Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comment fonctionnent les configurations de tâches
Vous utilisez les configurations de déploiement et d’annulation lorsque vous déployez une tâche, ainsi que les configurations de délai d’expiration et de nouvelle tentative pour l’exécution de la tâche. Les sections suivantes présentent plus d’informations sur le fonctionnement de ces configurations.
Rubriques
Configurations du déploiement, de la planification et de l’annulation des tâches
Vous pouvez utiliser les configurations de déploiement, de planification et d’annulation des tâches pour définir le nombre d’appareils recevant le document de tâche, planifier le déploiement d’une tâche et déterminer les critères d’annulation d’une tâche.
Vous pouvez spécifier la vitesse à laquelle les cibles sont averties d'une exécution de tâche en attente. Vous pouvez également créer un déploiement échelonné pour gérer les mises à jour, les redémarrages et d’autres opérations. Pour définir la manière dont vos cibles sont notifiées, utilisez les fréquences de déploiement des tâches.
Fréquences de déploiement des tâches
Vous pouvez créer une configuration de déploiement en utilisant une fréquence de déploiement constante ou une fréquence de déploiement exponentielle. Pour spécifier le nombre maximum d’objectifs de tâche à informer par minute, utilisez une fréquence de déploiement constante.
AWS IoT les emplois peuvent être déployés en utilisant des taux de déploiement exponentiels lorsque divers critères et seuils sont atteints. Si le nombre de tâches ayant échoué correspond à un ensemble de critères que vous spécifiez, vous pouvez annuler le déploiement des tâches. Vous définissez les critères de fréquence de déploiement des tâches lorsque vous créez une tâche à l’aide de l’objet JobExecutionsRolloutConfig. Les critères d’annulation de tâche sont définis lors de la création de la tâche via l’objet AbortConfig.
L’exemple suivant présente le fonctionnement des fréquence de déploiement. Par exemple, un déploiement de tâche avec une fréquence de base de 50 par minute, un facteur d’incrément de 2 et un nombre d’appareils notifiés et réussis égal à 1 000, fonctionnerait comme suit : la tâche débutera à un rythme de 50 exécutions par minute et se poursuivra à ce rythme jusqu’à ce que 1 000 objets aient reçu des notifications d’exécution de tâches ou que 1 000 exécutions de tâches aient eu lieu avec succès.
Le tableau suivant illustre la façon dont le déploiement procéderait sur les quatre premiers incréments.
|
Fréquence de lancement par minute |
50 |
100 |
200 |
400 |
|
Nombre d’appareils notifiés ou d’exécutions de tâches réussies pour satisfaire une augmentation de fréquence |
1 000 |
2 000 |
3 000 |
4 000 |
Note
Si vous avez atteint votre limite maximale de 500 tâches simultanées (isConcurrent = True), toutes les tâches actives conserveront le statut de IN-PROGRESS et ne lanceront aucune nouvelle exécution de tâches tant que le nombre de tâches simultanées ne sera pas inférieur ou égal à 499 (isConcurrent = False). Cela s’applique aux tâches instantanées et continues.
Si isConcurrent = True, la tâche déploie actuellement des exécutions de tâches sur tous les appareils de votre groupe cible. Si isConcurrent = False la tâche a terminé le déploiement de toutes les exécutions de tâches sur tous les appareils de votre groupe cible. Il mettra à jour son état une fois que tous les appareils de votre groupe cible auront atteint l’état terminal, ou un pourcentage seuil de votre groupe cible si vous avez sélectionné une configuration d’annulation de tâche. Le statut du niveau de tâche indique pour isConcurrent = True et isConcurrent = False sont les deux IN_PROGRESS.
Pour plus d’informations sur les limites des tâches actives et simultanées, consultez Limites de tâches actives et simultanées.
Fréquence de déploiement des tâches pour les tâches continues utilisant des groupes d’objets dynamiques
Lorsque vous utilisez une tâche continue pour déployer des opérations à distance sur votre flotte, AWS IoT Jobs exécute les tâches pour les appareils de votre groupe cible. Pour les nouveaux appareils ajoutés au groupe d’objets dynamiques, ces exécutions de tâches continuent d’être déployées sur ces appareils même après la création de la tâche.
La configuration de déploiement permet de contrôler les fréquence de déploiement uniquement pour les appareils ajoutés au groupe jusqu’à la création de la tâche. Après la création d’une tâche, pour tous les nouveaux appareils, les exécutions de tâches sont créées quasiment en temps réel dès que les appareils rejoignent le groupe cible.
Vous pouvez planifier une tâche continue ou instantanée jusqu’à un an à l’avance en utilisant une heure de début, une heure de fin et un comportement de fin prédéterminés indiquant ce qu’il adviendra de chaque exécution de tâche une fois l’heure de fin atteinte. En outre, vous pouvez créer un créneau de maintenance récurrente facultative avec une fréquence, une heure de début et une durée flexibles pour les tâches continues afin de déployer un document de tâche sur tous les appareils du groupe cible.
Configurations de planification des tâches
L’heure de début
L’heure de début d’une tâche planifiée correspond à la date et à l’heure futures auxquelles la tâche commencera à être déployée du document de tâche sur tous les appareils du groupe cible. L’heure de début d’une tâche planifiée s’applique aux tâches continues et aux tâches instantanées. Lorsqu’une tâche planifiée est initialement créée, elle conserve un état de statut de SCHEDULED. Lorsque vous arrivez au document startTime que vous avez sélectionné, il est mis à jour à IN_PROGRESS et commence le déploiement du document de tâche. Le délai startTime doit être inférieur ou égal à un an à compter de la date et de l’heure initiales auxquelles vous avez créé la tâche planifiée.
Pour plus d'informations sur la syntaxe à utiliser startTime lors de l'utilisation d'une commande d'API ou du AWS CLI, consultez Timestamp.
Pour une tâche avec une configuration de planification optionnelle qui a lieu pendant un créneau de maintenance récurrente dans un lieu respectant l’heure d’été (DST), l’heure changera d’une heure lors du passage de l’heure d’été à l’heure normale et de l’heure standard à l’heure d’été.
Note
Le fuseau horaire affiché dans le AWS Management Console est le fuseau horaire actuel de votre système. Toutefois, ces fuseaux horaires seront convertis en UTC dans le système.
L’heure de fin
L’heure de fin d’une tâche planifiée est la date et l’heure futures auxquelles la tâche arrêtera le déploiement du document de tâche sur tous les appareils restants du groupe cible. L’heure de fin d’une tâche planifiée s’applique aux tâches continues et aux tâches instantanées. Une fois qu’une tâche planifiée arrive à l’état sélectionné endTime et que toutes les exécutions de tâches ont atteint un état terminal, elle met à jour son état de statut de IN_PROGRESS à COMPLETED. Le délai endTime doit être inférieur ou égal à deux ans à compter de la date et de l’heure initiales auxquelles vous avez créé la tâche planifiée. La durée minimale entre startTime et endTime est de 30 minutes. Des tentatives de nouvelle tentative d’exécution de la tâche auront lieu jusqu’à ce que la tâche atteigne le endTime, puis endBehavior dicteront la marche à suivre.
Pour plus d'informations sur la syntaxe à utiliser endTime lors de l'utilisation d'une commande d'API ou du AWS CLI, consultez Timestamp.
Pour une tâche avec une configuration de planification optionnelle qui a lieu pendant un créneau de maintenance récurrente dans un lieu respectant l’heure d’été (DST), l’heure changera d’une heure lors du passage de l’heure d’été à l’heure normale et de l’heure standard à l’heure d’été.
Note
Le fuseau horaire affiché dans le AWS Management Console est le fuseau horaire actuel de votre système. Toutefois, ces fuseaux horaires seront convertis en UTC dans le système.
Comportement final
Le comportement final d’une tâche planifiée détermine ce qu’il advient de la tâche et de toutes les exécutions de tâches inachevées lorsque la tâche atteint la valeur sélectionnée endTime.
La liste suivante répertorie les comportements finaux que vous pouvez sélectionner lors de la création de la tâche ou du modèle de tâche :
-
STOP_ROLLOUT-
STOP_ROLLOUTarrête le déploiement du document de tâche sur tous les appareils restants du groupe cible de la tâche. De plus, toutes les exécutions de tâchesQUEUEDetIN_PROGRESSse poursuivront jusqu’à ce qu’elles atteignent l’état terminal. Il s’agit du comportement final par défaut, sauf si vous sélectionnezCANCELouFORCE_CANCEL.
-
-
CANCEL-
CANCELarrête le déploiement du document de tâche sur tous les appareils restants du groupe cible de la tâche. En outre, toutes les exécutions de tâchesQUEUEDseront annulées et toutes les exécutions de tâchesIN_PROGRESSse poursuivront jusqu’à ce qu’elles atteignent un état terminal.
-
-
FORCE_CANCEL-
FORCE_CANCELarrête le déploiement du document de tâche sur tous les appareils restants du groupe cible de la tâche. De plus, toutes les exécutions de tâchesQUEUEDetIN_PROGRESSseront annulées.
-
Note
Pour sélectionner unendbehavior, vous devez sélectionner un endtime
Durée maximale
La durée maximale d’un tâche planifié doit être inférieure ou égale à deux ans, quel que soit le startTime et endTime.
Le tableau suivant répertorie les scénarios de durée courants d’une tâche planifiée :
| Numéro de l'exemple de tâche planifiée | startTime | endTime | Durée maximale |
|---|---|---|---|
|
1 |
Immédiatement après la création initiale d’emplois. |
Un an après la création initiale d’emplois. |
Un an |
|
2 |
Un mois après la création initiale de l’emploi. |
13 mois après la création initiale de l’emploi. |
Un an |
|
3 |
Un an après la création initiale d’emplois. |
Deux ans après la création initiale d’emplois. |
Un an |
|
4 |
Immédiatement après la création initiale d’emplois. |
Deux ans après la création initiale d’emplois. |
Deux ans |
Créneau de maintenance récurrente
La fenêtre de maintenance est une configuration facultative dans la configuration de planification du AWS Management Console et SchedulingConfig dans le CreateJob et CreateJobTemplate APIs. Vous pouvez configurer un créneau de maintenance récurrente avec une heure de début, une durée et une fréquence (quotidienne, hebdomadaire ou mensuelle) prédéterminées. Les créneaux de maintenance ne s’appliquent qu’aux tâches continues. La durée maximale d’un créneau de maintenance récurrente est de 23 heures et 50 minutes.
Le schéma suivant illustre l’état d’avancement des tâches pour différents scénarios de tâches planifiées avec un créneau de maintenance facultative :
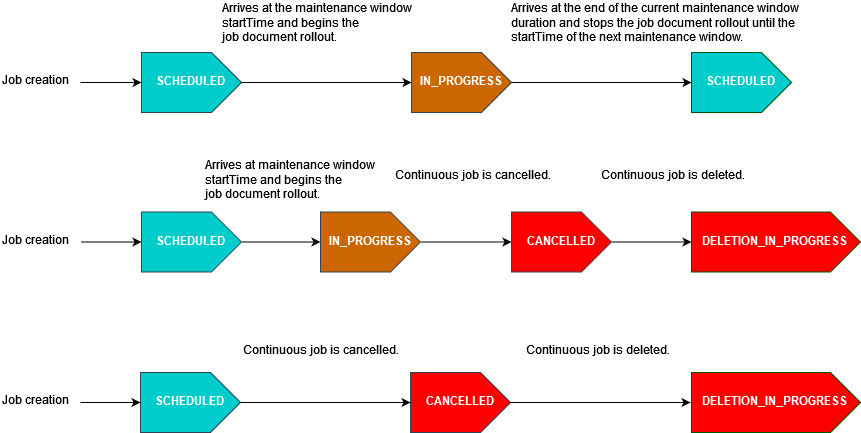
Pour de plus amples informations sur l’état du statut d’une tâche, veuillez consulter Tâches et états d'exécution des tâches.
Note
Si une tâche arrive à endTime pendant une période de maintenance, elle sera mise à jour de IN_PROGRESS à COMPLETED. De plus, toutes les exécutions de tâches restantes suivront endBehavior pour la tâche.
Expressions Cron
Pour les tâches planifiées déployant le document de tâche pendant un créneau de maintenance avec une fréquence personnalisée, la fréquence personnalisée est saisie à l’aide d’une expression cron. Une expression cron se compose de six champs obligatoires qui sont séparés par des espaces.
Syntaxe
cron(fields)
| Champ | Valeurs | Caractères génériques |
|---|---|---|
|
Minutes |
0-59 |
, - * / |
|
Heures |
0-23 |
, - * / |
|
D ay-of-month |
1-31 |
, - * ? / L W |
|
Mois |
1-12 ou JAN-DEC |
, - * / |
|
D ay-of-week |
1-7 ou DIM-SAM |
, - * ? L # |
|
Année |
1970-2199 |
, - * / |
Caractères génériques
-
Le caractère générique , (virgule) inclut des valeurs supplémentaires. Dans le champ Mois, JAN,FEB,MAR englobe janvier, février et mars.
-
Le caractère générique - (tiret) spécifie des plages. Dans le champ Jour, 1-15 englobe les jours 1 à 15 du mois spécifié.
-
Le caractère générique * (astérisque) inclut toutes les valeurs du champ. Dans le champ Hours, * inclut toutes les heures. Vous ne pouvez pas utiliser * à la fois dans les Day-of-week champs Day-of-month et. Si vous l'utilisez dans un champ, vous devez utiliser ? dans l'autre.
-
Le caractère générique / (barre oblique) spécifie les incréments. Dans le champ Minutes, vous pouvez entrer 1/10 pour spécifier toutes les dix minutes, à partir de la première minute de l'heure (par exemple, les 11e, 21e, 31e minutes, et ainsi de suite).
-
Le caractère générique ? (point d’interrogation) indique l’un ou l’autre. Dans le Day-of-month champ, vous pouvez saisir 7 et si vous ne vous souciez pas du jour de la semaine le 7, vous pouvez entrer ? sur le Day-of-week terrain.
-
Le caractère générique L dans les champs ou spécifie le dernier jour du mois ou de la semaine. Day-of-month Day-of-week
-
Le
Wcaractère générique dans le Day-of-month champ indique un jour de la semaine. Dans le Day-of-month champ,3Windique le jour de la semaine le plus proche du troisième jour du mois. -
Le caractère générique # dans le Day-of-week champ indique une certaine instance du jour de la semaine spécifié dans un délai d'un mois. Par exemple, 3#2 correspond au deuxième mardi du mois : le 3 fait référence à mardi, car c’est le troisième jour de chaque semaine, et le 2 fait référence à la deuxième journée de ce type dans le mois.
Note
Si vous utilisez un caractère « # », vous ne pouvez définir qu'une seule expression dans le day-of-week champ. Par exemple,
"3#1,6#3"n’est pas valide, car il est interprété comme deux expressions.
Restrictions
-
Vous ne pouvez pas spécifier les champs Day-of-month et Day-of-week de la même expression cron. Si vous spécifiez une valeur dans l’un de ces champs, vous devez utiliser un caractère générique ? dans l’autre.
Exemples
Reportez-vous aux exemples de chaînes cron suivants lorsque vous utilisez une expression cron pour la startTime de maintenance récurrente.
| Minutes | Heures | Jour du mois | Mois | Jour de la semaine | Année | Signification |
|---|---|---|---|---|---|---|
| 0 USD | 10 | * | * | ? | * |
Exécuter à 10 h 00 (UTC) chaque jour |
| 15 | 12 | * | * | ? | * |
Exécuter à 12 h 15 (UTC) chaque jour |
| 0 | 18 | ? | * | MON-FRI | * |
Exécuter à 18 h 00 (UTC) du lundi au vendredi |
| 0 | 8 | 1 | * | ? | * |
Exécuter à 8 h 00 (UTC) chaque 1er jour du mois |
Durée du créneau de maintenance récurrente et logique de fin
Lorsqu’un déploiement de tâche pendant un créneau de maintenance atteint la fin de la durée d’occurrence du créneau de maintenance en cours, les actions suivantes se produisent :
-
La tâche interrompra tous les déploiements du document de tâche sur tous les appareils restants de votre groupe cible. Il reprendra au créneau
startTimede maintenance suivant. -
Toutes les exécutions de tâches dont le statut de
QUEUEDresteront dansQUEUEDjusqu’à lastartTimede la prochaine occurrence du créneau de maintenance. Dans le créneau suivant, ils peuvent passer àIN_PROGRESSau moment où l’appareil est prêt à commencer à exécuter les actions spécifiées dans le document de tâche. -
Toutes les exécutions de tâches dont le statut est
IN_PROGRESScontinueront d’exécuter les actions spécifiées dans le document de tâche jusqu’à ce qu’elles atteignent l’état terminal. Toute nouvelle tentative, comme indiqué dansJobExecutionsRetryConfigaura lieu au prochain créneaustartTimede maintenance.
Utilisez cette configuration pour créer un critère d’annulation d’une tâche lorsqu’un pourcentage seuil d’appareils répond à ces critères. Par exemple, vous pouvez utiliser cette configuration pour annuler une tâche dans les cas suivants :
-
Lorsqu'un pourcentage minimal d'appareils ne reçoit pas les notifications d'exécution de la tâche, par exemple lorsque votre appareil n'est pas compatible avec une mise à jour Over-The-Air (OTA). Dans ce cas, votre appareil peut signaler un statut
REJECTED. -
Lorsqu’un certain pourcentage d’appareils signalent l’échec de l’exécution de leurs tâches, par exemple lorsque votre appareil se déconnecte lorsqu’il tente de télécharger le document de tâche depuis une URL Amazon S3. Dans de tels cas, votre appareil doit être programmé pour signaler le statut
FAILUREà AWS IoT. -
Lorsqu’un statut
TIMED_OUTest signalé parce que l’exécution de la tâche expire pour un certain pourcentage d’appareils après le début de l’exécution de la tâche. -
En cas d’échec de plusieurs tentatives. Lorsque vous ajoutez une configuration de nouvelle tentative, chaque nouvelle tentative peut entraîner des frais supplémentaires pour votre Compte AWS. Dans de tels cas, l’annulation de la tâche peut annuler les exécutions de tâches en file d’attente et éviter de nouvelles tentatives pour ces exécutions. Pour plus d’informations sur la configuration de nouvelle tentative et son utilisation avec la configuration d’annulation, consultez Configurations du délai d’exécution des tâches et des nouvelles tentatives.
Vous pouvez configurer une condition d'abandon de tâche à l'aide de la AWS IoT console ou de l'API AWS IoT Jobs.
Configurations du délai d’exécution des tâches et des nouvelles tentatives
Utilisez la configuration du délai d’exécution des tâches pour vous envoyer Notifications Jobs lorsqu’une exécution de tâche est en cours depuis plus longtemps que la durée définie. Utilisez la configuration de nouvelle tentative d’exécution de la tâche pour réessayer l’exécution lorsque la tâche échoue ou expire.
La configuration du délai d’exécution d’une tâche permet de vous avertir lorsqu’une tâche reste bloqué dans l’état IN_PROGRESS pendant une période de temps excessivement longue. Lorsque la tâche est IN_PROGRESS, vous pouvez suivre la progression de son exécution.
Minuteurs pour les délais d’expiration des tâches
Il existe deux types de minuteurs : minuteurs d'avancement et minuteurs d'étape.
Chronomètres en cours
Lorsque vous créez une tâche ou un modèle de tâche, vous pouvez spécifier une valeur comprise entre 1 minute et 7 jours pour le chronomètre en cours. Vous pouvez mettre à jour la valeur de ce chronomètre jusqu’au début de l’exécution de votre tâche. Une fois le chronomètre démarrée, il ne peut pas être mis à jour et la valeur du chronomètre s’applique à toutes les exécutions de tâches associées à la tâche. Chaque fois qu'une exécution de tâche reste dans le IN_PROGRESS statut pendant plus longtemps que cet intervalle, l'exécution de la tâche échoue et passe à l'TIMED_OUTétat du terminal. AWS IoT publie également une notification MQTT.
Chronomètre à étapes
Vous pouvez également définir un chronomètre qui s’applique uniquement à l’exécution de la tâche que vous souhaitez mettre à jour. Ce chronomètre n’a aucun effet sur le chronomètre en cours. Chaque fois que vous mettez à jour l’exécution d’une tâche, vous pouvez définir une nouvelle valeur pour la temporisation. Vous pouvez également créer un nouveau chronomètre lorsque vous démarrez l’exécution de tâche en attente suivante pour un objet. Si l'exécution de tâche demeure dans l'état IN_PROGRESS plus longtemps que l'intervalle du minuteur d'étape, elle échoue et passe à l'état final TIMED_OUT.
Note
Vous pouvez définir le chronomètre en cours à l'aide de la AWS IoT console ou de l'API AWS IoT Jobs. Pour spécifier le chronomètre, utilisez l’API.
Comment fonctionnent les chronomètres pour les délais d’expiration des tâches
Les exemples suivants illustrent les interactions entre les délais d’attente en cours et les délais d’attente par étape au cours d’une période de 20 minutes.
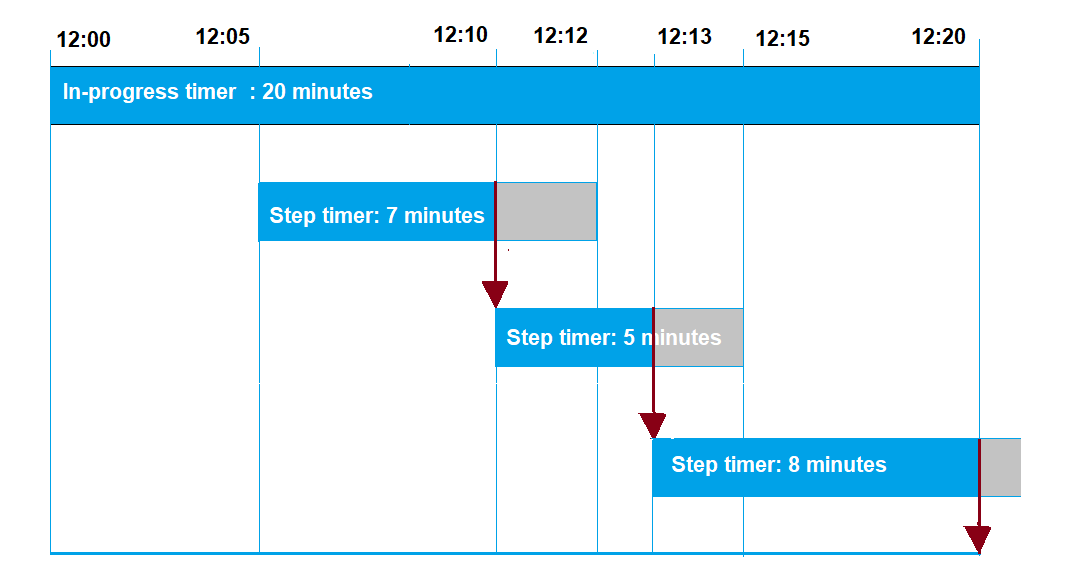
Les différentes étapes sont illustrées ci-dessous :
-
12h00
Une nouvelle tâche est créée et un chronomètre en cours de vingt minutes démarre lors de la création d’une tâche. Le chronomètre en cours commence à s’exécuter et l’exécution de la tâche passe au statut
IN_PROGRESS. -
12h05
Un nouveau chronomètre à étapes d’une valeur de 7 minutes est créé. L’exécution de la tâche expirera désormais à 12h12.
-
12h10
Un nouveau chronomètre à étapes d’une valeur de 5 minutes est créé. Lorsqu’un nouveau chronomètre est créé, le chronomètre à étapes précédent est supprimé et l’exécution de la tâche expire désormais à 12h15.
-
12h13
Un nouveau chronomètre à étapes d’une valeur de 9 minutes est créé. Le chronomètre à étapes précédent est supprimé et l’exécution de la tâche expirera désormais à 12h20 car le chronomètre en cours expire à 12h20. Le chronomètre à étapes ne peut pas dépasser la limite absolue du chronomètre à étapes en cours.
Vous pouvez utiliser la configuration de nouvelle tentative pour réessayer l’exécution de la tâche lorsqu’un certain ensemble de critères est satisfait. Une nouvelle tentative peut être tentée lorsqu’une tâche arrive à expiration ou lorsque l’appareil échoue. Pour réessayer l’exécution en raison d’un échec du délai d’attente, vous devez activer la configuration du délai d’expiration.
Comment utiliser la configuration de nouvelle tentative
Effectuez les étapes suivantes pour réessayer cette configuration.
-
Déterminez s’il convient d’utiliser la configuration de nouvelle tentative pour
FAILED,TIMED_OUTou les deux critères d’échec. En ce qui concerne leTIMED_OUT -
Pour connaître le statut
FAILED, vérifiez si l’échec de l’exécution de votre tâche peut être réessayé. S’il est possible de réessayer, programmez votre appareil pour qu’il signale un statutFAILUREà AWS IoT. La section suivante décrit plus en détail les échecs réessayables et non réessayables. -
Spécifiez le nombre de tentatives à utiliser pour chaque type d’échec à l’aide des informations précédentes. Pour un seul appareil, vous pouvez spécifier jusqu’à 10 tentatives pour les deux types d’échec combinés. Les tentatives de nouvelle tentative s’arrêtent automatiquement lorsqu’une exécution réussit ou lorsqu’elle atteint le nombre de tentatives spécifié.
-
Ajoutez une configuration d’annulation pour annuler le tâche en cas d’échecs répétés afin d’éviter des frais supplémentaires liés à un grand nombre de nouvelles tentatives.
Note
Lorsqu’une tâche arrive à la fin d’une période de maintenance récurrente, toutes les exécutions de tâches IN_PROGRESS continuent à exécuter les actions identifiées dans le document de tâche jusqu’à ce qu’elles atteignent l’état terminal. Si l’exécution d’une tâche atteint un état terminal de FAILED ou TIMED_OUT en dehors d’un créneau de maintenance, une nouvelle tentative aura lieu dans le créneau suivant si les tentatives ne sont pas épuisées. À la startTime du prochain créneau de maintenance, une nouvelle exécution de tâche sera créée et entrera dans un état de QUEUED jusqu’à ce que l’appareil soit prêt à commencer.
Réessayer et annuler la configuration
Chaque nouvelle tentative entraîne des frais supplémentaires pour votre. Compte AWS Pour éviter d’encourir des frais supplémentaires en cas d’échecs répétés, nous vous recommandons d’ajouter une configuration d’annulation. Pour de plus amples informations sur la tarification, veuillez consulter AWS IoT Device Management
Tarification
Plusieurs tentatives peuvent échouer lorsqu’un pourcentage élevé de vos appareils expire ou signale un échec. Dans ce cas, vous pouvez utiliser la configuration d’annulation pour annuler la tâche et éviter toute exécution de tâche en file d’attente ou toute nouvelle tentative.
Note
Lorsque les critères d’annulation sont remplis pour annuler l’exécution d’une tâche, seules les exécutions de tâches QUEUED sont annulées. Aucune nouvelle tentative en file d’attente pour l’appareil ne sera tentée. Toutefois, les exécutions de tâches en cours qui ont un statut IN_PROGRESS ne seront pas annulées.
Avant de réessayer l’exécution d’une tâche qui a échoué, nous vous recommandons également de vérifier si l’échec de l’exécution de la tâche est réessayable, comme décrit dans la section suivante.
Réessayez en cas d’échec de type FAILED
Pour tenter une nouvelle tentative en cas d’échec de type FAILED, vos appareils doivent être programmés pour signaler l’état FAILURE de l’échec de l’exécution d’une tâche à AWS IoT. Définissez la configuration des nouvelles tentatives avec les critères permettant de réessayer l’exécution des tâches FAILED et spécifiez le nombre de tentatives à effectuer. Lorsque AWS IoT Jobs détecte l'FAILUREétat, il tente automatiquement de réessayer d'exécuter le travail pour le périphérique. Les tentatives se poursuivent jusqu’à ce que l’exécution de la tâche réussisse ou jusqu’à ce que le nombre maximal de tentatives soit atteint.
Vous pouvez suivre chaque nouvelle tentative et le tâche en cours d’exécution sur ces appareils. En suivant l’état d’exécution, une fois que le nombre de tentatives spécifié a été atteint, vous pouvez utiliser votre appareil pour signaler les échecs et lancer une nouvelle tentative.
Défaillances réessayables et non réessayables
L’échec de l’exécution de votre tâche peut être réessayable ou non. Chaque nouvelle tentative peut entraîner des frais pour votre Compte AWS. Pour éviter d’encourir des frais supplémentaires en cas de tentatives multiples, pensez d’abord à vérifier si l’échec de l’exécution de votre tâche est réessayable. Un exemple d’échec réessayable inclut une erreur de connexion rencontrée par votre appareil lors de la tentative de téléchargement du document de tâche à partir d’une URL Amazon S3. Si l’échec de l’exécution de votre tâche est réessayable, programmez votre appareil pour qu’il signale un état FAILURE en cas d’échec de l’exécution de la tâche. Définissez ensuite la configuration de nouvelle tentative pour réessayer les exécutions FAILED.
Si l’exécution ne peut pas être relancée, afin d’éviter toute nouvelle tentative et d’entraîner des frais supplémentaires pour votre compte, nous vous recommandons de programmer l’appareil pour qu’il signale un statut REJECTED à AWS IoT. Parmi les échecs non réessayables, citons les cas où votre appareil n’est pas compatible avec la réception d’une mise à jour de tâche ou lorsqu’il rencontre une erreur de mémoire lors de l’exécution d’une tâche. Dans ces cas, AWS IoT Jobs ne réessaiera pas d'exécuter le travail car il ne recommencera l'exécution du travail que s'il détecte un statut FAILED ouTIMED_OUT.
Après avoir déterminé qu’un échec d’exécution d’une tâche est réessayable, si une nouvelle tentative échoue toujours, pensez à consulter les journaux de l’appareil.
Note
Lorsqu’une tâche avec la configuration de planification facultative atteint sa endTime, la commande endBehavior sélectionnée arrête le déploiement du document de tâche sur tous les appareils restants du groupe cible et dicte la marche à suivre pour les exécutions de tâches restantes. Les tentatives sont renouvelées si elles sont sélectionnées via la configuration de nouvelle tentative.
Réessayez en cas d’échec de type TIMEOUT
Si vous activez le délai d'expiration lors de la création d'une tâche, AWS IoT Jobs tentera de réessayer d'exécuter la tâche pour le périphérique lorsque le statut passe de àIN_PROGRESS. TIMED_OUT Ce changement d’état peut se produire lorsque le chronomètre en cours expire ou lorsqu’un chronomètre que vous spécifiez est IN_PROGRESS puis expire. Les tentatives se poursuivent jusqu’à ce que l’exécution de la tâche réussisse ou jusqu’à ce que le nombre maximal de tentatives soit atteint pour ce type d’échec.
Mises à jour continues sur les tâches et les membres des groupes d’objets
Pour les tâches continues dont le statut est égal à IN_PROGRESS, le nombre de nouvelles tentatives est remis à zéro lorsque l’appartenance au groupe d’un objet est mise à jour. Supposons, par exemple, que vous avez spécifié cinq tentatives et que trois tentatives ont déjà été effectuées. Si un objet est maintenant supprimé du groupe d’objets puis rejoint le groupe, par exemple dans le cas de groupes d’objets dynamiques, le nombre de nouvelles tentatives est remis à zéro. Vous pouvez désormais effectuer cinq tentatives pour votre groupe d’objets au lieu des deux tentatives restantes. En outre, lorsqu’un objet est supprimé du groupe d’objets, les tentatives supplémentaires sont annulées.
