Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créez un plan de migration pour migrer d'Apache Cassandra vers Amazon Keyspaces
Pour une migration réussie d'Apache Cassandra vers Amazon Keyspaces, nous vous recommandons de passer en revue les concepts de migration applicables et les meilleures pratiques, ainsi que de comparer les options disponibles.
Cette rubrique décrit le fonctionnement du processus de migration en présentant plusieurs concepts clés ainsi que les outils et techniques mis à votre disposition. Vous pouvez évaluer les différentes stratégies de migration afin de sélectionner celle qui répond le mieux à vos besoins.
Rubriques
Compatibilité fonctionnelle
Examinez attentivement les différences fonctionnelles entre Apache Cassandra et Amazon Keyspaces avant la migration. Amazon Keyspaces prend en charge toutes les opérations courantes du plan de données Cassandra, telles que la création d'espaces de touches et de tables, la lecture de données et l'écriture de données.
Cependant, Amazon Keyspaces ne prend pas en charge certaines Cassandra APIs . Pour plus d'informations sur la prise en charge APIs, consultezCassandra APIs, opérations, fonctions et types de données pris en charge. Pour un aperçu de toutes les différences fonctionnelles entre Amazon Keyspaces et Apache Cassandra, consultez. Différences fonctionnelles : Amazon Keyspaces et Apache Cassandra
Pour comparer le Cassandra APIs et le schéma que vous utilisez aux fonctionnalités prises en charge dans Amazon Keyspaces, vous pouvez exécuter un script de compatibilité disponible dans le kit d'outils Amazon Keyspaces sur. GitHub
Comment utiliser le script de compatibilité
Téléchargez le script Python de compatibilité depuis GitHub
et déplacez-le vers un emplacement ayant accès à votre cluster Apache Cassandra existant. Le script de compatibilité utilise des paramètres similaires à
CQLSH.--portEntrez--hostet saisissez l'adresse IP et le port que vous utilisez pour vous connecter et exécuter des requêtes sur l'un des nœuds Cassandra de votre cluster.Si votre cluster Cassandra utilise l'authentification, vous devez également fournir
-usernameet-password. Pour exécuter le script de compatibilité, vous pouvez utiliser la commande suivante.python toolkit-compat-tool.py --hosthostname or IP-u "username" -p "password" --portnative transport port
Estimer le prix d'Amazon Keyspaces
Cette section fournit un aperçu des informations que vous devez collecter à partir de vos tables Apache Cassandra pour calculer le coût estimé d'Amazon Keyspaces. Chacune de vos tables nécessite des types de données différents, doit prendre en charge différentes requêtes CQL et gère un trafic de lecture/écriture distinct.
La prise en compte de vos besoins sur la base de tableaux correspond aux modes d'isolation des ressources au niveau des tables d'Amazon Keyspaces et de capacité de débit de lecture/écriture. Avec Amazon Keyspaces, vous pouvez définir la capacité de lecture/écriture et les politiques de dimensionnement automatique pour les tables de manière indépendante.
Comprendre les exigences relatives aux tables vous permet de hiérarchiser les tables à migrer en fonction des fonctionnalités, du coût et de l'effort de migration.
Collectez les métriques de la table Cassandra suivantes avant une migration. Ces informations permettent d'estimer le coût de votre charge de travail sur Amazon Keyspaces.
Nom de la table : nom du keyspace complet et du nom de la table.
Description : description de la table, par exemple de son utilisation ou du type de données qui y est stocké.
Nombre moyen de lectures par seconde : nombre moyen de lectures au niveau des coordonnées par rapport à la table sur un long intervalle de temps.
Nombre moyen d'écritures par seconde : nombre moyen d'écritures au niveau des coordonnées par rapport à la table sur un long intervalle de temps.
Taille de ligne moyenne en octets : taille de ligne moyenne en octets.
Taille de stockage en GBs : taille de stockage brute d'une table.
Répartition de la cohérence des lectures : pourcentage de lectures utilisant une cohérence éventuelle (
LOCAL_ONEouONE) par rapport à une cohérence forte (LOCAL_QUORUM).
Ce tableau présente un exemple des informations relatives à vos tables que vous devez rassembler lors de la planification d'une migration.
| Nom de la table | Description | Nombre moyen de lectures par seconde | Nombre moyen d'écritures par seconde | Taille moyenne des lignes en octets | Taille de stockage en GBs | Lire le tableau de cohérence |
|---|---|---|---|---|---|---|
|
mykeyspace.mytable |
Utilisé pour enregistrer l'historique du panier |
10 000 |
5 000 |
2 200 |
2 000 |
100 % |
mykeyspace.mytable2 |
Utilisé pour stocker les dernières informations de profil |
20 000 |
1 000 |
850 |
1 000 |
25 % |
Comment collecter les métriques d'un tableau
Cette section fournit des instructions étape par étape sur la façon de collecter les métriques de table nécessaires à partir de votre cluster Cassandra existant. Ces mesures incluent la taille des lignes, la taille des tables et les demandes de lecture/écriture par seconde (RPS). Ils vous permettent d'évaluer les besoins en capacité de débit pour une table Amazon Keyspaces et d'estimer les prix.
Comment collecter des métriques de table sur la table source de Cassandra
Déterminer la taille des lignes
La taille des lignes est importante pour déterminer la capacité de lecture et l'utilisation de la capacité d'écriture dans Amazon Keyspaces. Le schéma suivant montre la distribution typique des données sur une plage de jetons Cassandra.
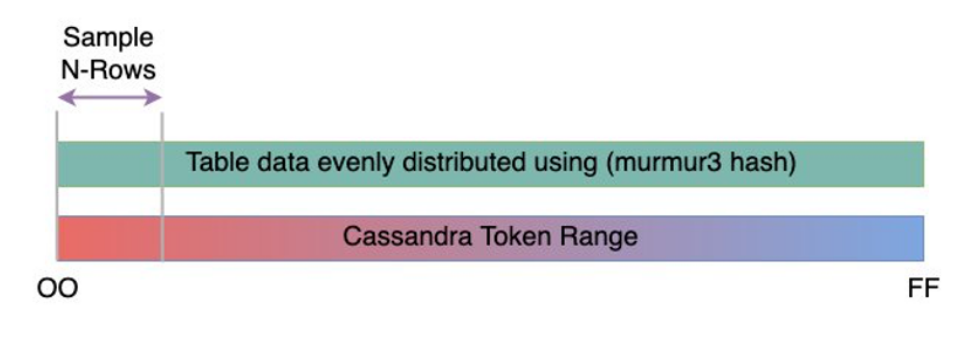
Vous pouvez utiliser un script d'échantillonnage de taille de ligne disponible sur GitHub
pour collecter des métriques de taille de ligne pour chaque table de votre cluster Cassandra. Le script exporte les données de table depuis Apache Cassandra en utilisant
cqlshetawkpour calculer le minimum, le maximum, la moyenne et l'écart type de la taille des lignes sur un ensemble d'échantillons configurable de données de table. L'échantillonneur de taille de ligne transmet les arguments àcqlsh, de sorte que les mêmes paramètres peuvent être utilisés pour se connecter et lire à partir de votre cluster Cassandra.La déclaration suivante en est un exemple.
./row-size-sampler.sh10.22.33.449142 \\ -u "username" -p "password" --sslPour plus d'informations sur le calcul de la taille des lignes dans Amazon Keyspaces, consultez. Estimer la taille des lignes dans Amazon Keyspaces
Déterminer la taille de la table
Avec Amazon Keyspaces, vous n'avez pas besoin de provisionner le stockage à l'avance. Amazon Keyspaces surveille en permanence la taille facturable de vos tables afin de déterminer vos frais de stockage. Le stockage est facturé par Go par mois. La taille du tableau Amazon Keyspaces est basée sur la taille brute (non compressée) d'une seule réplique.
Pour surveiller la taille du tableau dans Amazon Keyspaces, vous pouvez utiliser la métrique
BillableTableSizeInBytes, qui est affichée pour chaque tableau dans le. AWS Management ConsolePour estimer la taille facturable de votre tableau Amazon Keyspaces, vous pouvez utiliser l'une des deux méthodes suivantes :
Utilisez la taille moyenne des lignes et multipliez-la par le nombre de lignes.
Vous pouvez estimer la taille de la table Amazon Keyspaces en multipliant la taille moyenne des lignes par le nombre de lignes de votre table source Cassandra. Utilisez l'exemple de script de taille de ligne de la section précédente pour capturer la taille de ligne moyenne. Pour capturer le nombre de lignes, vous pouvez utiliser des outils tels que
dsbulk countla détermination du nombre total de lignes dans votre table source.Utilisez le
nodetoolpour collecter les métadonnées des tables.Nodetoolest un outil administratif fourni dans la distribution Apache Cassandra qui fournit un aperçu de l'état du processus Cassandra et renvoie les métadonnées des tables. Vous pouvez les utilisernodetoolpour échantillonner les métadonnées relatives à la taille des tables et ainsi extrapoler la taille des tables dans Amazon Keyspaces.La commande à utiliser est
nodetool tablestats. Tablestats renvoie la taille et le taux de compression de la table. La taille du tableau est enregistrée comme celletablelivespacedu tableau et vous pouvez la diviser par lecompression ratio. Multipliez ensuite cette valeur de taille par le nombre de nœuds. Enfin, divisez par le facteur de réplication (généralement trois).Il s'agit de la formule complète de calcul que vous pouvez utiliser pour évaluer la taille de la table.
((tablelivespace / compression ratio) * (total number of nodes))/ (replication factor)Supposons que votre cluster Cassandra comporte 12 nœuds. L'exécution de la
nodetool tablestatscommande renvoie une valeurtablelivespacede 200 Go et une valeurcompression ratiode 0,5. Le keyspace possède un facteur de réplication de trois.Voici à quoi ressemble le calcul de cet exemple.
(200 GB / 0.5) * (12 nodes)/ (replication factor of 3) = 4,800 GB / 3 = 1,600 GB is the table size estimate for Amazon Keyspaces
Capturez le nombre de lectures et d'écritures
Pour déterminer les exigences de capacité et de mise à l'échelle de vos tables Amazon Keyspaces, capturez le taux de demandes de lecture et d'écriture de vos tables Cassandra avant la migration.
Amazon Keyspaces fonctionne sans serveur et vous ne payez que pour ce que vous utilisez. En général, le prix du débit de lecture/écriture dans Amazon Keyspaces est basé sur le nombre et la taille des demandes.
Amazon Keyspaces propose deux modes de capacité :
À la demande : il s'agit d'une option de facturation flexible capable de traiter des milliers de demandes par seconde sans qu'il soit nécessaire de planifier les capacités. Il propose des pay-per-request tarifs pour les demandes de lecture et d'écriture afin que vous ne payiez que pour ce que vous utilisez.
Provisionné : si vous choisissez le mode de capacité de débit provisionnée, vous spécifiez le nombre de lectures et d'écritures par seconde requis pour votre application. Cela vous permet de gérer votre utilisation d'Amazon Keyspaces afin de rester au niveau ou en dessous d'un taux de demandes défini afin de garantir la prévisibilité.
Le mode provisionné offre une mise à l'échelle automatique pour ajuster automatiquement votre taux provisionné à la hausse ou à la baisse afin d'améliorer l'efficacité opérationnelle. Pour plus d'informations sur la gestion des ressources sans serveur, consultezGestion des ressources sans serveur dans Amazon Keyspaces (pour Apache Cassandra).
Étant donné que vous allouez séparément la capacité de débit de lecture et d'écriture dans Amazon Keyspaces, vous devez mesurer le taux de demandes de lecture et d'écriture dans vos tables existantes de manière indépendante.
Pour recueillir les indicateurs d'utilisation les plus précis de votre cluster Cassandra existant, capturez le nombre moyen de demandes par seconde (RPS) pour les opérations de lecture et d'écriture au niveau du coordinateur sur une période prolongée pour une table agrégée sur tous les nœuds d'un seul centre de données.
La capture du RPS moyen sur une période d'au moins plusieurs semaines permet de saisir les pics et les creux de vos modèles de trafic, comme le montre le schéma suivant.
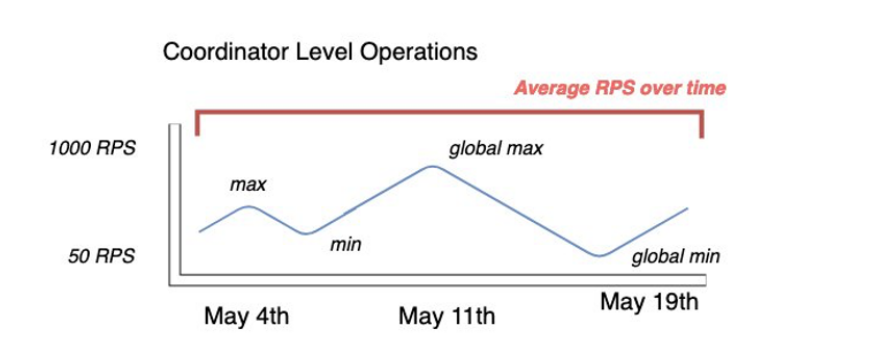
Deux options s'offrent à vous pour déterminer le taux de requêtes en lecture et en écriture de votre table Cassandra.
Utiliser la surveillance Cassandra existante
Vous pouvez utiliser les métriques présentées dans le tableau suivant pour observer les demandes de lecture et d'écriture. Notez que les noms des métriques peuvent changer en fonction de l'outil de surveillance que vous utilisez.
Dimension Métrique Cassandra JMX écrit
org.apache.cassandra.metrics:type=ClientRequest, scope=Write,name=Latency#Countlit
org.apache.cassandra.metrics:type=ClientRequest, scope=Read,name=Latency#CountUtilisation de la
nodetoolUtilisez
nodetool tablestatsetnodetool infopour capturer les opérations de lecture et d'écriture moyennes à partir de la table.tablestatsrenvoie le nombre total de lectures et d'écritures depuis le moment où le nœud a été initié.nodetool infofournit le temps de disponibilité d'un nœud en secondes.Pour obtenir la moyenne des lectures et des écritures par seconde, divisez le nombre de lectures et d'écritures par le temps de disponibilité du nœud en secondes. Ensuite, pour les lectures, vous divisez par le niveau de cohérence et pour les écritures, vous divisez par le facteur de réplication. Ces calculs sont exprimés dans les formules suivantes.
Formule pour le nombre moyen de lectures par seconde :
((number of reads * number of nodes in cluster) / read consistency quorum (2)) / uptimeFormule pour le nombre moyen d'écritures par seconde :
((number of writes * number of nodes in cluster) / replication factor of 3) / uptimeSupposons que nous ayons un cluster de 12 nœuds actif depuis 4 semaines.
nodetool inforenvoie 2 419 200 secondes de disponibilité etnodetool tablestatsrenvoie 1 milliard d'écritures et 2 milliards de lectures. Cet exemple entraînerait le calcul suivant.((2 billion reads * 12 in cluster) / read consistency quorum (2)) / 2,419,200 seconds = 12 billion reads / 2,419,200 seconds = 4,960 read request per second ((1 billion writes * 12 in cluster) / replication factor of 3) / 2,419,200 seconds = 4 billion writes / 2,419,200 seconds = 1,653 write request per second
Déterminer l'utilisation de la capacité de la table
Pour estimer l'utilisation moyenne de la capacité, commencez par les taux de demandes moyens et la taille moyenne des lignes de votre table source Cassandra.
Amazon Keyspaces utilise des unités de capacité de lecture (RCUs) et des unités de capacité d'écriture (WCUs) pour mesurer la capacité de débit allouée pour les lectures et les écritures pour les tables. Pour cette estimation, nous utilisons ces unités pour calculer les besoins en capacité de lecture et d'écriture de la nouvelle table Amazon Keyspaces après la migration.
Plus loin dans cette rubrique, nous verrons comment le choix entre le mode de capacité provisionnée et le mode de capacité à la demande affecte la facturation. Mais pour l'estimation de l'utilisation de la capacité dans cet exemple, nous supposons que la table est en mode provisionné.
LOCAL_QUORUMLectures — Une RCU représente une ou deux demandes deLOCAL_ONElecture pour une ligne d'une taille maximale de 4 Ko. Si vous devez lire une ligne de plus de 4 Ko, l'opération de lecture utilise des éléments supplémentaires RCUs. Le nombre total de lignes RCUs requises dépend de la taille de la ligne et de la cohérence que vous souhaitez utiliserLOCAL_QUORUMouLOCAL_ONElire.Par exemple, la lecture d'une ligne de 8 Ko nécessite 2 lignes RCUs utilisant la cohérence de
LOCAL_QUORUMlecture et 1 RCU si vous choisissez la cohérence deLOCAL_ONElecture.Écritures — Une WCU représente une écriture pour une ligne d'une taille maximale de 1 Ko. Toutes les écritures utilisent
LOCAL_QUORUMla cohérence, et l'utilisation de transactions légères (LWTs) est gratuite.Le nombre total de lignes WCUs requises dépend de la taille de la ligne. Si vous devez écrire une ligne supérieure à 1 Ko, l'opération d'écriture utilise des éléments supplémentaires WCUs. Par exemple, si la taille de votre ligne est de 2 Ko, vous en avez besoin WCUs de 2 pour exécuter une demande d'écriture.
La formule suivante peut être utilisée pour estimer les valeurs requises RCUs et WCUs.
La capacité de lecture RCUs peut être déterminée en multipliant les lectures par seconde par le nombre de lignes lues par lecture multiplié par la taille moyenne des lignes divisée par 4 Ko et arrondie au nombre entier le plus proche.
La capacité d'écriture WCUs peut être déterminée en multipliant le nombre de demandes par la taille moyenne des lignes divisée par 1 Ko et arrondie au nombre entier le plus proche.
Cela s'exprime dans les formules suivantes.
Read requests per second * ROUNDUP((Average Row Size)/4096 per unit) = RCUs per second Write requests per second * ROUNDUP(Average Row Size/1024 per unit) = WCUs per secondPar exemple, si vous effectuez 4 960 demandes de lecture avec une taille de ligne de 2,5 Ko sur votre table Cassandra, vous en avez besoin de 4 960 dans RCUs Amazon Keyspaces. Si vous effectuez actuellement 1 653 demandes d'écriture par seconde avec une taille de ligne de 2,5 Ko sur votre table Cassandra, vous en avez besoin de 4 959 par seconde WCUs dans Amazon Keyspaces.
Cet exemple est exprimé dans les formules suivantes.
4,960 read requests per second * ROUNDUP( 2.5KB /4KB bytes per unit) = 4,960 read requests per second * 1 RCU = 4,960 RCUs 1,653 write requests per second * ROUNDUP(2.5KB/1KB per unit) = 1,653 requests per second * 3 WCUs = 4,959 WCUsL'utilisation vous
eventual consistencypermet d'économiser jusqu'à la moitié de la capacité de débit à chaque demande de lecture. Chaque lecture finalement cohérente peut consommer jusqu'à 8 Ko. Vous pouvez calculer les lectures cohérentes éventuelles en multipliant le calcul précédent par 0,5, comme indiqué dans la formule suivante.4,960 read requests per second * ROUNDUP( 2.5KB /4KB per unit) * .5 = 2,480 read request per second * 1 RCU = 2,480 RCUs-
Calculez l'estimation du prix mensuel pour Amazon Keyspaces
Pour estimer la facturation mensuelle de la table en fonction du débit de capacité de lecture/écriture, vous pouvez calculer le prix pour le mode à la demande et pour le mode provisionné à l'aide de différentes formules et comparer les options pour votre table.
Mode provisionné — La consommation de capacité de lecture et d'écriture est facturée selon un taux horaire basé sur les unités de capacité par seconde. Divisez d'abord ce taux par 0,7 pour représenter l'utilisation cible de 70 % par défaut de l'autoscaling. Multipliez ensuite par 30 jours calendaires, 24 heures par jour, et par le tarif régional.
Ce calcul est résumé dans les formules suivantes.
(read capacity per second / .7) * 24 hours * 30 days * regional rate (write capacity per second / .7) * 24 hours * 30 days * regional rateMode à la demande — La capacité de lecture et d'écriture est facturée au tarif par demande. Tout d'abord, multipliez le taux de demandes par 30 jours civils et 24 heures par jour. Divisez ensuite par un million d'unités de demande. Enfin, multipliez par le taux régional.
Ce calcul est résumé dans les formules suivantes.
((read capacity per second * 30 * 24 * 60 * 60) / 1 Million read request units) * regional rate ((write capacity per second * 30 * 24 * 60 * 60) / 1 Million write request units) * regional rate
Choisissez une stratégie de migration
Vous pouvez choisir entre les stratégies de migration suivantes lors de la migration d'Apache Cassandra vers Amazon Keyspaces :
En ligne — Il s'agit d'une migration en direct utilisant deux écritures pour commencer à écrire simultanément de nouvelles données sur Amazon Keyspaces et le cluster Cassandra. Ce type de migration est recommandé pour les applications qui ne nécessitent aucun temps d'arrêt pendant la migration et qui nécessitent une cohérence entre les opérations de lecture après écriture.
Pour plus d'informations sur la planification et la mise en œuvre d'une stratégie de migration en ligne, consultezMigration en ligne vers Amazon Keyspaces : stratégies et meilleures pratiques.
Hors ligne : cette technique de migration consiste à copier un ensemble de données de Cassandra vers Amazon Keyspaces pendant une période d'indisponibilité. La migration hors ligne peut simplifier le processus de migration, car elle ne nécessite pas de modifications de votre application ni de résolution de conflit entre les données historiques et les nouvelles écritures.
Pour plus d'informations sur la planification d'une migration hors ligne, consultezProcessus de migration hors ligne : Apache Cassandra vers Amazon Keyspaces.
Hybride : cette technique de migration permet de répliquer les modifications sur Amazon Keyspaces quasiment en temps réel, mais sans cohérence entre les lectures et les écritures.
Pour plus d'informations sur la planification d'une migration hybride, consultezUtilisation d'une solution de migration hybride : Apache Cassandra vers Amazon Keyspaces.
Après avoir examiné les techniques de migration et les meilleures pratiques abordées dans cette rubrique, vous pouvez placer les options disponibles dans un arbre de décision afin de concevoir une stratégie de migration basée sur vos besoins et les ressources disponibles.
