Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Débogage d'étapes exigeantes et de tâches de ralentissement
Vous pouvez utiliser … AWS Glue profilage des tâches pour identifier les étapes exigeantes et les tâches plus lentes dans vos tâches d'extraction, de transformation et de chargement (ETL). Une tâche retardée prend beaucoup plus de temps que les autres tâches d'une étape d'un AWS Glue travail. Par conséquent, l'étape s'effectue plus lentement, ce qui retarde aussi la durée d'exécution totale de la tâche.
Fusion de petits fichiers d'entrée pour obtenir de plus grands fichiers de sortie
Une tâche de ralentissement a lieu lorsque la distribution du travail au sein des différentes tâches n'est pas uniforme, ou qu'une asymétrie de données entraîne un plus important traitement de données par une tâche.
Vous pouvez profiler le code suivant un modèle commun dans Apache Spark pour fusionner un grand nombre de petits fichiers en de plus grands fichiers de sortie. Pour cet exemple, l'ensemble de données d'entrée est de 32 Go de fichiers compressés Gzip JSON. L'ensemble de données de sortie a environ 190 Go de fichiers JSON décompressés.
Le code profilé est le suivant :
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
Visualisez les métriques profilées sur AWS Glue console
Vous pouvez profiler votre tâche pour examiner quatre différents ensembles de métriques :
-
Déplacement de données ETL
-
Remaniement de données sur les programmes d'exécution
-
Exécution d’une tâche
-
Profil de mémoire
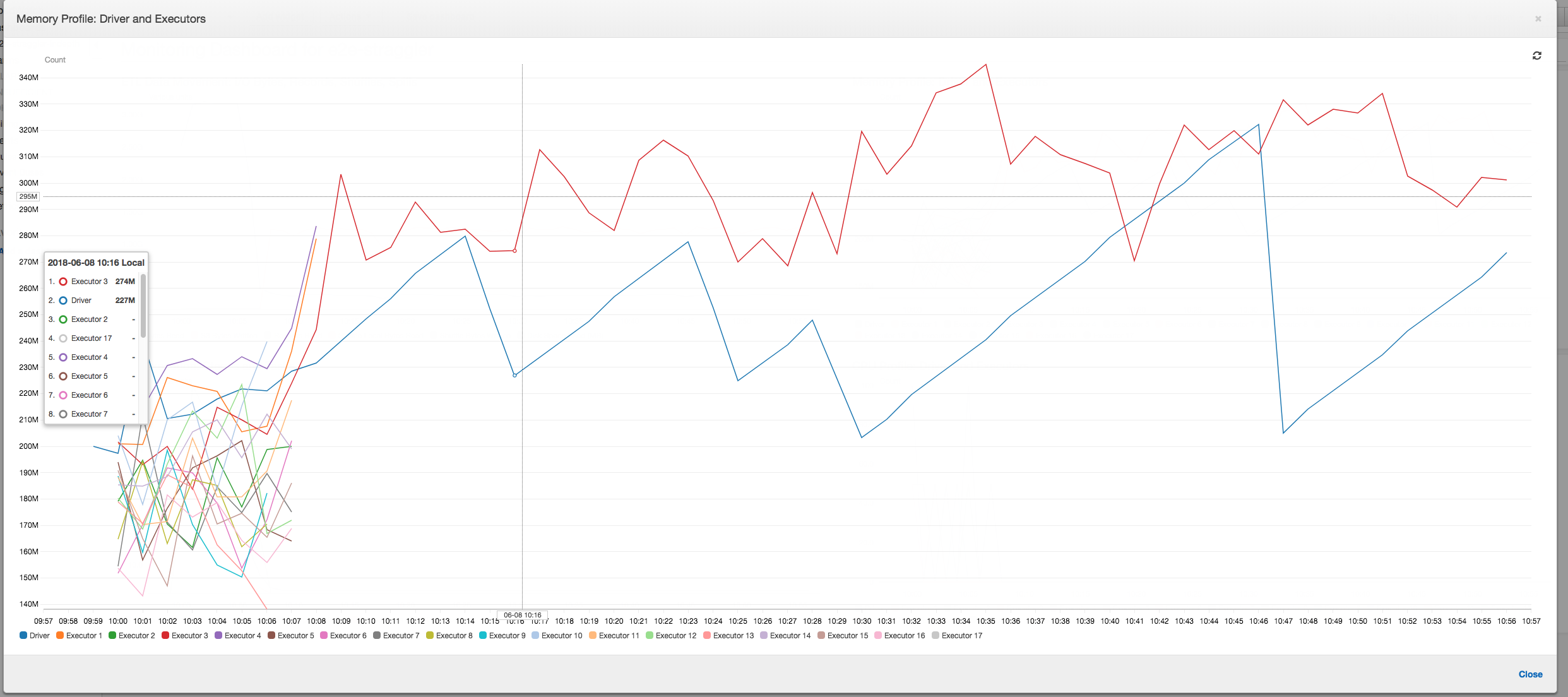
Déplacement des données ETL : Dans le profil du Déplacement des données ETL, les octets sont lus assez rapidement par tous les programmes d'exécution lors de la première étape qui se termine au cours des six premières minutes. Toutefois, la durée totale d'exécution de la tâche est d'environ une heure, et elle est principalement constituée des écritures de données.

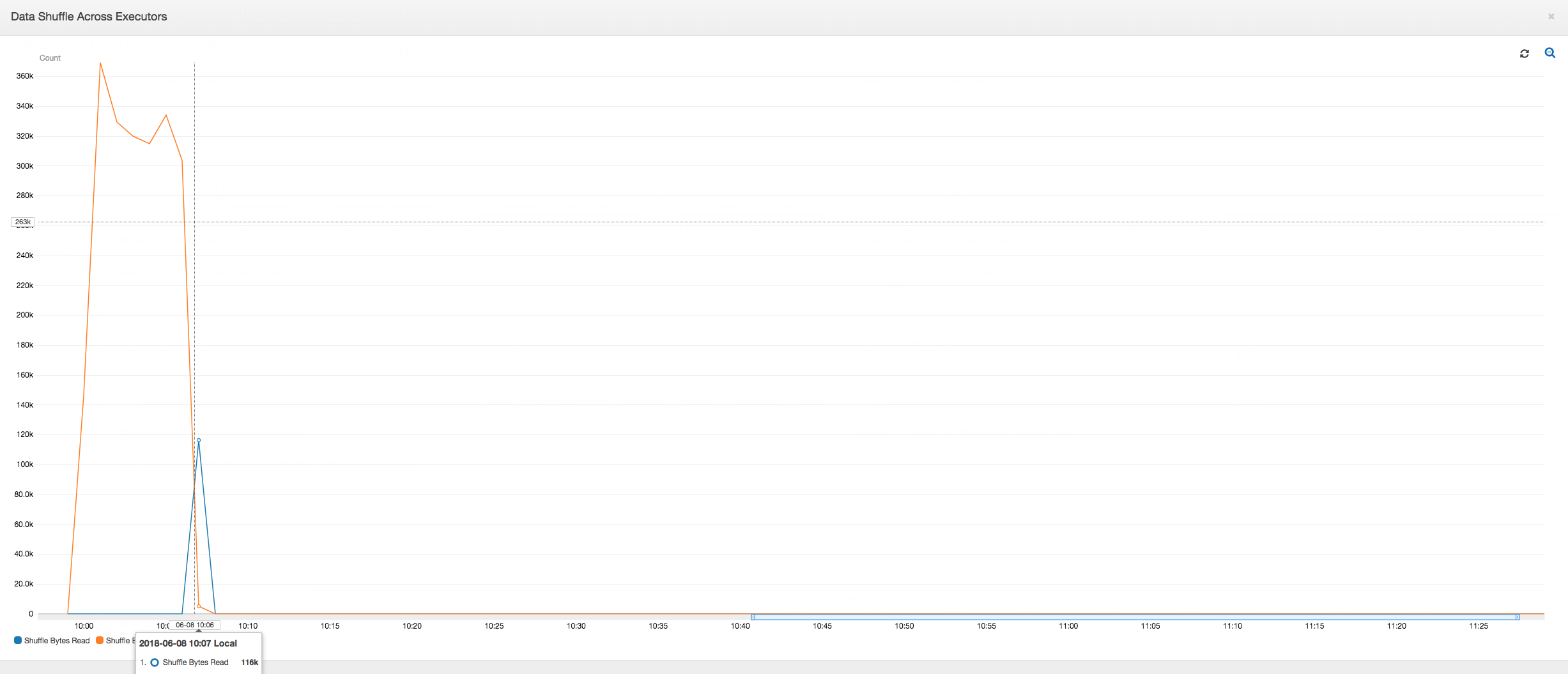
Remaniement de données sur les programmes d'exécution : Le nombre d'octets lus et écrits au cours du remaniement montre également un pic avant la fin de l'étape 2, comme le montrent les métriques de l'Exécution de tâche et du Remaniement de données. Suite au remaniement des données de tous les programmes d'exploitation, toutes les lectures et les écritures proviennent uniquement du programme d'exécution n°3.
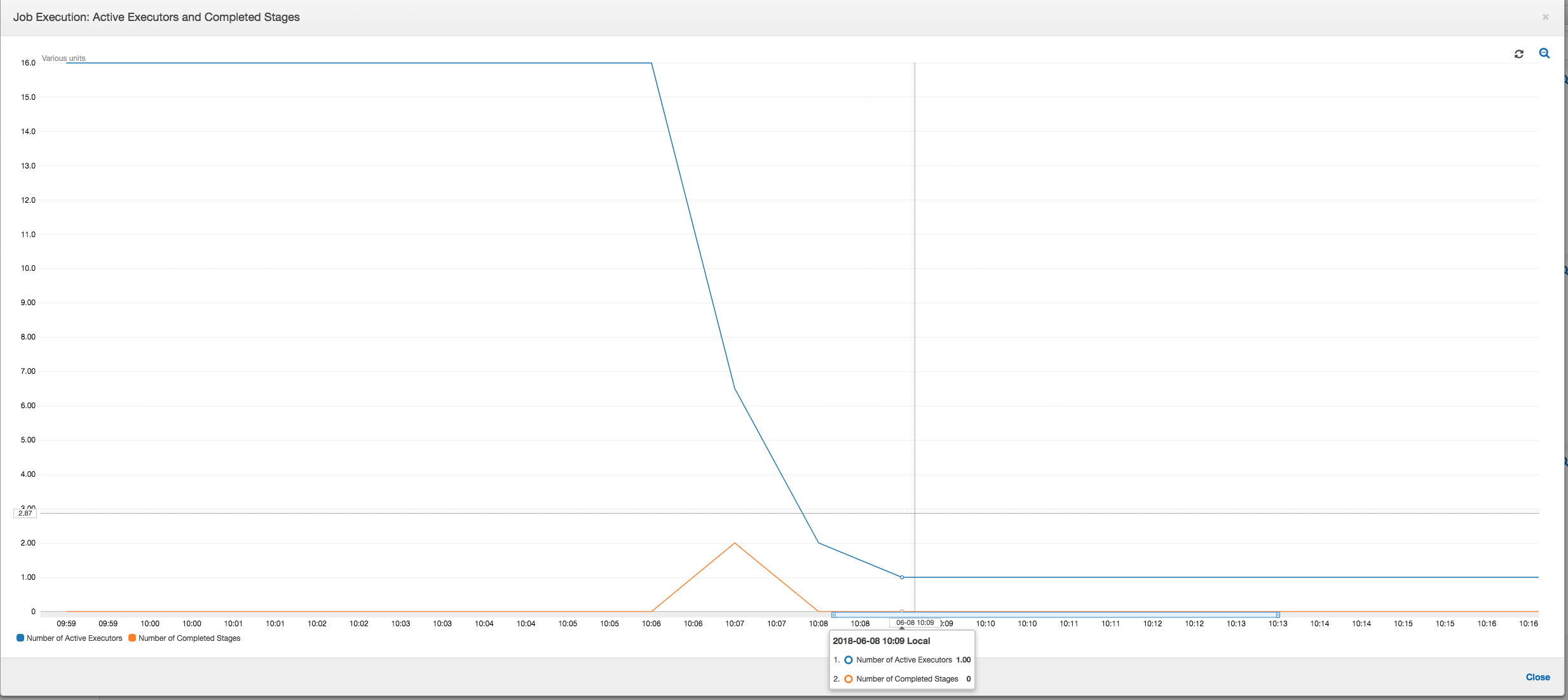
Exécution de tâche : Comme le montre le graphique ci-dessous, tous les autres programmes d'exécution sont inactifs et sont finalement abandonnés avant 10:09. A ce stade, le nombre total de programmes d'exécution diminue et il n'en reste qu'un. Ceci montre clairement que le programme d'exécution numéro 3 se compose de la tâche de ralentissement, dont la durée d'exécution est la plus longue, et contribue à la plus grande partie de la durée d'exécution de la tâche.
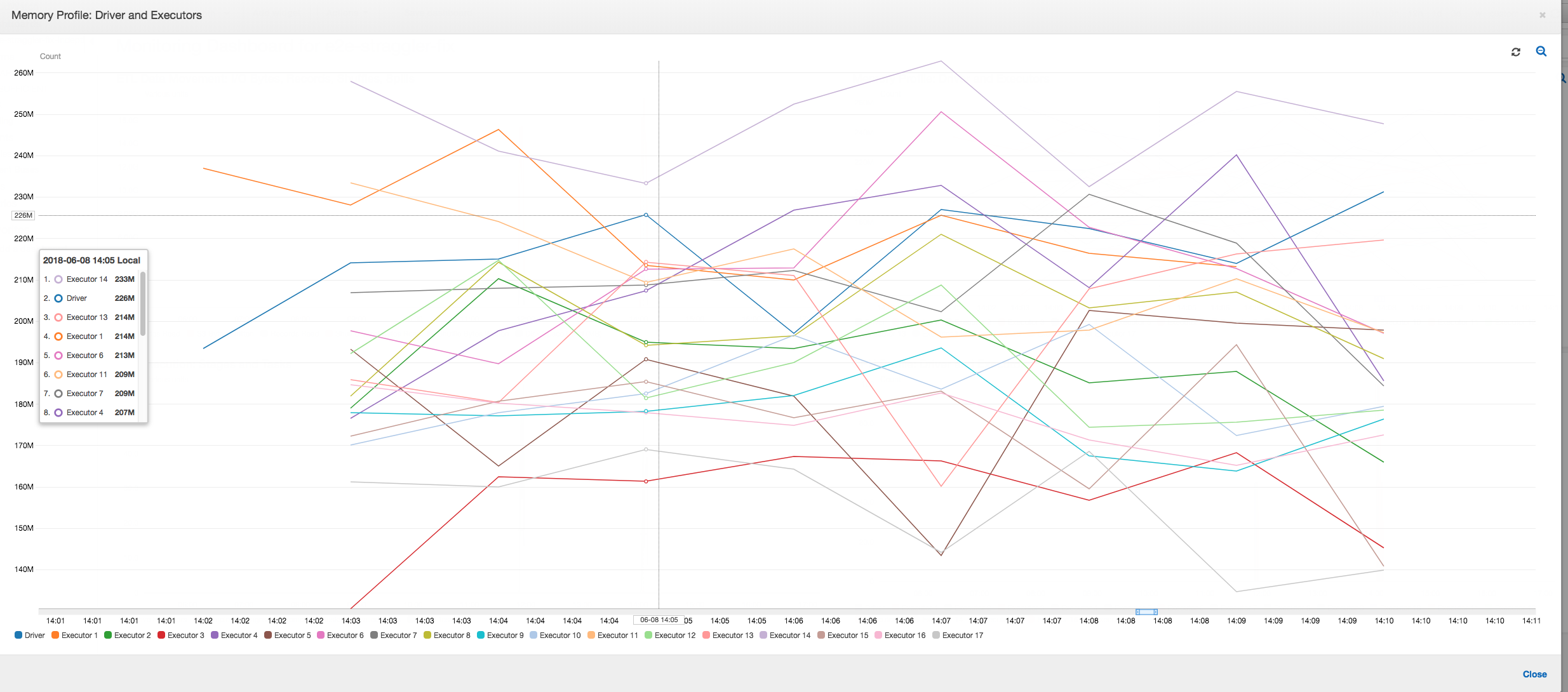
Profil de la mémoire : Après les deux premières étapes, seul le programme d'exécution n°3 consomme activement de la mémoire pour traiter les données. Les autres programmes d'exécution sont simplement inactifs ou ont été abandonnés peu de temps après la fin des deux premières étapes.
Corriger les programmes d'exécution en retard à l'aide du regroupement
Vous pouvez éviter de traîner les exécuteurs en utilisant la fonction de regroupement dans AWS Glue. Utilisez le regroupement pour répartir les données de manière uniforme sur tous les exécuteurs et fusionnez les fichiers en fichiers plus volumineux en utilisant tous les exécuteurs disponibles sur le cluster. Pour de plus amples informations, veuillez consulter Lecture des fichiers en entrée dans des groupes de plus grande taille.
Pour vérifier les mouvements de données ETL dans AWS Glue job, profilez le code suivant avec le regroupement activé :
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
Déplacement de données ETL : Les écritures de données sont désormais diffusées en parallèle avec les lectures de données pendant toute la durée d'exécution de la tâche. Par conséquent, la tâche est réalisée en huit minutes, soit beaucoup plus rapidement qu'avant.
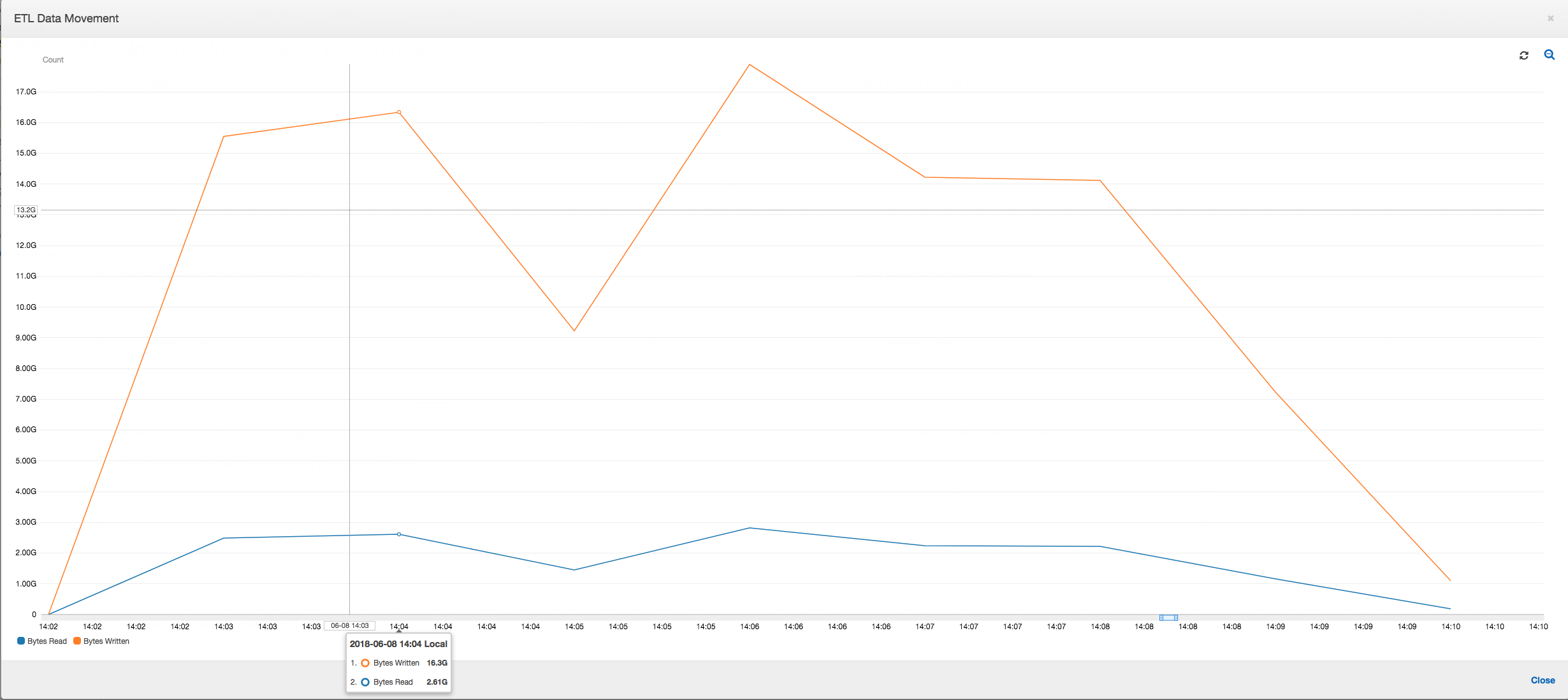
Remaniement des données sur les programmes d'exécution : Les données d'entrée ayant fusionné lors des lectures grâce à la fonction de regroupement, il n'y a pas de remaniement de données coûteux suite aux lectures de données.

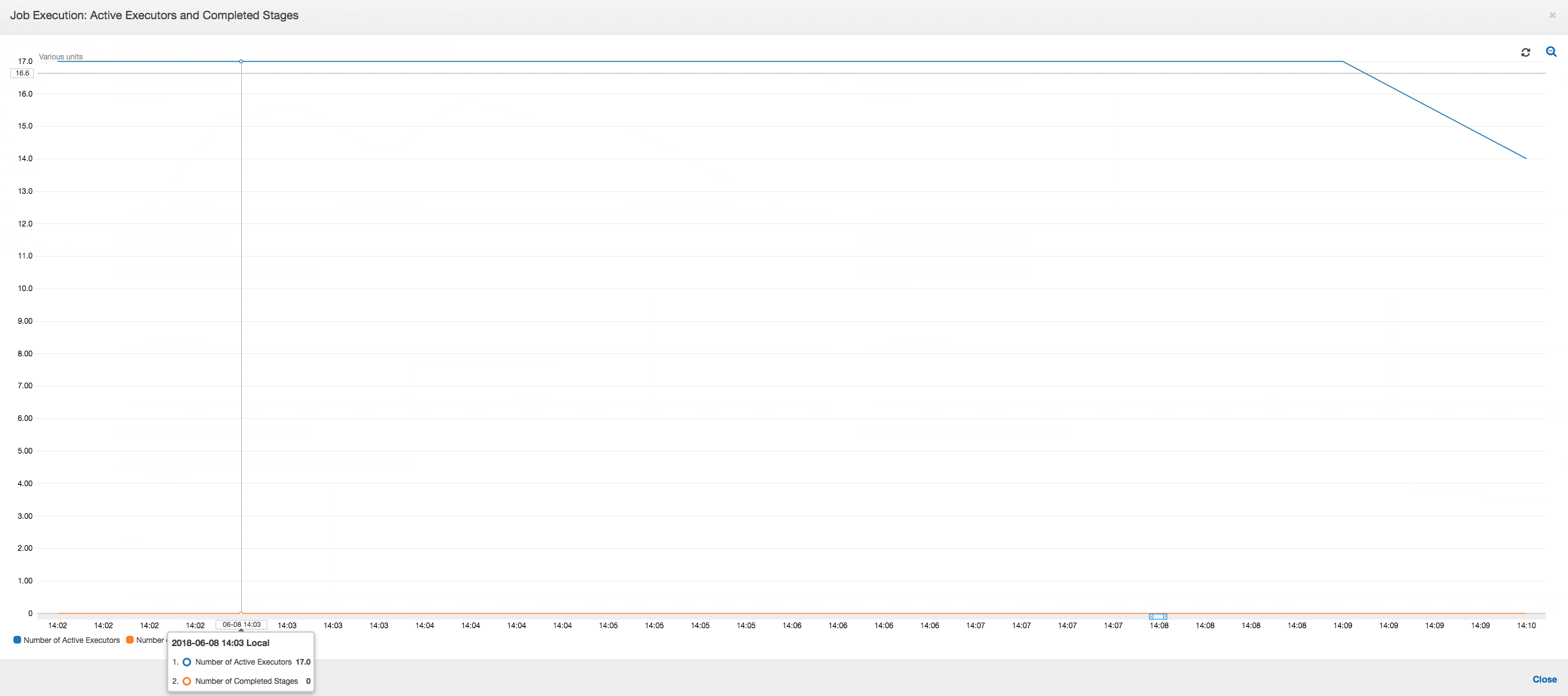
Exécution de tâche : Les métriques d'exécution de tâche montrent que le nombre total de programmes d'exécution actifs s'exécutant et traitant des données reste relativement constant. Il n'y a pas de ralentissement dans la tâche. Tous les programmes d'exécution restent actifs et ne sont pas abandonnés tant que la tâche n'est pas terminée. Comme il n'existe pas de remaniement intermédiaire de données sur les programmes d'exécution, il n'y a qu'une seule étape dans la tâche.
Memory profile (Profil de la mémoire) : les métriques montrent la consommation de mémoire active par l'ensemble des programmes d'exécution, confirmant une nouvelle fois qu'il existe une activité sur l'ensemble des programmes d'exécution. Les données étant parallèlement envoyées et reçues, l'espace mémoire total de tous les programmes d'exécution est à peu près uniforme et bien au-dessous du seuil de sécurité pour tous les programmes d'exécution.