Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fonctions supplémentaires de Lambda
Lambda fournit une console de gestion et une API pour la gestion et l'invocation de fonctions. Il fournit des environnements d'exécution qui prennent en charge un ensemble standard de fonctionnalités, lesquelles vous permettent de passer facilement d'un langage à l'autre et d'une infrastructure à une autre en fonction de vos besoins. Outre les fonctions, vous pouvez également créer des versions, des alias, des couches et des environnements d'exécution personnalisés.
Fonctionnalités avancées
Mise à l'échelle
Lambda gère l'infrastructure qui exécute votre code et se dimensionne automatiquement en fonction des demandes entrantes. Lorsque la fréquence d'invocation de votre fonction dépasse la capacité de traitement d'une instance de votre fonction, Lambda augmente l'échelle en exécutant des instances supplémentaires. Lorsque le trafic diminue, les instances inactives sont bloquées ou arrêtées. Vous payez uniquement pour la durée pendant laquelle votre fonction s'initialise ou traite des événements.
Pour plus d’informations, consultez Mise à l’échelle de fonction Lambda.
Contrôles de simultanéité
Utilisez les paramètres de simultanéité pour vous assurer que vos applications de production sont hautement disponibles et hautement réactives.
Pour empêcher une fonction d'utiliser trop de simultanéité et réserver une partie de la simultanéité de votre compte disponible pour une fonction, utilisez la simultanéité réservée. La simultanéité réservée divise la simultanéité disponible en sous-ensembles. Une fonction avec simultanéité réservée utilise uniquement la simultanéité du sous-ensemble qui lui est dédié.
Pour permettre l'évolutivité des fonctions sans fluctuation de latence, utilisez la simultanéité provisionnée. Pour les fonctions dont l'initialisation prend longtemps ou qui nécessitent une latence extrêmement faible pour toutes les invocations, la simultanéité allouée vous permet de pré-initialiser les instances de votre fonction et d'en maintenir l'exécution à tout moment. Lambda s'intègre avec Application Auto Scaling pour prendre en charge la mise à l'échelle automatique pour la simultanéité approvisionnée en fonction de l'utilisation.
Pour plus d’informations, consultez Configuration de la simultanéité réservée.
URL de fonctions
Lambda offre une prise en charge des points de terminaison HTTP(S) intégrée via les URL de fonctions. Avec les URL de fonctions, vous pouvez attribuer un point de terminaison HTTP dédié à une fonction Lambda. Lorsque l'URL d'une fonction est configurée, vous pouvez l'utiliser pour invoquer cette fonction via un navigateur web, curl, Postman ou n'importe quel client HTTP.
Vous pouvez ajouter une URL de fonction à une fonction existante ou créer une nouvelle fonction avec une URL de fonction. Pour plus d'informations, consultez Invocation d’URL de fonctions Lambda.
Invocation asynchrone
Lorsque vous invoquez une fonction, vous pouvez choisir de le faire de façon synchrone ou asynchrone. Avec une invocation synchrone, vous attendez de la fonction qu'elle traite l'événement et renvoie une réponse. Avec l'invocation asynchrone, Lambda place en file d'attente l'événement à traiter, et renvoie une réponse immédiatement.

Pour les invocations asynchrones, Lambda gère les nouvelles tentatives si la fonction renvoie une erreur ou si elle est limitée. Pour personnaliser ce comportement, vous pouvez configurer les paramètres de gestion des erreurs sur une fonction, une version ou un alias. Vous pouvez également configurer Lambda pour envoyer des événements dont le traitement a échoué vers une file d'attente de lettres mortes ou pour envoyer un enregistrement de chaque invocation à une destination.
Pour plus d'informations, consultez Invocation asynchrone.
Mappages de source d'événement
Afin de traiter les éléments à partir d'un flux ou d'une file d'attente, vous pouvez créer un mappage de source d'événement. Un mappage de source d'événement est une ressource dans Lambda qui lit les éléments d'une file d'attente Amazon Simple Queue Service (Amazon SQS), d'un flux Amazon Kinesis ou d'un flux Amazon DynamoDB, et les envoie à votre fonction par lots. Chaque événement traité par votre fonction peut contenir des centaines ou des milliers d'éléments.
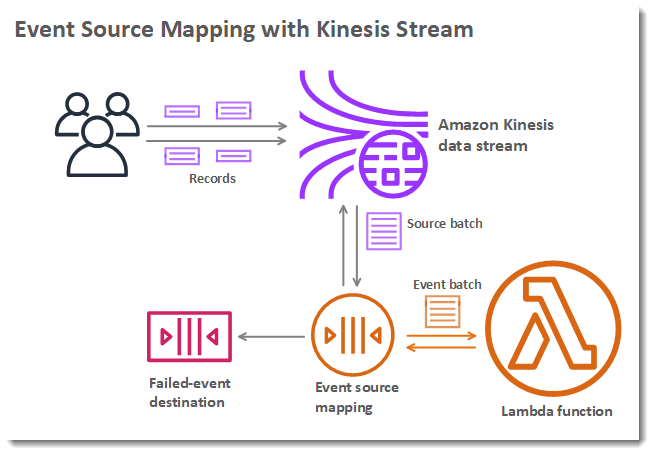
Les mappages de source d'événement gèrent une file d'attente locale d'éléments non traités, ainsi que les nouvelles tentatives si la fonction renvoie une erreur ou est limitée. Vous pouvez configurer un mappage de source d'événement pour personnaliser le comportement de traitement par lots et la gestion des erreurs, ou pour envoyer un enregistrement d'éléments dont le traitement échoue vers une destination.
Pour plus d'informations, consultez Mappage de source d’événement Lambda.
Destinations
Une destination est une ressource AWS qui reçoit des enregistrements d'invocation pour une fonction. Pour les invocations asynchrones, vous pouvez configurer Lambda afin d'envoyer des enregistrements d'invocation à une file d'attente, à une rubrique, à une fonction ou à un bus d'événements. Vous pouvez configurer des destinations distinctes pour les invocations réussies et les événements dont le traitement a échoué. L'enregistrement de l'invocation contient des détails sur l'événement, la réponse à la fonction et la raison pour laquelle l'enregistrement a été envoyé.

Pour les mappages de source d'événement lus à partir de flux, vous pouvez configurer Lambda pour envoyer un enregistrement des lots dont le traitement a échoué vers une file d'attente ou une rubrique. Un enregistrement d'échec pour un mappage de source d'événement contient des métadonnées sur le lot et pointe vers les éléments du flux.
Pour de plus amples informations, consultez Configuration des destinations pour les invocations asynchrones, ainsi que les sections relatives à la gestion des erreurs de Utilisation d’AWS Lambda avec Amazon DynamoDB et de Utilisation AWS Lambda avec Amazon Kinesis.
Plans de fonction
Lorsque vous créez une fonction dans la console Lambda, vous pouvez choisir de commencer à partir de rien, d'utiliser un plan, ou d'utiliser une image conteneur. Un plan fournit un exemple de code qui montre comment utiliser Lambda avec un service AWS ou une application tierce populaire. Les plans incluent des exemples de code et des préréglages de configuration de fonction pour les environnements d'exécution Node.js et Python.
Les plans sont fournis pour une utilisation sous la licence logicielle Amazon
Outils de test et de déploiement
Lambda prend en charge le déploiement de code tel quel ou sous la forme d'images conteneurs. Vous pouvez utiliser des outils et services populaires de la communauté AWS, tels que l’interface de ligne de commande Docker (CLI), pour la conception, la création et le déploiement de vos fonctions Lambda. Pour configurer l'interface de ligne de commande Docker, consultez Obtenir un Docker
L'AWS CLI et la CLI AWS SAM sont des outils de ligne de commande pour la gestion des piles d'applications Lambda. En plus des commandes pour la gestion des piles d'applications avec l'API AWS CloudFormation, l'AWS CLI prend en charge des commandes de plus haut niveau qui simplifient les tâches telles que le chargement de packages de déploiement et la mise à jour de modèles. L'interface de ligne de commande AWS SAM fournit des fonctionnalités supplémentaires comprenant la validation des modèle, les tests locaux et l'intégration avec les systèmes CI/CD.
Modèles d'application
Vous pouvez utiliser la console Lambda pour créer une application avec un pipeline de livraison continue. Les modèles d'application de la console Lambda incluent du code pour une ou plusieurs fonctions, un modèle d'application qui définit les fonctions et les ressources AWS associées, et un modèle d'infrastructure qui définit un pipeline AWS CodePipeline. Le pipeline comprend des étapes de construction et de déploiement qui s'exécutent chaque fois que vous poussez des modifications dans le référentiel Git inclus.
Les modèles d'application sont fournis pour une utilisation sous la licence MIT No Attribution
Pour plus d'informations, consultez Création d’une application avec diffusion continue dans la console Lambda.
