Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Débogage des exceptions OOM et des anomalies de tâches
Vous pouvez déboguer les exceptions out-of-memory (OOM) et les anomalies de tâches dans AWS Glue. Les sections suivantes décrivent les scénarios de débogage des out-of-memory exceptions du pilote Apache Spark ou d'un exécuteur Spark.
Débogage d'un pilote d'exception OOM
Dans ce scénario, une tâche Spark lit un grand nombre de petits fichiers d'Amazon Simple Storage Service (Amazon S3). Il convertit les fichiers au format Apache Parquet, puis les écrit dans Amazon S3. Le pilote Spark manque de mémoire. Les données d'entrées Amazon S3 comptent plus d'un million de fichiers dans différentes partitions Amazon S3.
Le code profilé est le suivant :
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
Voir les métriques profilées sur la console AWS Glue
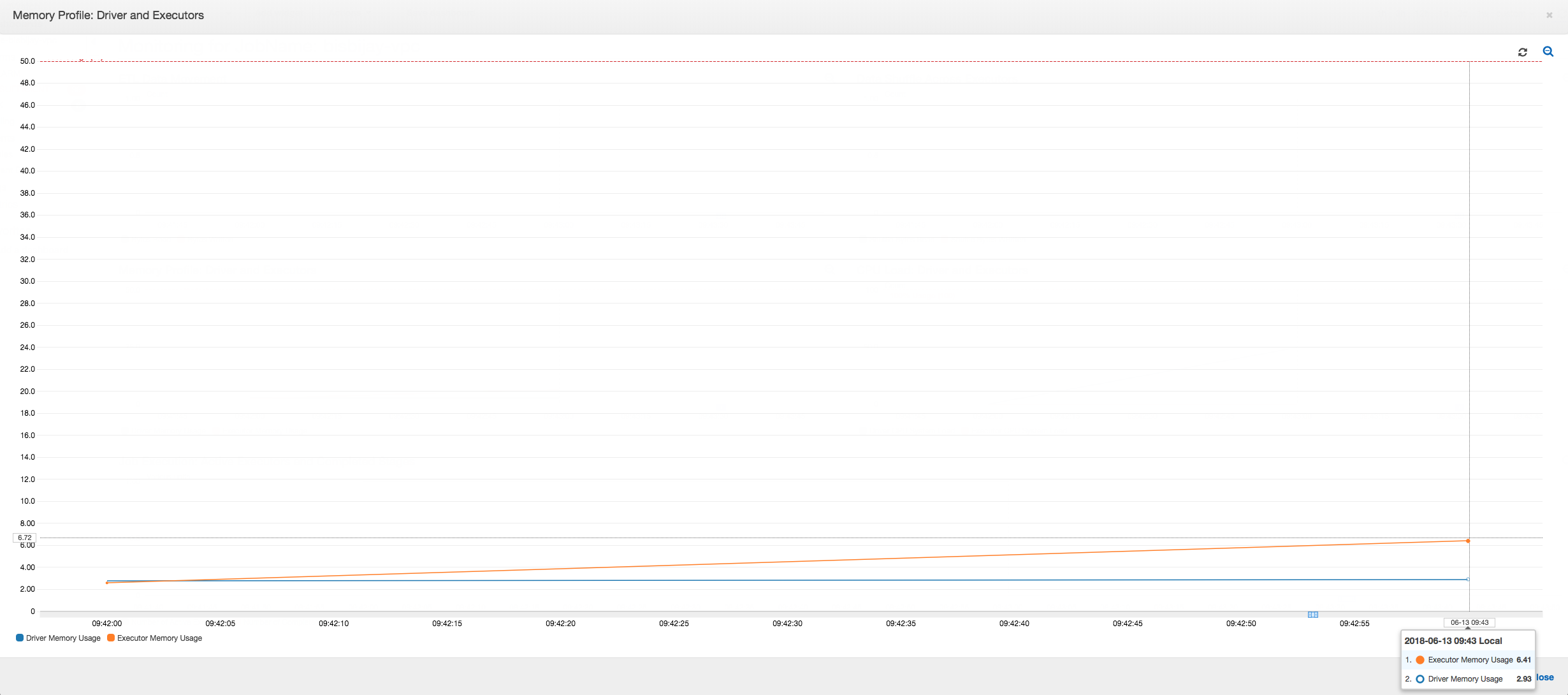
Le graphique suivant illustre l'utilisation de la mémoire sous forme de pourcentage pour le pilote et les programmes d'exécution. Cette utilisation est déterminée par un point de données qui est moyenné sur les valeurs rapportées au cours de la dernière minute. Vous pouvez voir dans le profil de la mémoire de la tâche que le pilote de la mémoire dépasse le seuil de sécurité de 50 % d'utilisation rapidement. D'autre part, l' utilisation moyenne de la mémoire sur l'ensemble des programmes d'exécution reste inférieure à 4 %. Ceci montre clairement l'anomalie de l'exécution du pilote dans cette tâche Spark.
L'exécution de la tâche échoue rapidement et l'erreur suivante apparaît dans l'onglet Historique du AWS Glue console : échec de la commande avec le code de sortie 1. Cette chaîne d'erreur signifie que la tâche a échoué en raison d'une erreur systémique ; dans le cas présent, le pilote manque de mémoire.

Sur la console, cliquez sur le lien Journaux d'erreurs dans l'onglet Historique pour confirmer les conclusions relatives au pilote OOM contenues dans les CloudWatch journaux. Recherchez « Error » dans les journaux d'erreurs de la tâche pour vérifier que c'est bien à cause d'une exception OOM que la tâche a échoué :
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
Dans l'onglet Historique de la tâche, choisissez Journaux. Vous pouvez trouver la trace suivante de l'exécution du pilote dans les CloudWatch journaux au début de la tâche. Le pilote Spark essaie de répertorier tous les fichiers dans tous les répertoires, il génère un InMemoryFileIndexet lance une tâche par fichier. Par conséquent, le pilote Spark doit conserver une grande quantité d'état en mémoire pour suivre toutes les tâches. Il met en cache une liste complète comprenant un grand nombre de fichiers pour l'index en mémoire, ce qui se traduit par un pilote OOM.
Corriger le traitement de fichiers multiples grâce au regroupement
Vous pouvez corriger le traitement de plusieurs fichiers en utilisant la fonction de regroupement dans AWS Glue. Le regroupement est automatiquement activé lorsque vous utilisez des cadres dynamiques et lorsque le jeu de données en entrée contient un grand nombre de fichiers (plus de 50 000). Le regroupement vous permet de fusionner plusieurs fichiers en un groupe, et il permet à une tâche de traiter l'ensemble du groupe plutôt qu'un seul fichier. Par conséquent, le pilote Spark stocke nettement moins d'état en mémoire pour suivre moins de tâches. Pour plus d'informations sur l'activation manuelle du regroupement pour votre ensemble de données, consultez Lecture des fichiers en entrée dans des groupes de plus grande taille.
Pour vérifier le profil de mémoire du AWS Glue job, profilez le code suivant avec le regroupement activé :
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Vous pouvez surveiller le profil de mémoire et le mouvement des données ETL dans AWS Glue profil de poste.
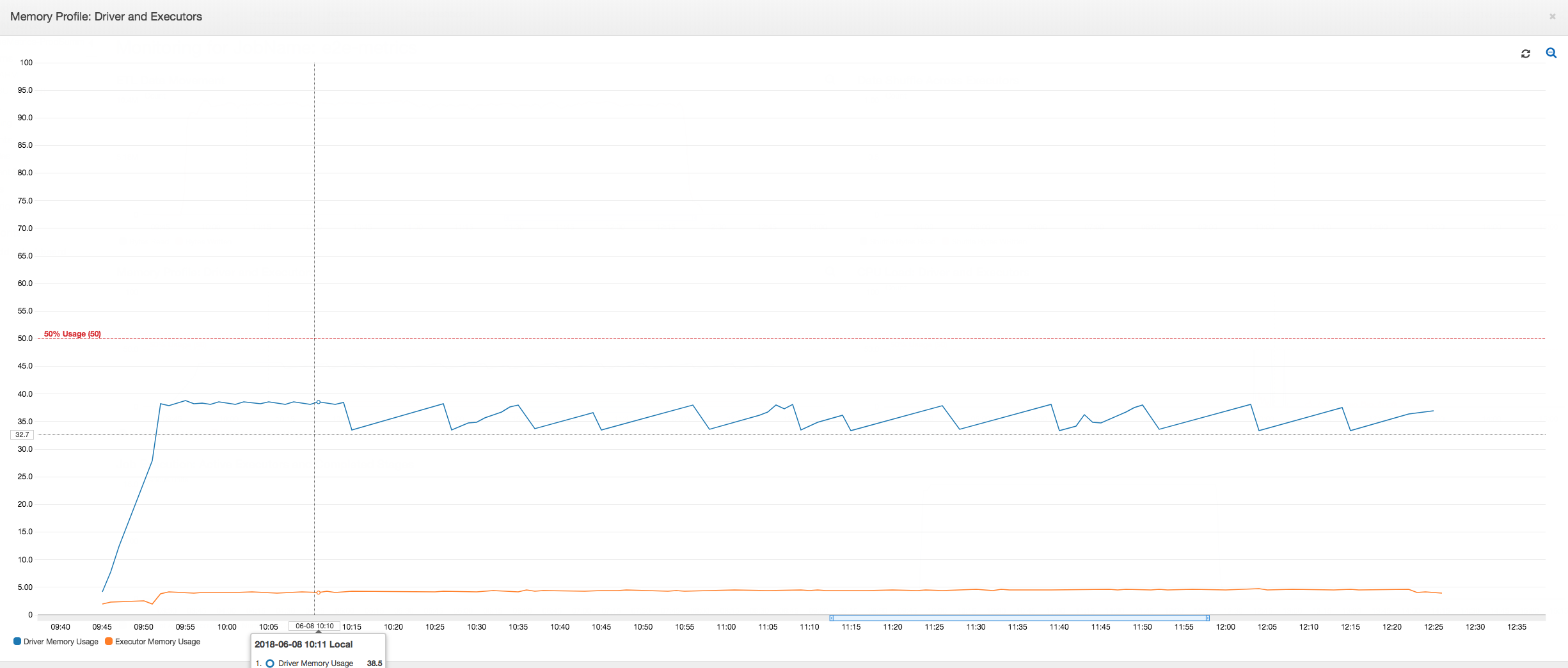
Le pilote fonctionne en dessous du seuil de 50 % d'utilisation de la mémoire pendant toute la durée du AWS Glue travail. Les programmes d'exécution diffusent des données depuis Amazon S3, les traitent et les écrivent dans Amazon S3. Par conséquent, ils consomment moins de 5 % de mémoire, quel que soit le moment.
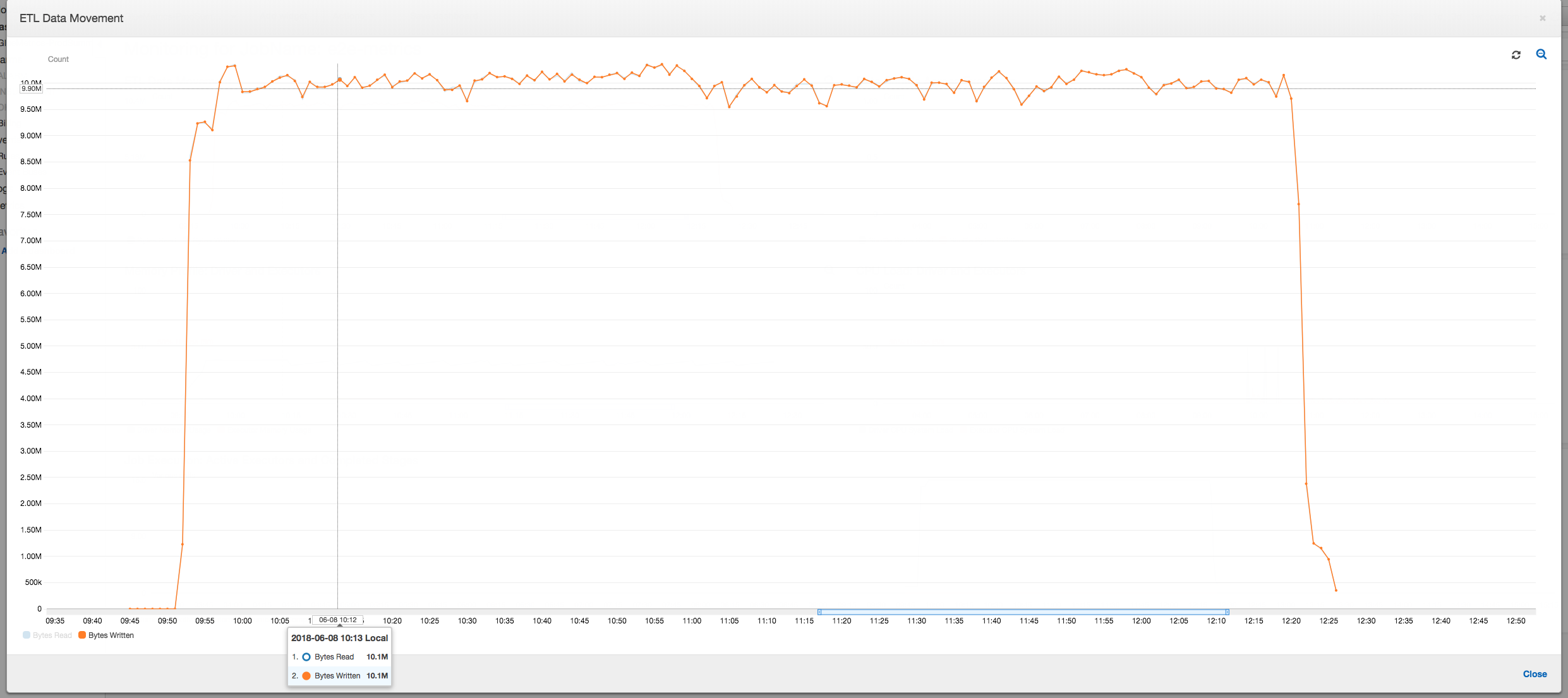
Le profil de déplacement des données ci-dessous montre le nombre total d'octets d'Amazon S3 lus et écrits au cours de la dernière minute par tous les programmes d'exécution à mesure que la tâche progresse. Les deux suivent un modèle similaire car les données sont diffusées sur tous les programmes d'exécution. La tâche finir de traiter le million de fichiers en moins de trois heures.
Débogage d'un programme d’exécution d'exception OOM
Dans ce scénario, vous pouvez apprendre à déboguer des exceptions OOM pouvant se produire dans les programmes d'exécution d'Apache Spark. Le code suivant utilise le lecteur MySQL Spark pour lire une grande table d'environ 34 millions de lignes dans une tramedonnées Spark. Il l'écrit ensuite sur Amazon S3 au format Parquet. Vous pouvez fournir les propriétés de connexion et utiliser les configurations Spark par défaut pour lire la table.
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
Visualisez les métriques profilées sur le AWS Glue console
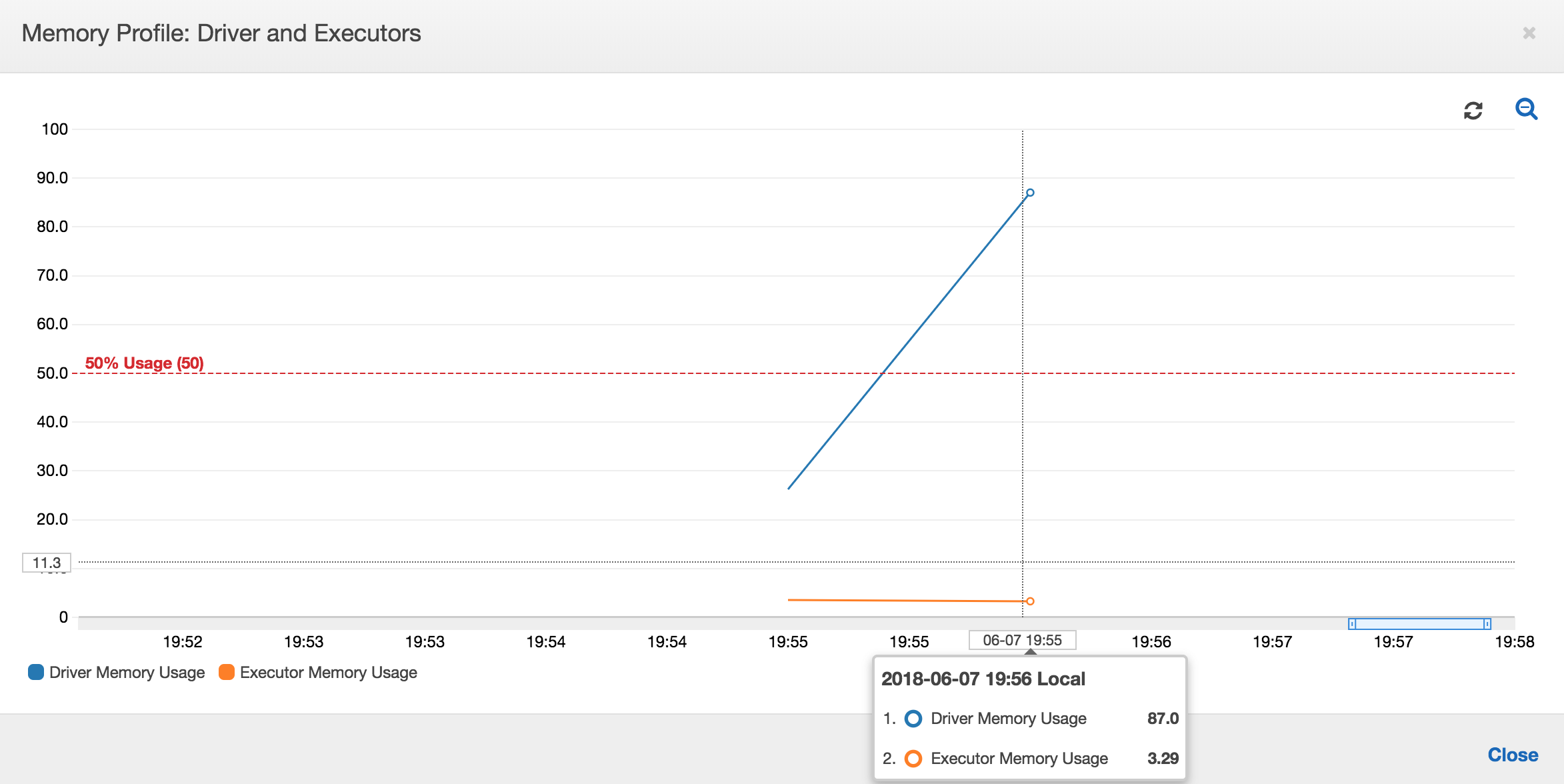
Si la pente du graphique d'utilisation de la mémoire est positive et dépasse 50 %, si la tâche échoue avant l'émission de la métrique suivante, l'épuisement de la mémoire peut en être à l’origine. Le graphique suivant montre qu'en une minute d'exécution, l'utilisation moyenne de la mémoire sur tous les programmes d'exécution dépasse rapidement 50 %. L'utilisation peut atteindre 92 % et le conteneur qui exécute le programme d'exécution est arrêté par Apache Hadoop YARN.
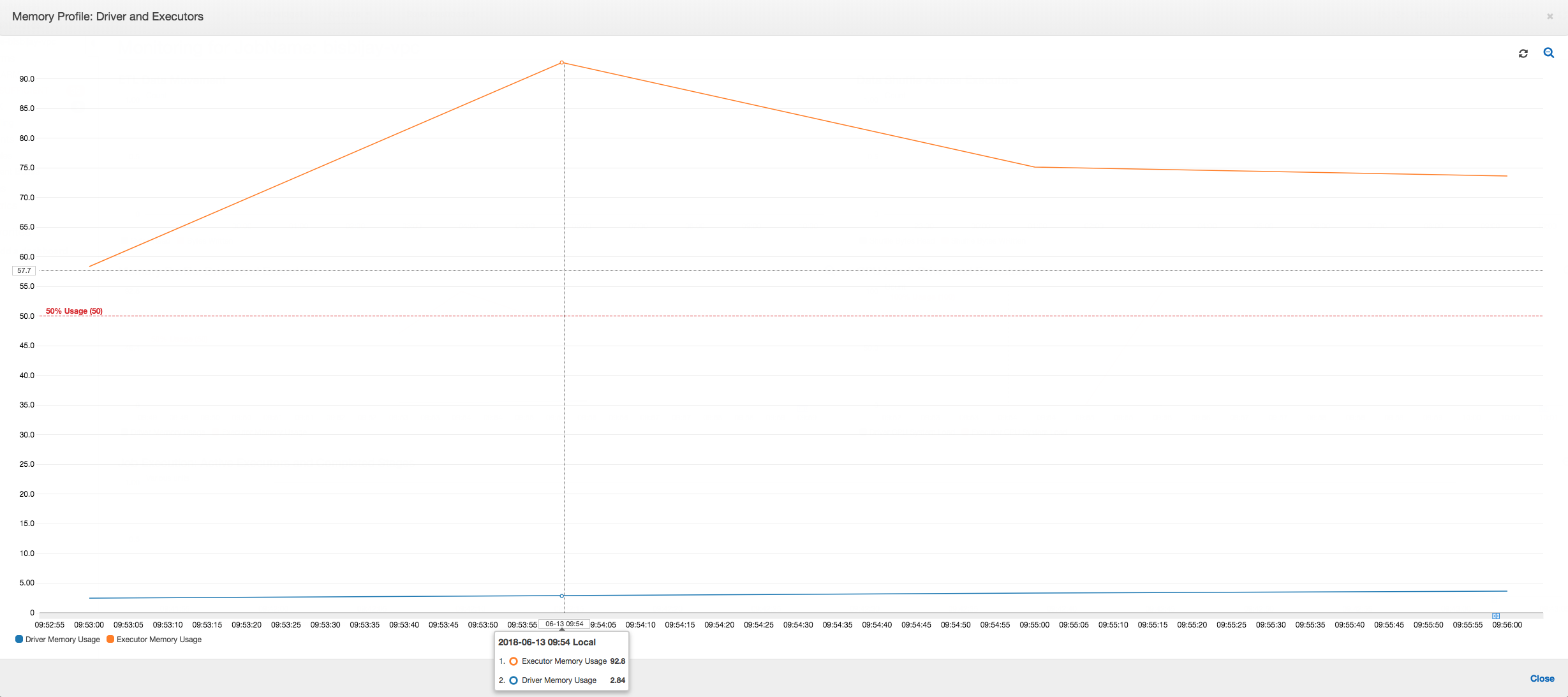
Comme le montre le graphique suivant, un programme d'exécution unique s'exécute toujours jusqu'à ce que la tâche échoue. En effet, un nouveau programme d'exécution est lancé pour remplacer celui qui a été arrêté. Les lectures de la source de données JDBC ne sont pas parallélisées par défaut, car cela nécessiterait le partitionnement de la table sur une colonne et d'ouvrir plusieurs connexions. Par conséquent, seul un programme d'exécution lit dans la table complète de manière séquentielle.
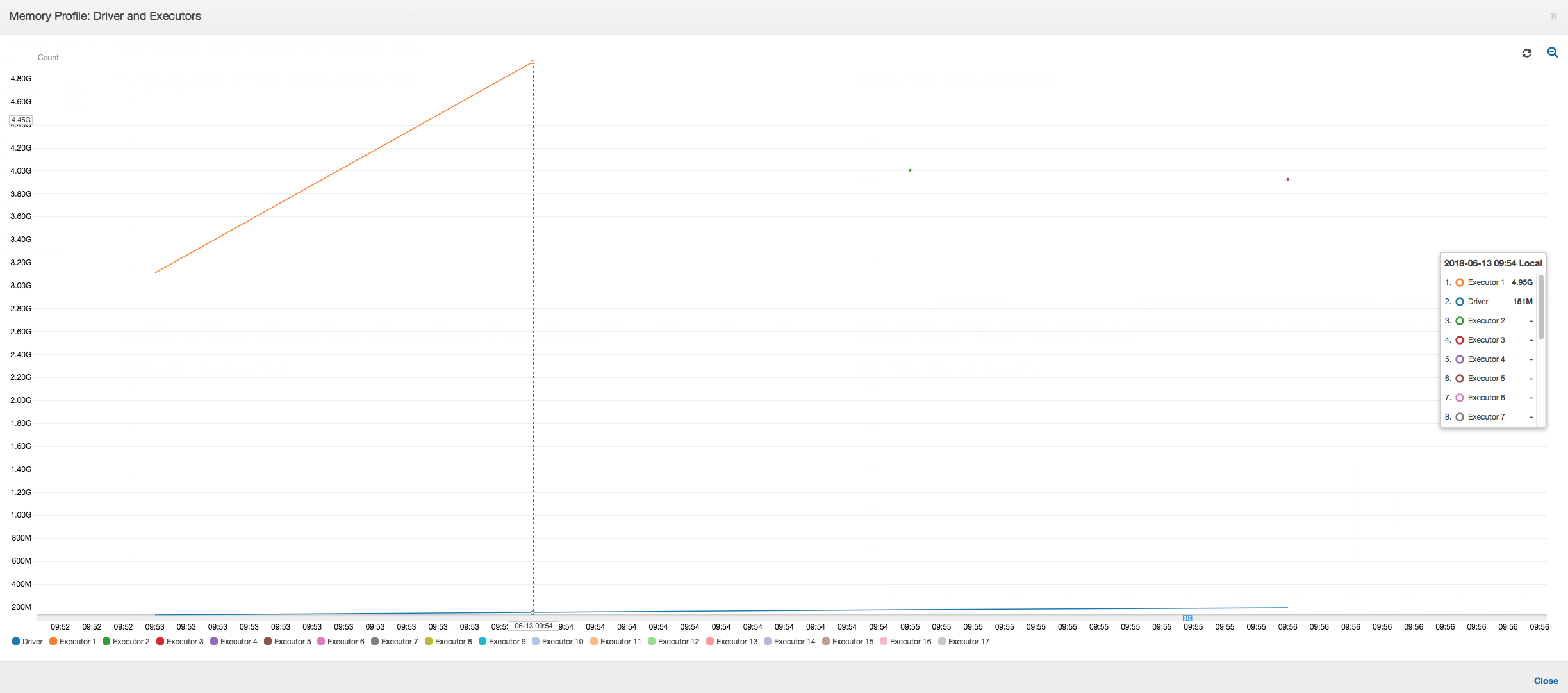
Comme le montre le graphique suivant, Spark tente de lancer une nouvelle tâche quatre fois avant l'échec de la tâche. Vous pouvez voir le profil de la mémoire de trois programmes d'exécution. Chaque programme d'exécution utilise rapidement toute sa mémoire. La quatrième programme d'exécution manque de mémoire et la tâche échoue. Par conséquent, sa métrique n'est pas immédiatement reportée.
Vous pouvez confirmer à l'aide de la chaîne d'erreur figurant sur le AWS Glue console sur laquelle la tâche a échoué en raison d'exceptions OOM, comme indiqué dans l'image suivante.

Journaux de sortie des tâches : pour confirmer la découverte d'une exception OOM de l'exécuteur, consultez les CloudWatch journaux. Lorsque vous recherchez Error, vous trouvez les quatre programme d'exécution arrêtés en à peu près le même temps que la fenêtre l'affiche sur le tableau de bord des métriques. Ils sont tous résiliés par YARN à mesure qu'ils excèdent les limites de mémoire.
Programme d'exécution 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Programme d'exécution 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Programme d'exécution 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Programme d'exécution 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Corrigez le paramètre de taille de récupération en utilisant AWS Glue cadres dynamiques
Le programme d'exécution est arrivé à court de mémoire lors de la lecture de la table JDBC, car la configuration par défaut de la taille d'extraction du JDBC de Spark est zéro. Cela signifie que le pilote JDBC sur le programme d'exécution Spark tente d'extraire les 34 millions de lignes de la base de données et de les mettre en cache, même si Spark diffuse les lignes une par une. Avec Spark, vous pouvez éviter ce scénario en définissant le paramètre de taille d'extraction par une valeur autre que zéro.
Vous pouvez également résoudre ce problème en utilisant AWS Glue cadres dynamiques à la place. Par défaut, les images dynamiques utilisent une taille d'extraction de 1 000 lignes, qui est généralement une valeur suffisante. Par conséquent, le programme d'exécution n'utilise pas plus de 7 % de la mémoire totale. Le AWS Glue la tâche se termine en moins de deux minutes avec un seul exécuteur. Lors de l'utilisation AWS Glue les cadres dynamiques sont l'approche recommandée, il est également possible de définir la taille de récupération à l'aide de la fetchsize propriété Apache Spark. Consultez le guide de Spark SQL DataFrames et des ensembles de données
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Métriques profilées normales : la mémoire de l'exécuteur avec AWS Glue les images dynamiques ne dépassent jamais le seuil de sécurité, comme le montre l'image suivante. Il diffuse dans les lignes depuis la base de données et met en cache 1 000 lignes seulement dans le pilote JDBC quel que soit le moment. Une exception de mémoire insuffisante ne se produit pas.