Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mise à l’échelle de fonction Lambda
La simultanéité est le nombre de demandes en cours d’exécution que votre fonction AWS Lambda traite en même temps. Pour chaque demande simultanée, Lambda fournit une instance distincte de votre environnement d’exécution. Au fur et à mesure que vos fonctions reçoivent des demandes, Lambda gère automatiquement la mise à l’échelle du nombre d’environnements d’exécution jusqu’à ce que vous atteigniez la limite de simultanéité de votre compte. Par défaut, Lambda fournit à votre compte une limite de simultanéité totale de 1 000 exécutions simultanées pour toutes les fonctions d’une Région AWS. Pour répondre aux besoins spécifiques de votre compte, vous pouvez demander une augmentation du quota
Cette rubrique explique la simultanéité et la mise à l’échelle horizontale des fonctions dans Lambda. À la fin de cette rubrique, vous serez en mesure de comprendre comment calculer la simultanéité, de visualiser les deux principales options de contrôle de la simultanéité (réservée et provisionnée), d’estimer les paramètres de contrôle de la simultanéité appropriés et de visualiser les métriques pour une optimisation supplémentaire.
Sections
- Comprendre et visualiser la simultanéité
- Calcul de la simultanéité
- Simultanéité et demandes par seconde
- Simultanéité réservée et simultanéité provisionnée
- Quotas de simultanéité
- Configuration de la simultanéité réservée
- Configuration de la simultanéité provisionnée
- Comportement de mise à l’échelle Lambda
- Surveillance de la simultanéité
Comprendre et visualiser la simultanéité
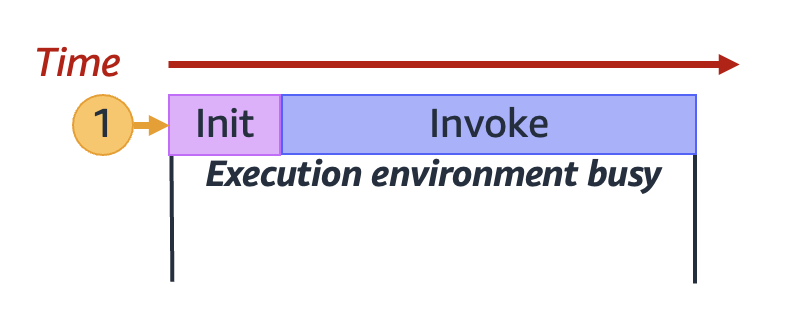
Lambda invoque votre fonction dans un environnement d’exécution sécurisé et isolé. Pour traiter une demande, Lambda doit d’abord initialiser un environnement d’exécution (la phase Init), avant de l’utiliser pour invoquer votre fonction (la phase Invoke) :
Note
Les durées réelles d’Init et Invoke peuvent varier en fonction de nombreux facteurs, tels que l’environnement d’exécution choisi et le code de la fonction Lambda. Le diagramme précédent n’est pas censé représenter les proportions exactes des durées des phases Init et Invoke.
Le diagramme précédent utilise un rectangle pour représenter un seul environnement d’exécution. Lorsque votre fonction reçoit sa toute première demande (représentée par le cercle jaune avec l’étiquette 1), Lambda crée un nouvel environnement d’exécution et exécute le code en dehors de votre gestionnaire principal pendant la phase Init. Ensuite, Lambda exécute le code du gestionnaire principal de votre fonction pendant la phase Invoke. Pendant tout ce processus, cet environnement d’exécution est occupé et ne peut pas traiter d’autres demandes.
Lorsque Lambda a fini de traiter la première demande, cet environnement d’exécution peut alors traiter des demandes supplémentaires pour la même fonction. Pour les demandes suivantes, Lambda n’a pas besoin de réinitialiser l’environnement.
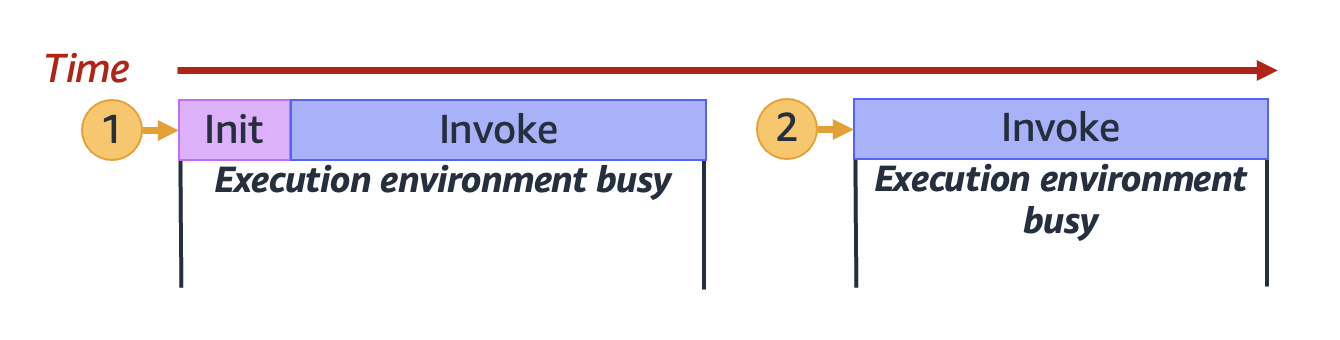
Dans le schéma précédent, Lambda réutilise l’environnement d’exécution pour traiter la deuxième demande (représentée par le cercle jaune avec l’étiquette 2).
Jusqu’à présent, nous nous sommes concentrés sur une seule instance de votre environnement d’exécution (c.-à-d. une simultanéité de 1). En pratique, Lambda peut avoir besoin de provisionner plusieurs instances d’environnement d’exécution en parallèle pour traiter toutes les demandes entrantes. Lorsque votre fonction reçoit une nouvelle demande, l’une des deux choses suivantes peut se produire :
-
Si une instance d’environnement d’exécution pré-initialisée est disponible, Lambda l’utilise pour traiter la demande.
-
Sinon, Lambda crée une nouvelle instance d’environnement d’exécution pour traiter la demande.
Par exemple, explorons ce qui se passe lorsque votre fonction reçoit 10 demandes :
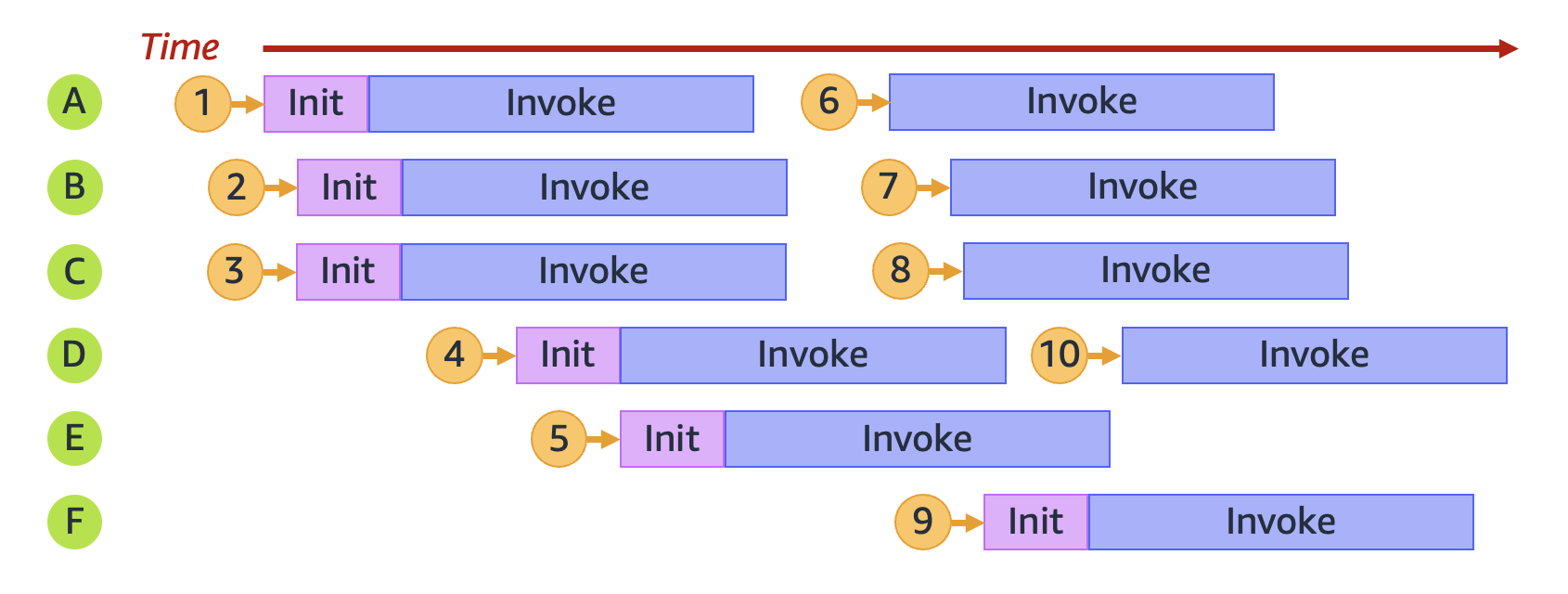
Dans le diagramme précédent, chaque plan horizontal représente une seule instance d’environnement d’exécution (étiquetée de A à F). Voici comment Lambda traite chaque demande :
Comportement de Lambda pour les demandes 1 à 10 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Demande | Comportement de Lambda | Raisonnement | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1 |
Alloue un nouvel environnement A |
C’est la première demande ; aucune instance d’environnement d’exécution n’est disponible. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 |
Alloue un nouvel environnement B |
L’instance A de l’environnement d’exécution existant est occupée. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3 |
Alloue un nouvel environnement C |
Les instances d’environnement d’exécution existantes A et B sont toutes deux occupées. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4 |
Alloue un nouvel environnement D |
Les instances d’environnement d’exécution existantes A, B et C sont toutes occupées. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
5 |
Alloue un nouvel environnement E |
Les instances A, B, C et D de l’environnement d’exécution existant sont toutes occupées. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6 |
Réutilise l’environnement A |
L’instance d’environnement d’exécution A a fini de traiter la demande 1 et est maintenant disponible. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
7 |
Réutilise l’environnement B |
L’instance d’environnement d’exécution B a fini de traiter la demande 2 et est maintenant disponible. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
8 |
Réutilise l’environnement C |
L’instance d’environnement d’exécution C a terminé le traitement de la demande 3 et est maintenant disponible. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
9 |
Alloue un nouvel environnement F |
Les instances d’environnement d’exécution existantes A, B, C, D et E sont toutes occupées. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
10 |
Réutilise l’environnement D |
L’instance d’environnement d’exécution D a fini de traiter la demande 4 et est maintenant disponible. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Au fur et à mesure que votre fonction reçoit des demandes simultanées, Lambda augmente le nombre d’instances d’environnement d’exécution en réponse. L’animation suivante suit le nombre de demandes simultanées dans le temps :
En figeant l’animation précédente à six points distincts dans le temps, nous obtenons le diagramme suivant :
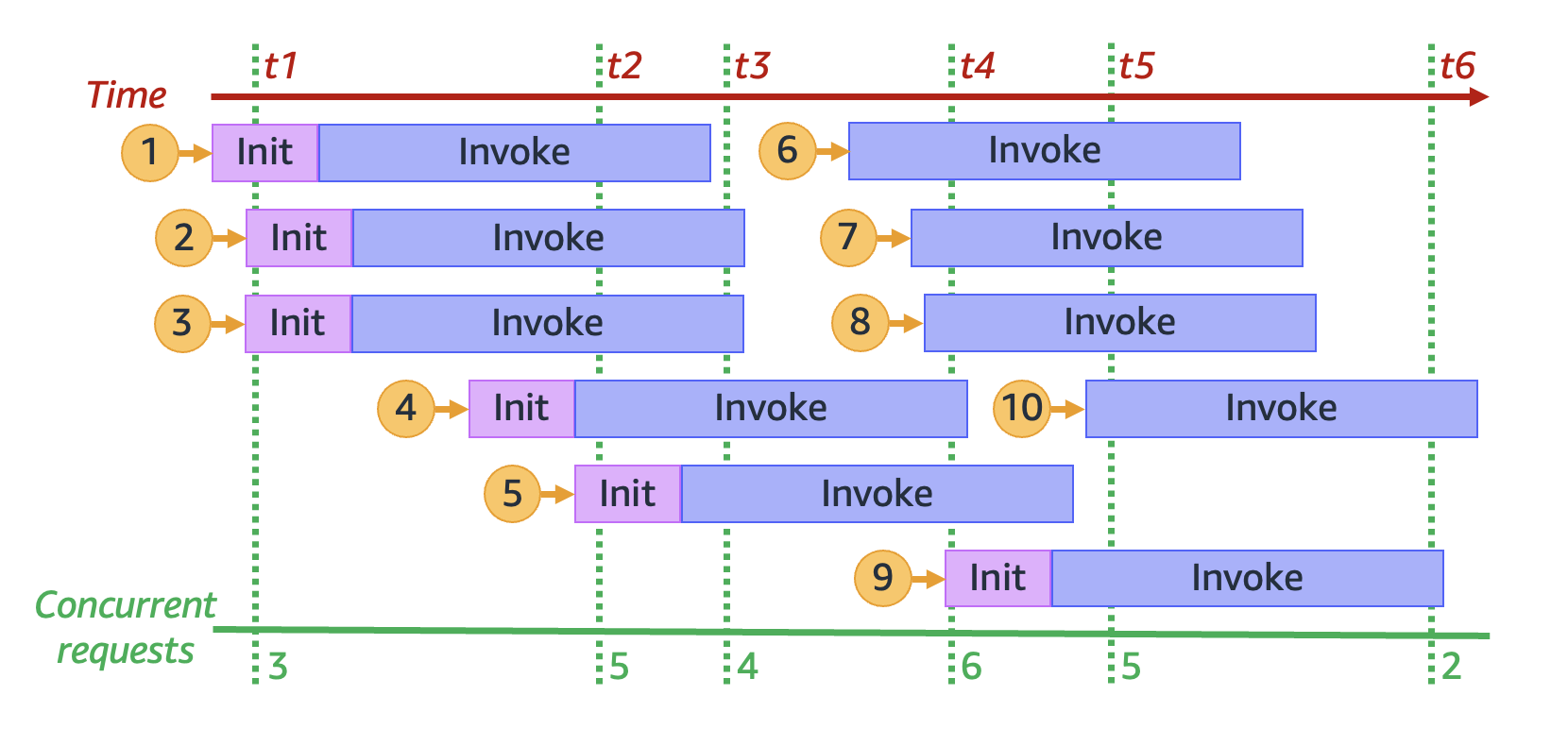
Dans le diagramme précédent, nous pouvons tracer une ligne verticale à tout moment et compter le nombre d’environnements qui croisent cette ligne. Cela nous donne le nombre de demandes simultanées à ce moment précis. Par exemple, au moment t1, il y a trois environnements actifs servant trois demandes simultanées. Le nombre maximum de demandes simultanées dans cette simulation se produit au moment t4, lorsqu’il y a six environnements actifs servant six demandes simultanées.
En résumé, la simultanéité de votre fonction est le nombre de demandes simultanées qu’elle traite en même temps. En réponse à une augmentation de la simultanéité de votre fonction, Lambda fournit plus d’instances d’environnement d’exécution pour répondre à la demande.
Calcul de la simultanéité
En général, la simultanéité d’un système est la capacité de traiter plus d’une tâche simultanément. Dans Lambda, la simultanéité est le nombre de demandes en vol que votre fonction traite en même temps. Une façon rapide et pratique de mesurer la simultanéité d’une fonction Lambda est d’utiliser la formule suivante :
Concurrency = (average requests per second) * (average request duration in seconds)
La simultanéité diffère des demandes par seconde. Par exemple, supposons que votre fonction reçoive 100 demandes par seconde en moyenne. Si la durée moyenne des demandes est de une seconde, il est vrai que la simultanéité est également de 100 :
Concurrency = (100 requests/second) * (1 second/request) = 100
Toutefois, si la durée moyenne des demandes est de 500 ms, la simultanéité est de 50 :
Concurrency = (100 requests/second) * (0.5 second/request) = 50
Que signifie une simultanéité de 50 dans la pratique ? Si la durée moyenne des demandes est de 500 ms, vous pouvez considérer qu’une instance de votre fonction est capable de traiter deux demandes par seconde. Ensuite, il faut 50 instances de votre fonction pour gérer une charge de 100 demandes par seconde. Une simultanéité de 50 signifie que Lambda doit fournir 50 instances d’environnement d’exécution pour gérer efficacement cette charge de travail sans être limité. Voici comment exprimer cela sous forme d’équation :
Concurrency = (100 requests/second) / (2 requests/second) = 50
Si votre fonction reçoit le double de demandes (200 demandes par seconde), mais ne nécessite que la moitié du temps pour traiter chaque demande (250 ms), la simultanéité est toujours de 50 :
Concurrency = (200 requests/second) * (0.25 second/request) = 50
Supposons que vous ayez une fonction qui prend, en moyenne, 200 ms pour s’exécuter. Pendant les pics de charge, vous observez 5 000 demandes par seconde. Quelle est la simultanéité de votre fonction pendant la charge de pointe ?
La durée moyenne de la fonction est de 200 ms, soit 0,20 seconde. En utilisant la formule de simultanéité, vous pouvez entrer les chiffres pour obtenir une simultanéité de 1000 :
Concurrency = (5,000 requests/second) * (0.2 seconds/request) = 1,000
Autrement dit, une durée moyenne de fonction de 200 ms signifie que votre fonction peut traiter 5 demandes par seconde. Pour traiter la charge de travail de 5 000 demandes par seconde, vous avez besoin de 1 000 instances d’environnement d’exécution. La simultanéité est donc de 1 000 :
Concurrency = (5,000 requests/second) / (5 requests/second) = 1,000
Simultanéité et demandes par seconde
Comme indiqué dans la section précédente, la simultanéité diffère des demandes par seconde. Cette distinction est particulièrement importante lorsque l’on travaille avec des fonctions dont la durée moyenne des requêtes est inférieure à 100 ms.
En général, chaque instance de votre environnement d’exécution peut gérer au maximum 10 demandes par seconde. Cette limite s’applique aux fonctions synchrones à la demande, ainsi qu’aux fonctions qui utilisent la simultanéité provisionnée. Si vous ne connaissez pas cette limitation, vous ne savez peut-être pas pourquoi de telles fonctions peuvent être limitées dans certains scénarios.
Prenons l’exemple d’une fonction dont la durée moyenne des demandes est de 50 ms. À raison de 200 demandes par seconde, voici la simultanéité de cette fonction :
Concurrency = (200 requests/second) * (0.05 second/request) = 10
Sur la base de ce résultat, vous pouvez vous attendre à n’avoir besoin que de 10 instances d’environnement d’exécution pour gérer cette charge. Toutefois, chaque environnement d’exécution ne peut gérer que 10 exécutions par seconde. Cela signifie qu’avec 10 environnements d’exécution, votre fonction ne peut traiter que 100 demandes par seconde sur un total de 200 demandes. Cette fonction est soumise à une limitation.
La leçon à tirer est que vous devez tenir compte à la fois de la simultanéité et des demandes par seconde lorsque vous configurez les paramètres de simultanéité pour vos fonctions. Dans ce cas, vous avez besoin de 20 environnements d’exécution pour votre fonction, même si la simultanéité n’est que de 10.
Supposons que vous ayez une fonction qui prend, en moyenne, 20 ms pour s’exécuter. Pendant les pics de charge, vous observez 3 000 demandes par seconde. Quelle est la simultanéité de votre fonction pendant la charge de pointe ?
La durée moyenne de la fonction est de 20 ms, soit 0,02 seconde. En utilisant la formule de simultanéité, vous pouvez entrer les chiffres pour obtenir une simultanéité de 60 :
Concurrency = (3,000 requests/second) * (0.02 seconds/request) = 60
Toutefois, chaque environnement d’exécution ne peut gérer que 10 demandes par seconde. Avec 60 environnements d’exécution, votre fonction peut traiter un maximum de 600 demandes par seconde. Pour répondre totalement aux 3 000 demandes, votre fonction a besoin d’au moins 300 instances d’environnement d’exécution.
Simultanéité réservée et simultanéité provisionnée
Par défaut, votre compte dispose d’une limite de simultanéité de 1 000 exécutions simultanées pour toutes les fonctions d’une Région. Vos fonctions partagent ce groupe de 1 000 simultanéités sur une base à la demande. Vos fonctions sont limitées (c.-à-d. qu’elles commencent à abandonner des demandes) si vous n’avez plus de simultanéité disponible.
Certaines de vos fonctions peuvent être plus critiques que d’autres. Par conséquent, vous pouvez vouloir configurer les paramètres de simultanéité pour vous assurer que les fonctions critiques obtiennent la simultanéité dont elles ont besoin. Il existe deux types de contrôles de simultanéité : la simultanéité réservée et la simultanéité provisionnée.
-
Utilisez la simultanéité réservée pour réserver une partie de la simultanéité de votre compte pour une fonction. Ceci est utile si vous ne voulez pas que d’autres fonctions prennent toute la simultanéité non réservée disponible.
-
Utilisez la simultanéité provisionnée pour pré-initialiser un certain nombre d’instances d’environnement pour une fonction. Ceci est utile pour réduire les latences de démarrage à froid.
Simultanéité réservée
Si vous voulez garantir qu’une certaine quantité de simultanéité est disponible pour votre fonction à tout moment, utilisez la simultanéité réservée.
La simultanéité réservée est le nombre maximum d’instances simultanées que vous voulez allouer à votre fonction. Lorsque vous consacrez une simultanéité réservée à une fonction, aucune autre fonction ne peut utiliser cette simultanéité. En d’autres termes, la définition de la simultanéité réservée peut avoir un impact sur le groupe de simultanéité disponible pour les autres fonctions. Les fonctions qui n’ont pas de simultanéité réservée partagent le groupe restant de simultanéité non réservée.
La configuration de la simultanéité réservée compte dans la limite globale de simultanéité de votre compte. Il n’y a pas de frais pour la configuration de la simultanéité réservée pour une fonction.
Pour mieux comprendre la simultanéité réservée, considérez le diagramme suivant :
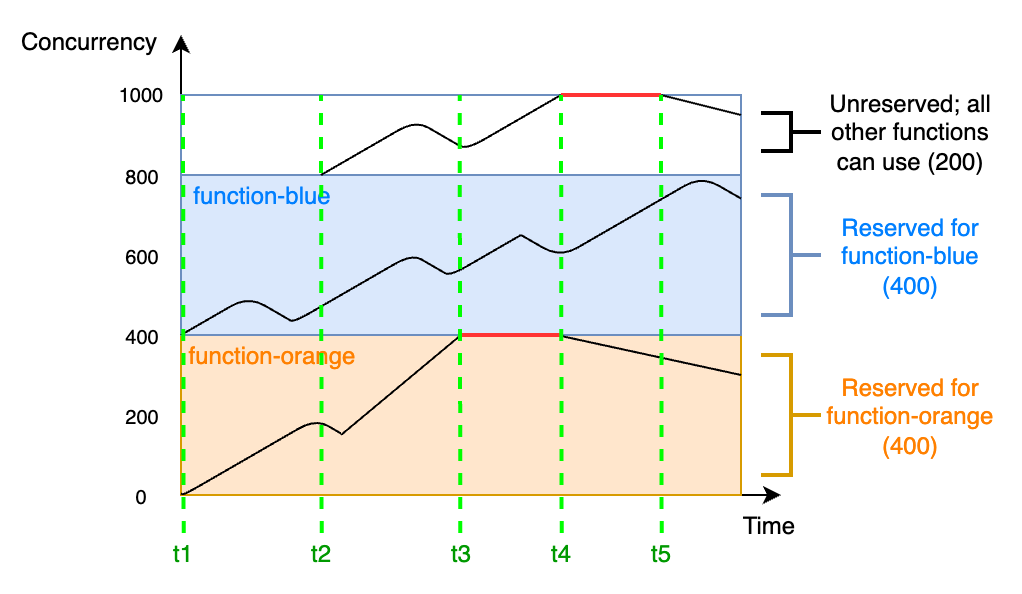
Dans ce diagramme, la limite de simultanéité de votre compte pour toutes les fonctions de cette Région est à la limite par défaut de 1 000. Supposons que vous ayez deux fonctions critiques, function-blue et function-orange, qui s’attendent régulièrement à recevoir des volumes d’invocations élevés. Vous décidez d’accorder 400 unités de simultanéité réservée à function-blue, et 400 unités de simultanéité réservée à function-orange. Dans cet exemple, toutes les autres fonctions de votre compte doivent se partager les 200 unités restantes de simultanéité non réservée.
Le diagramme présente cinq points d’intérêt :
-
À
t1,function-orangeetfunction-bluecommencent à recevoir des demandes. Chaque fonction commence à utiliser sa portion d’unités de simultanéité réservées. -
À
t2,function-orangeetfunction-bluereçoivent de plus en plus de demandes. Au même moment, vous déployez d’autres fonctions Lambda, qui commencent à recevoir des demandes. Vous n’allouez pas de simultanéité réservée à ces autres fonctions. Elles commencent à utiliser les 200 unités restantes de simultanéité non réservée. -
À
t3,function-orangeatteint la simultanéité maximale de 400. Bien qu’il existe une simultanéité non utilisée ailleurs dans le compte,function-orangene peut pas y accéder. La ligne rouge indique quefunction-orangeest limité et que Lambda peut abandonner des demandes. -
À
t4,function-orangecommence à recevoir moins de demandes et n’est plus limitée. Cependant, vos autres fonctions subissent un pic de trafic et commencent à être limitées. Bien qu’il y ait de la simultanéité inutilisée ailleurs dans votre compte, ces autres fonctions ne peuvent pas y accéder. La ligne rouge indique que vos autres fonctions sont limitées. -
À
t5, les autres fonctions commencent à recevoir moins de demandes et ne sont plus limitées.
À partir de cet exemple, remarquez que la réservation de la simultanéité a les effets suivants :
-
Votre fonction peut évoluer indépendamment des autres fonctions de votre compte. Toutes les fonctions de votre compte dans la même Région qui n’ont pas de simultanéité réservée partagent le groupe de simultanéité non réservée. Sans simultanéité réservée, d’autres fonctions peuvent utiliser toute votre simultanéité disponible. Cela empêche les fonctions critiques d’augmenter d’échelle si nécessaire.
-
Votre fonction ne peut pas monter en puissance de façon incontrôlée. La simultanéité réservée limite la simultanéité maximale de votre fonction. Cela signifie que votre fonction ne peut pas utiliser la simultanéité réservée à d’autres fonctions, ou la simultanéité du groupe non réservé. Vous pouvez réserver de la simultanéité pour empêcher votre fonction d’utiliser toute la simultanéité disponible dans votre compte, ou de surcharger les ressources en aval.
-
Il se peut que vous ne puissiez pas utiliser toute la simultanéité disponible de votre compte. La réservation de la simultanéité compte dans la limite de simultanéité de votre compte, mais cela signifie également que les autres fonctions ne peuvent pas utiliser cette partie de la simultanéité réservée. Si votre fonction n’utilise pas toute la simultanéité que vous lui réservez, vous gaspillez effectivement cette simultanéité. Ce n’est pas un problème, sauf si d’autres fonctions de votre compte peuvent bénéficier de la simultanéité gaspillée.
Pour gérer les paramètres de simultanéité réservée pour vos fonctions, consultez Configuration de la simultanéité réservée.
Simultanéité allouée
Vous utilisez la simultanéité réservée pour définir le nombre maximal d’environnements d’exécution réservés à une fonction Lambda. Toutefois, aucun de ces environnements n’est préinitialisé. Par conséquent, les invocations de votre fonction peuvent prendre plus de temps, car Lambda doit d’abord initialiser le nouvel environnement avant de pouvoir l’utiliser pour invoquer votre fonction. Lorsque Lambda doit initialiser un nouvel environnement pour effectuer une invocation , on parle de démarrage à froid. Pour atténuer les démarrages à froid, vous pouvez utiliser la simultanéité provisionnée.
La simultanéité provisionnée est le nombre d’environnements d’exécution pré-initialisés que vous voulez allouer à votre fonction. Si vous définissez la simultanéité provisionnée sur une fonction, Lambda initialise ce nombre d’environnements d’exécution afin qu’ils soient prêts à répondre immédiatement aux demandes de la fonction.
Note
L’utilisation de la simultanéité provisionnée entraîne des frais supplémentaires sur votre compte. Si vous travaillez avec les environnements d'exécution Java 11 ou Java 17, vous pouvez également utiliser SnapStart Lambda pour atténuer les problèmes de démarrage à froid sans frais supplémentaires. SnapStart utilise des instantanés mis en cache de votre environnement d'exécution pour améliorer de manière significative les performances de démarrage. Vous ne pouvez pas utiliser les deux SnapStart et la simultanéité provisionnée sur la même version de fonction. Pour plus d'informations sur les SnapStart fonctionnalités, les limitations et les régions prises en charge, consultezAméliorer les performances de démarrage avec Lambda SnapStart.
Lorsque vous utilisez la simultanéité provisionnée, Lambda recycle toujours les environnements d’exécution en arrière-plan. Cependant, à tout moment, Lambda s’assure toujours que le nombre d’environnements pré-initialisés est égal à la valeur du paramètre de simultanéité provisionnée de votre fonction. Ce comportement diffère de la simultanéité réservée, où Lambda peut résilier complètement un environnement après une période d’inactivité. Le diagramme suivant illustre cela en comparant le cycle de vie d’un environnement d’exécution unique lorsque vous configurez votre fonction en utilisant la simultanéité réservée par rapport à la simultanéité provisionnée.
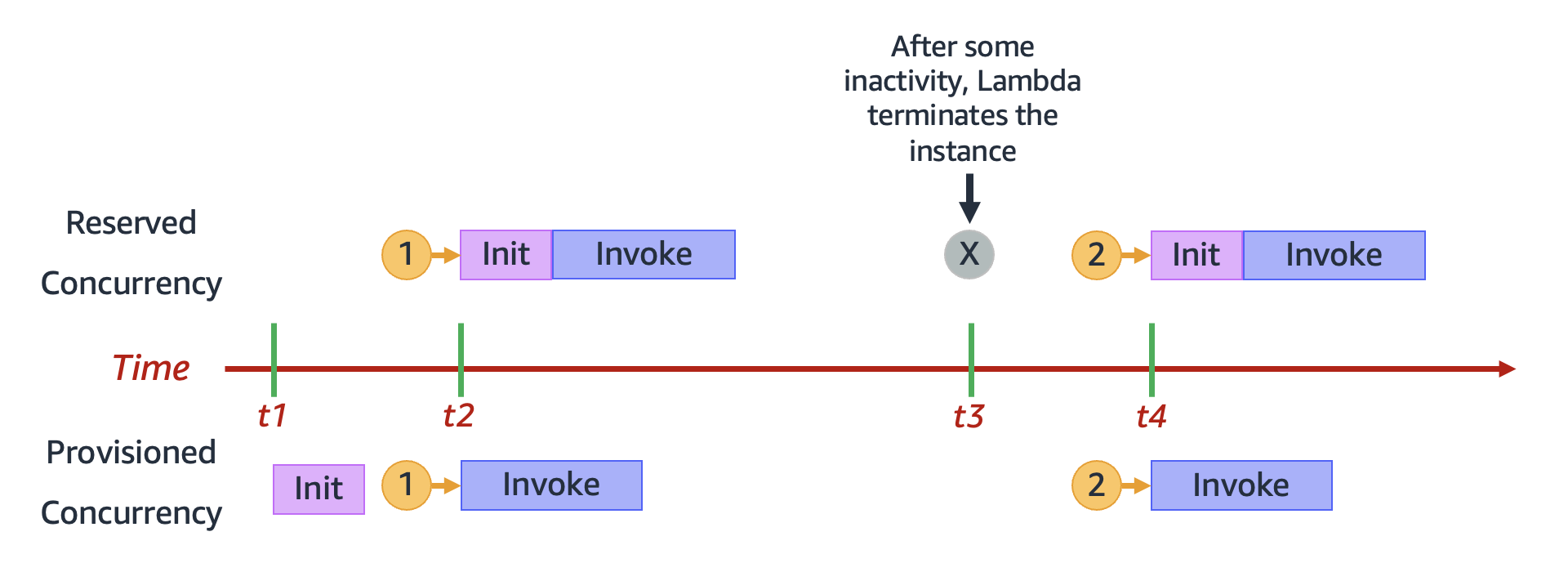
Le diagramme présente quatre points d’intérêt :
| Heure | Simultanéité réservée | Simultanéité allouée |
|---|---|---|
|
t1 |
Rien ne se passe. |
Lambda pré-initialise une instance d’environnement d’exécution. |
|
t2 |
La demande 1 arrive. Lambda doit initialiser une nouvelle instance d’environnement d’exécution. |
La demande 1 arrive. Lambda utilise l’instance d’environnement pré-initialisée. |
|
t3 |
Après un certain temps d’inactivité, Lambda met fin à l’instance d’environnement active. |
Rien ne se passe. |
|
t4 |
La demande 2 arrive. Lambda doit initialiser une nouvelle instance d’environnement d’exécution. |
La demande 2 arrive. Lambda utilise l’instance d’environnement pré-initialisée. |
Pour mieux comprendre la simultanéité provisionnée, considérez le diagramme suivant :
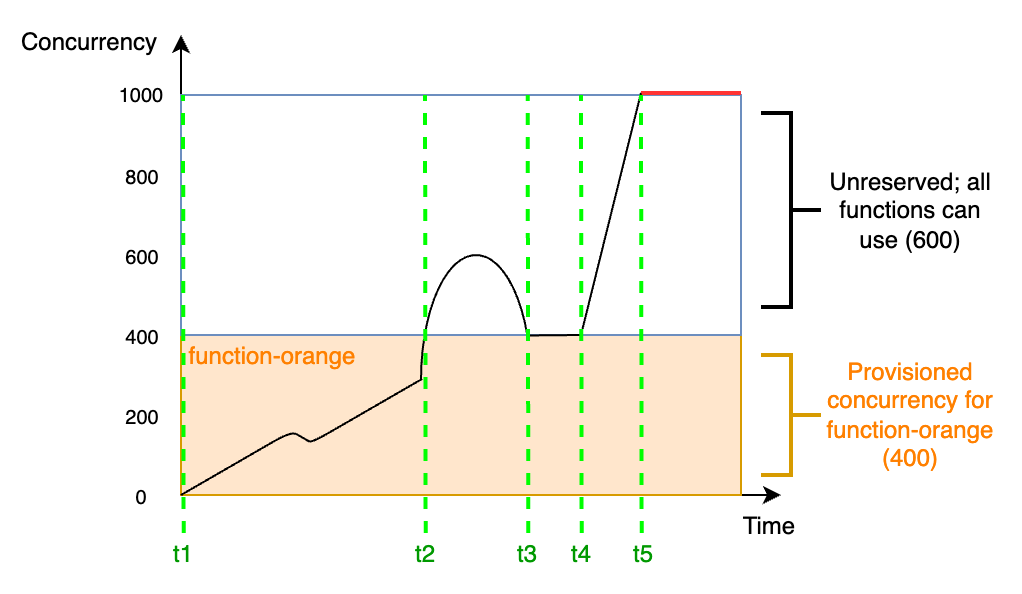
Dans ce diagramme, vous avez une limite de simultanéité de compte de 1 000. Vous décidez d’accorder 400 unités de simultanéité provisionnée à function-orange. Toutes les fonctions de votre compte, y compris function-orange, peuvent utiliser les 600 unités restantes de simultanéité non réservée.
Le diagramme présente cinq points d’intérêt :
-
À
t1,function-orangecommence à recevoir des demandes. Puisque Lambda a pré-initialisé 400 instances d’environnement d’exécution,function-orangeest prête pour une invocation immédiat. -
À
t2,function-orangeatteint 400 demandes simultanées. Par conséquent,function-orangen’a plus de simultanéité provisionnée. Cependant, comme il reste de la simultanéité non réservée, Lambda peut l’utiliser pour traiter des demandes supplémentaires versfunction-orange(il n’y a pas de limitation). Lambda doit créer de nouvelles instances pour répondre à ces demandes, et votre fonction peut subir des latences de démarrage à froid. -
À
t3,function-orangerevient à 400 demandes simultanées après un bref pic de trafic. Lambda est à nouveau capable de traiter toutes les demandes sans latence de démarrage à froid. -
À
t4, les fonctions de votre compte subissent un pic de trafic. Cette rafale peut provenir defunction-orangeou de toute autre fonction de votre compte. Lambda utilise la simultanéité sans réserve pour traiter ces demandes. -
À
t5, les fonctions de votre compte atteignent la limite maximale de simultanéité de 1 000 et sont limitées.
L’exemple précédent ne prenait en compte que la simultanéité provisionnée. En pratique, vous pouvez définir à la fois la simultanéité provisionnée et la simultanéité réservée sur une fonction. Vous pourriez le faire si vous aviez une fonction qui gère une charge constante d’invocations le week-end, mais qui connaît régulièrement des pics de trafic le week-end. Dans ce cas, vous pourriez utiliser la simultanéité provisionnée pour définir une quantité de base d’environnements pour traiter les demandes pendant les jours de la semaine, et utiliser la simultanéité réservée pour gérer les pics de trafic du week-end. Considérez le diagramme suivant :
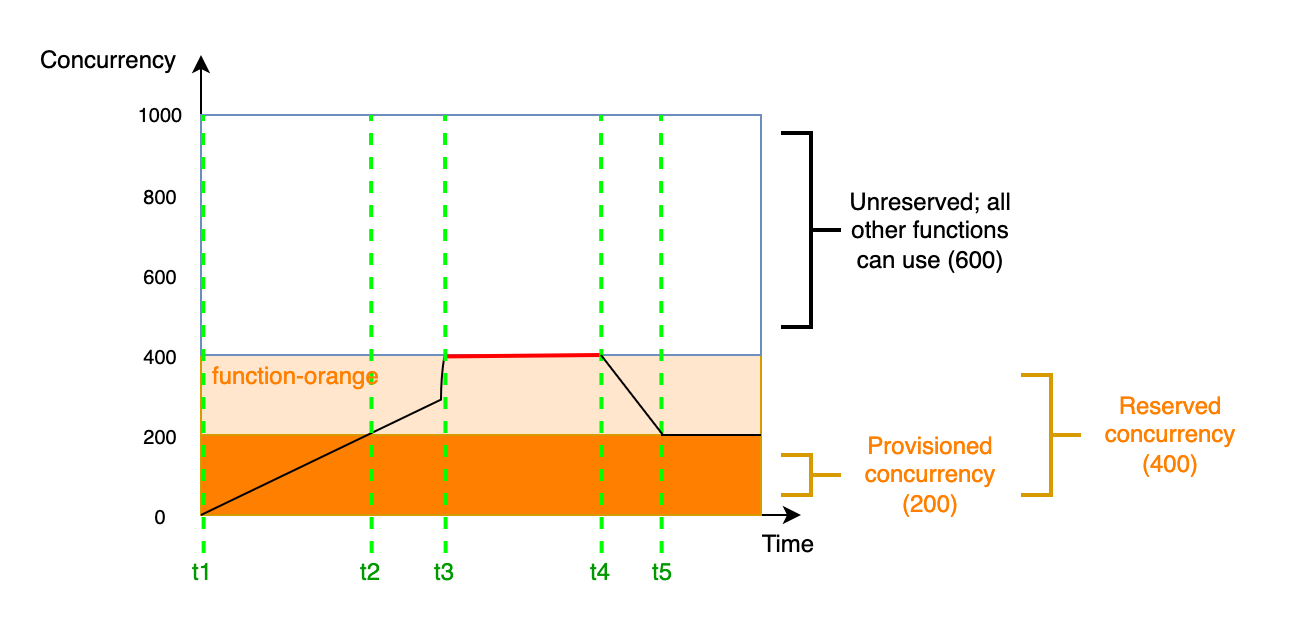
Dans ce diagramme, supposons que vous configurez 200 unités de simultanéité provisionnée et 400 unités de simultanéité réservée pour function-orange. Parce que vous avez configuré la simultanéité réservée, function-orange ne peut utiliser aucune des 600 unités de simultanéité non réservée.
Ce diagramme comporte cinq points d’intérêt :
-
À
t1,function-orangecommence à recevoir des demandes. Puisque Lambda a pré-initialisé 200 instances d’environnement d’exécution,function-orangeest prête pour une invocation immédiat. -
À
t2,function-orangeutilise toute sa simultanéité provisionnée.function-orangepeut continuer à servir les demandes en utilisant la simultanéité réservée, mais ces demandes peuvent subir des latences de démarrage à froid. -
À
t3,function-orangeatteint 400 demandes simultanées. Par conséquent,function-orangeutilise toute sa simultanéité réservée. Commefunction-orangene peut pas utiliser la simultanéité non réservée, les demandes commencent à être limitées. -
À
t4,function-orangecommence à recevoir moins de demandes et ne se limite plus. -
À
t5,function-orangetombe à 200 demandes simultanées, de sorte que toutes les demandes peuvent à nouveau utiliser la simultanéité provisionnée (c.-à-d. sans latence de démarrage à froid).
La simultanéité réservée et la simultanéité provisionnée comptent toutes deux dans la limite de simultanéité de votre compte et dans les quotas régionaux. En d’autres termes, l’allocation de la simultanéité réservée et provisionnée peut avoir un impact sur le groupe de simultanéité disponible pour les autres fonctions. La configuration de la simultanéité provisionnée entraîne des frais sur votre Compte AWS.
Note
Si la simultanéité provisionnée sur les versions et alias d’une fonction s’ajoute à la simultanéité réservée de la fonction, toutes les invocations s’exécutent sur la simultanéité provisionnée. Cette configuration a également pour effet de limiter la version non publiée de la fonction ($LATEST), ce qui empêche son exécution. Vous ne pouvez pas allouer plus de simultanéité provisionnée que de simultanéité réservée pour une fonction.
Pour gérer les paramètres de simultanéité provisionnée pour vos fonctions, consultez Configuration de la simultanéité provisionnée. Pour automatiser la mise à l’échelle de la concurrence provisionnée en fonction d’une planification ou de l’utilisation de l’application, consultez Gestion de la simultanéité provisionnée avec Application Auto Scaling..
Comment Lambda alloue la simultanéité provisionnée
La simultanéité provisionnée n’est pas mise en ligne immédiatement après la configuration. Lambda commence à allouer la simultanéité approvisionnée après une phase de préparation d’une ou deux minutes. Lambda peut notamment fournir entre 500 et 3 000 environnements d’exécution à la fois, en fonction de la Région. Après cette première rafale, Lambda alloue 500 environnements supplémentaires par minute, quelle que soit la Région, jusqu’à ce que la demande soit satisfaite.
Par exemple, supposons que la limite de simultanéité de votre compte soit de 10 000. Supposons également qu’à 10 h dans la région USA Est (Virginie du Nord), vous configuriez 5 000 unités de simultanéité provisionnée pour une fonction. Voici comment Lambda peut allouer des unités de simultanéité provisionnées :
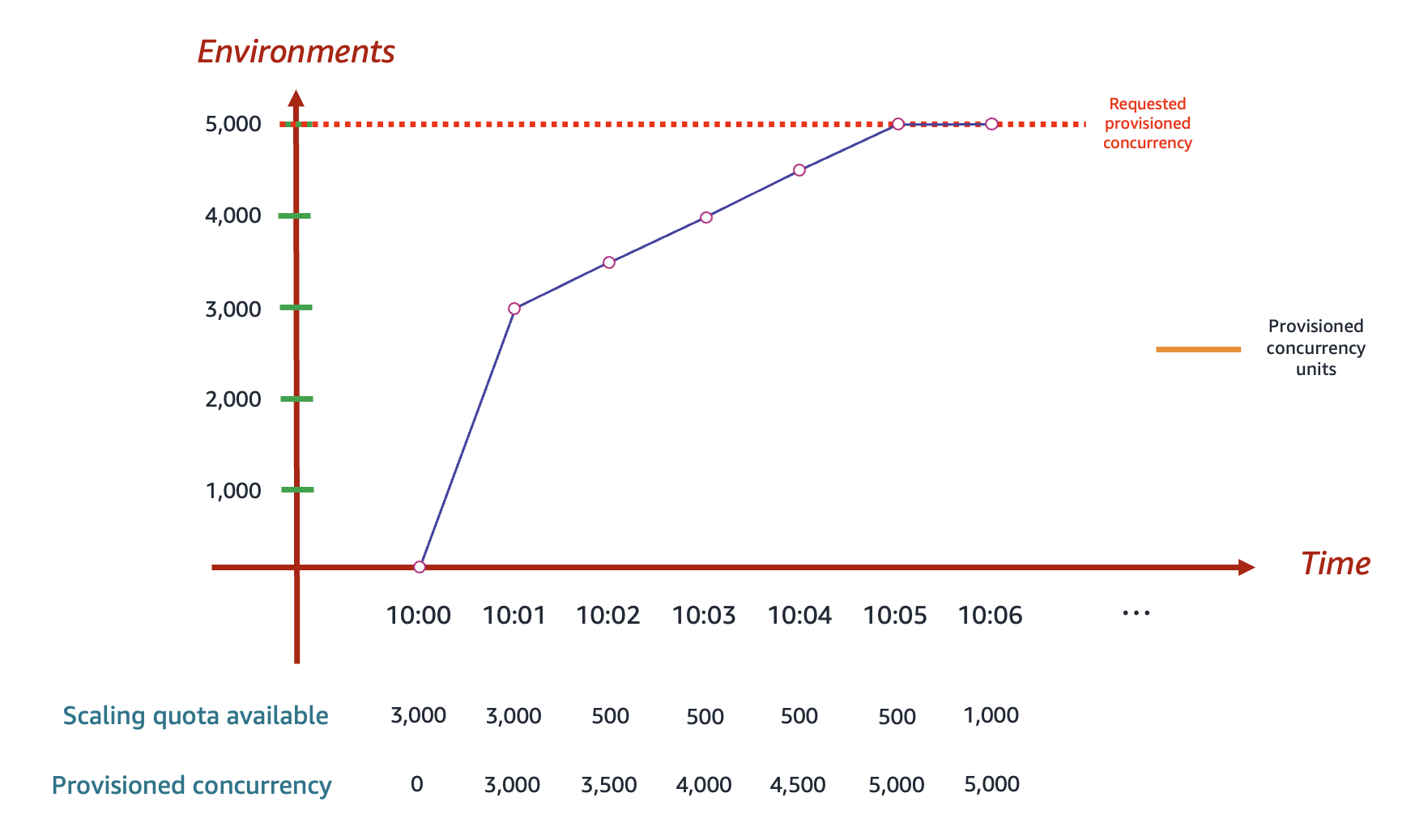
Dans le diagramme précédent :
-
Dans un premier temps, Lambda peut provisionner jusqu’à 3 000 environnements d’exécution, étant donné que la limite initiale de simultanéité en rafale dans la région USA Est (Virginie du Nord) est de 3 000.
-
À 10 h : vous demandez 5 000 unités de simultanéité provisionnées pour cette fonction. Lambda ne commence pas à provisionner les environnements d’exécution instantanément.
-
À 10 h 01 : Lambda commence par provisionner 3 000 environnements.
-
De 10 h 02 à 10 h 05 : Lambda provisionne 500 environnements supplémentaires par minute. À 10 h 05, Lambda termine d’allouer 5 000 environnements à votre fonction.
Lorsque vous soumettez une demande d’allocation de simultanéité provisionnée, vous ne pouvez accéder à aucun de ces environnements tant que Lambda n’a pas terminé de les allouer. Par exemple, dans le scénario précédent, aucune de vos demandes ne peut utiliser la simultanéité provisionnée avant 10 h 05, car c’est à ce moment-là que Lambda termine l’allocation de votre demande de 5 000 environnements d’exécution.
Comparaison de la simultanéité réservée et de la simultanéité provisionnée
Le tableau suivant résume et compare la simultanéité réservée et provisionnée.
| Rubrique | Simultanéité réservée | Simultanéité allouée |
|---|---|---|
|
Définition |
Nombre maximal d’instances d’environnement d’exécution pour votre fonction. |
Nombre défini d’instances d’environnement d’exécution pré-provisionnées pour votre fonction. |
|
Comportement de provisionnement |
Lambda provisionne de nouvelles instances sur une base à la demande. |
Lambda pré-provisionne les instances (c.-à-d. avant que votre fonction ne commence à recevoir des demandes). |
|
Comportement de démarrage à froid |
Latence de démarrage à froid possible, puisque Lambda doit créer de nouvelles instances à la demande. |
Latence de démarrage à froid impossible, puisque Lambda ne doit pas créer d’instances à la demande. |
|
Comportement de limitation |
La fonction est limitée lorsque la limite de simultanéité réservée est atteinte. |
Si la simultanéité réservée n’est pas définie : la fonction utilise la simultanéité non réservée lorsque la limite de simultanéité provisionnée est atteinte. Si la simultanéité réservée est définie : la fonction est limitée lorsque la limite de simultanéité réservée est atteinte. |
|
Comportement par défaut si non défini |
La fonction utilise la simultanéité non réservée disponible dans votre compte. |
Lambda ne pré-provisionne pas d’instances. Au lieu de cela, si la simultanéité réservée n’est pas définie : la fonction utilise la simultanéité non réservée disponible dans votre compte. Si la simultanéité réservée est définie : la fonction utilise la simultanéité réservée. |
|
Tarification |
Pas de frais supplémentaires. |
Entraîne des frais supplémentaires. |
Quotas de simultanéité
Lambda définit des quotas pour la quantité totale de simultanéité que vous pouvez utiliser sur toutes les fonctions d’une Région. Ces quotas existent à deux niveaux :
-
Au niveau du compte, vos fonctions peuvent avoir jusqu’à 1 000 unités de simultanéité par défaut. Pour augmenter cette limite, consultez Demande d’augmentation de quota dans le Guide de l’utilisateur Service Quotas.
-
Au niveau de la fonction, vous pouvez réserver par défaut jusqu’à 900 unités de simultanéité pour l’ensemble de vos fonctions. Quelle que soit la limite totale de simultanéité de votre compte, Lambda réserve toujours 100 unités de simultanéité à vos fonctions qui ne réservent pas explicitement la simultanéité. Par exemple, si vous avez augmenté la limite de simultanéité de votre compte à 2 000, vous pouvez réserver jusqu’à 1 900 unités de simultanéité au niveau de la fonction.
Pour vérifier le quota de simultanéité au niveau de votre compte actuel, utilisez AWS Command Line Interface (AWS CLI) pour exécuter la commande suivante :
aws lambda get-account-settings
Vous devriez voir une sortie semblable à la suivante :
{ "AccountLimit": { "TotalCodeSize": 80530636800, "CodeSizeUnzipped": 262144000, "CodeSizeZipped": 52428800, "ConcurrentExecutions": 1000, "UnreservedConcurrentExecutions": 900 }, "AccountUsage": { "TotalCodeSize": 410759889, "FunctionCount": 8 } }
ConcurrentExecutions est le quota total de simultanéité au niveau de votre compte. UnreservedConcurrentExecutions est la quantité de concurrence réservée que vous pouvez encore allouer à vos fonctions.
Au fur et à mesure que votre fonction reçoit des demandes, Lambda augmente automatiquement le nombre d’environnements d’exécution pour traiter ces demandes jusqu’à ce que votre compte atteigne sa limite de simultanéité. Toutefois, pour éviter une mise à l’échelle excessive en réponse à des pics de trafic soudains, Lambda limite la rapidité avec laquelle vos fonctions peuvent être mises à l’échelle. Ce taux de mise à l'échelle simultanée est le taux maximal auquel les fonctions de votre compte peuvent évoluer en réponse à des demandes accrues. (C’est-à-dire la rapidité avec laquelle Lambda peut créer de nouveaux environnements d’exécution.) Le taux d'échelonnement de la simultanéité est différent de la limite de simultanéité au niveau du compte, qui est le montant total de simultanéité disponible pour vos fonctions.
Dans chacune et pour chaque fonctionRégion AWS, votre taux de mise à l’échelle de la simultanéité est de 1 000 instances d’environnement d’exécution toutes les 10 secondes. En d’autres termes, toutes les 10 secondes, Lambda peut allouer au maximum 1 000 instances d’environnement d’exécution supplémentaires à chacune de vos fonctions.
En général, il n’est pas nécessaire de se soucier de cette limitation. La vitesse de mise à l’échelle de Lambda est suffisante dans la plupart des cas d’utilisation.
Il est important de noter que le taux de mise à l'échelle de la simultanéité est une limite au niveau de la fonction. Cela signifie que chaque fonction de votre compte peut être mise à l’échelle indépendamment des autres fonctions.
Pour plus d’informations sur les comportements de mise à l’échelle, consultez Comportement de mise à l’échelle Lambda.
