |
débit |
| glue.driver.[recordsWritten | filesWritten] |
Catégorie de métrique : débit Nombre d’enregistrements/fichiers écrits par récepteur de sortie dans cette exécution de tâche, ainsi que pour TOUS les récepteurs. Cela aide à comprendre le volume de données et son évolution au fil du temps, ce qui est utile pour résoudre des problèmes tels que l’asymétrie de traitement. Dimensions valides : JobName (nom du AWS Glue Job), JobRunId (l' JobRun ID ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) et Sink (emplacement des données du puits) Statistiques valides : moyenne Unité : nombre |
débit |
Catégories d’erreur
| Catégories d’erreur | Description |
|---|---|
| COMPILATION_ERROR | Des erreurs surviennent lors de la compilation du code Scala. |
| CONNECTION_ERROR | Des erreurs surviennent lors de la connexion à un service/remote host/database service, etc. |
| DISK_NO_SPACE_ERROR |
Des erreurs surviennent lorsqu’il n’y a plus d’espace disponible sur le disque du pilote/de l’exécuteur. |
| OUT_OF_MEMORY_ERROR | Des erreurs surviennent lorsqu’il n’y a plus d’espace disponible dans la mémoire du pilote/de l’exécuteur. |
| IMPORT_ERROR | Des erreurs surviennent lors de l’importation de dépendances. |
| INVALID_ARGUMENT_ERROR | Des erreurs surviennent lorsque les arguments d'entrée sont invalides/illégaux. |
| PERMISSION_ERROR | Les erreurs surviennent en cas d’absence d’autorisation d’accès au service, aux données, etc. |
| RESOURCE_NOT_FOUND_ERROR |
Des erreurs surviennent lorsque les données, l’emplacement, etc. ne sont pas disponibles. |
| QUERY_ERROR | Des erreurs surviennent lors de l’exécution de requêtes SQL dans Spark. |
| SYNTAX_ERROR | Des erreurs surviennent lorsqu’il y a une erreur de syntaxe dans le script. |
| THROTTLING_ERROR | Des erreurs surviennent lorsqu’une limite de simultanéité de service est atteinte ou qu’une limitation de quota de service est dépassée. |
| DATA_LAKE_FRAMEWORK_ERROR | Les erreurs proviennent de AWS Glue framework de lac de données supporté en mode natif comme Hudi, Iceberg, etc. |
| UNSUPPORTED_OPERATION_ERROR | Des erreurs surviennent lors d’une opération non prise en charge. |
| RESOURCES_ALREADY_EXISTS_ERROR | Des erreurs surviennent lorsqu’une ressource à créer ou à ajouter existe déjà. |
| GLUE_INTERNAL_SERVICE_ERROR | Des erreurs surviennent lorsqu'il existe un AWS Glue problème de service interne. |
| GLUE_OPERATION_TIMEOUT_ERROR | Des erreurs surviennent lorsqu'un AWS Glue l'opération est un délai d'expiration. |
| GLUE_VALIDATION_ERROR | Des erreurs surviennent lorsqu'une valeur requise n'a pas pu être validée pour AWS Glue travail. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | Des erreurs surviennent lorsqu’une même tâche s’exécute dans le même compartiment source et écrit simultanément vers la même destination ou une destination différente (simultanéité >1) |
| LAUNCH_ERROR | Des erreurs se produisent au cours de AWS Glue phase de lancement du projet. |
| DYNAMODB_ERROR | Les erreurs génériques proviennent du Amazon DynamoDB service. |
| GLUE_ERROR | Les erreurs génériques proviennent de AWS Glue service. |
| LAKEFORMATION_ERROR | Les erreurs génériques proviennent du AWS Lake Formation service. |
| REDSHIFT_ERROR | Les erreurs génériques proviennent du Amazon Redshift service. |
| S3_ERROR | Les erreurs génériques proviennent du service Amazon S3. |
| SYSTEM_EXIT_ERROR | Erreur de sortie du système générique. |
| TIMEOUT_ERROR | Des erreurs génériques surviennent lorsque la tâche échoue en raison du dépassement du délai d’exécution de l’opération. |
| UNCLASSIFIED_SPARK_ERROR | Les erreurs génériques proviennent de Spark. |
| UNCLASSIFIED_ERROR | Catégorie d’erreur par défaut. |
Limites
Note
glueContext doit être initialisé pour publier les métriques.
Dans la dimension source, la valeur est soit le chemin Amazon S3, soit le nom de la table, selon le type de source. En outre, si la source est JDBC et que l’option de requête est utilisée, la chaîne de requête est définie dans la dimension source. Si la valeur est supérieure à 500 caractères, elle est réduite à 500 caractères maximum. Les limites de la valeur sont les suivantes :
-
Les caractères non ASCII seront supprimés.
Si le nom de la source ne contient aucun caractère ASCII, il est converti en <non-ASCII input>.
Limites et considérations relatives aux métriques de débit
-
DataFrame et DataFrame basés DynamicFrame (par exemple JDBC, lecture depuis parquet sur Amazon S3) sont pris en charge, mais les fichiers basés sur RDD DynamicFrame (par exemple, lecture de csv, de json sur Amazon S3, etc.) ne sont pas pris en charge. Techniquement, toutes les lectures et écritures visibles sur l’interface utilisateur de Spark sont prises en charge.
-
La métrique
recordsReadsera émise si la source de données est une table de catalogue et que le format est JSON, CSV, texte ou Iceberg. -
Les métriques
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWrittenetglue.driver.throughput.filesWrittenne sont pas disponibles dans les tables JDBC et Iceberg. -
Les métriques peuvent être retardées. Si le travail se termine dans environ une minute, il se peut qu'il n'y ait aucune métrique de débit dans Amazon CloudWatch Metrics.
