Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillez les performances de l'instance Lightsail à l'aide de métriques
Après avoir lancé une instance dans Amazon Lightsail, vous pouvez consulter ses graphiques métriques dans l'onglet Metrics de la page de gestion de l'instance. La surveillance des métriques est un enjeu important pour assurer la fiabilité, la disponibilité et les performances de vos ressources. Surveillez et collectez régulièrement les données de métriques de vos ressources pour être prêt à intervenir pour déboguer une éventuelle défaillance à plusieurs points. Pour plus d'informations sur les métriques , consultez Métriques dans Amazon Lightsail.
Lorsque vous surveillez vos ressources, vous devez établir une base de référence des performances normales des ressources dans votre environnement. Vous pouvez alors configurer des alarmes dans la console Lightsail pour être averti lorsque vos ressources fonctionnent au-delà des seuils spécifiés. Pour plus d'informations, veuillez consulter Notifications et Alarmes.
Table des matières
Métriques d'instance disponibles
Les métriques d'instance suivantes sont disponibles :
-
Utilisation du processeur (
CPUUtilization) : pourcentage d'unités de calcul allouées qui sont actuellement en cours d'utilisation sur l'instance. Cette métrique identifie la puissance de traitement utilisée pour exécuter les applications sur l'instance. Les outils de votre système d'exploitation peuvent afficher un pourcentage inférieur à celui de Lightsail lorsque l'instance ne dispose pas d'un cœur de processeur complet.Lorsque vous consultez les graphiques des métriques d'utilisation du processeur pour vos instances dans la console Lightsail, vous verrez des zones durables et éclatables. Pour de plus amples informations sur la signification de ces zones, veuillez consulter Zones durables et extensibles d'utilisation de l'UC.
-
Minutes de capacité de débordement (
BurstCapacityTime) et pourcentage (BurstCapacityPercentage) : les minutes de capacité de débordement représentent le temps disponible pour que votre instance transmette des données en mode rafale à 100 % du processeur. Le pourcentage de capacité de débordement de l'UC représente le pourcentage de performances de l'UC disponible pour votre instance. Votre instance consomme et accumule en continu de la capacité en mode rafale. Les minutes de capacité de débordement ne sont consommées à plein débit que lorsque votre instance fonctionne en utilisant 100 % du processeur. Pour plus d'informations sur la capacité en mode rafale de l'instance, veuillez consulter Afficher la capacité de débordement des instances. -
Trafic réseau entrant (
NetworkIn) : nombre d'octets reçus par l'instance sur toutes les interfaces réseau. Cette métrique identifie le volume du trafic réseau entrant sur l'instance. Le nombre mentionné correspond au nombre d’octets reçus pendant la période. Comme cette métrique est signalée par intervalles de 5 minutes, divisez le nombre signalé par 300 pour obtenir des octets/s. -
Trafic réseau sortant (
NetworkOut) : nombre d'octets envoyés par l'instance sur toutes les interfaces réseau. Cette métrique identifie le volume du trafic réseau sortant de l'instance. Le nombre mentionné correspond au nombre d’octets envoyés pendant la période. Comme cette métrique est signalée par intervalles de 5 minutes, divisez le nombre signalé par 300 pour obtenir des octets/s. -
Échecs de contrôle de statut (
StatusCheckFailed) : indique si l'instance a réussi ou échoué à la fois au contrôle de statut de l'instance et au contrôle de statut du système. Cette métrique peut avoir la valeur 0 (succès) ou 1 (échec). Cette métrique est disponible à une fréquence de 1 minute. -
Échecs de contrôle de statut d'instance (
StatusCheckFailed_Instance) : indique si l'instance a réussi ou échoué au contrôle de statut d'instance. Cette métrique peut avoir la valeur 0 (succès) ou 1 (échec). Cette métrique est disponible à une fréquence de 1 minute. -
Échecs de contrôle de statut du système (
StatusCheckFailed_System) : indique si l'instance a réussi ou échoué au contrôle de statut du système. Cette métrique peut avoir la valeur 0 (succès) ou 1 (échec). Cette métrique est disponible à une fréquence de 1 minute. -
Demande de métadonnées sans jeton (
MetadataNoToken) : nombre d'accès réussis au service de métadonnées d'instance sans jeton. Cette métrique détermine s'il existe des processus accédant aux métadonnées d'instance qui utilisent Instance Metadata Service Version 1, et qui n'utilisent pas de jeton. Si toutes les demandes utilisent des sessions basées sur un jeton, par ex., Instance Metadata Service Version 2, la valeur est 0. Pour de plus amples informations, veuillez consulter Métadonnées d'instance et données utilisateur.
Zones durables et extensibles d'utilisation de l'UC
Lightsail utilise des instances évolutives qui fournissent un niveau de performance de base du processeur, mais ont également la capacité de fournir temporairement des performances du processeur supérieures à la base de référence, selon les besoins. D'où l'appellation « mode rafale ». Avec les instances extensibles, vous n'avez pas à surprovisionner l'instance en prévision de pics de performances occasionnels. Vous ne payez pas pour une capacité que vous n'utilisez jamais.
Le graphique de la métrique d'utilisation de l'UC pour vos instances contient une zone durable et une zone extensible. Votre instance Lightsail peut fonctionner indéfiniment dans la zone durable sans impact sur le fonctionnement de votre système.
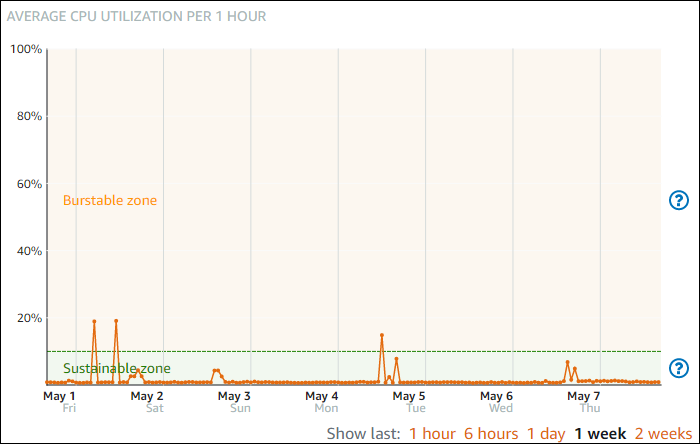
L'instance peut commencer à fonctionner dans la zone extensible lorsqu'elle est soumise à une charge lourde, par exemple lors de la compilation de code, de l'installation de nouveaux logiciels, de l'exécution d'une tâche de traitement par lots ou du traitement d'un nombre élevé de demandes de chargement. Lorsque le fonctionnement se déroule dans la zone extensible, l'instance consomme un plus grand nombre de cycles d'UC. Par conséquent, elle ne peut fonctionner dans cette zone que pendant une période de temps limitée.
La période pendant laquelle l'instance peut fonctionner dans la zone extensible dépend de la distance à laquelle elle se trouve dans cette zone. Une instance fonctionnant dans la partie inférieure de la zone extensible peut fonctionner en mode rafale pendant une période plus longue qu'une instance fonctionnant dans la partie supérieure de la zone extensible. Cependant, si une instance demeure dans la zone extensible pendant une période de temps prolongée, où qu'elle se trouve, elle finira par utiliser toute la capacité d'UC et reviendra dans la zone durable.
Surveillez la métrique d'utilisation d'UC de votre instance pour voir comment ses performances sont réparties entre les zones durable et extensible. Si votre système ne passe qu'occasionnellement dans la zone extensible, vous devriez pouvoir continuer à utiliser l'instance que vous exécutez. Toutefois, si vous constatez que votre instance passe beaucoup de temps dans la zone d'extension, vous pouvez passer à un forfait plus important pour votre instance (utilisez le plan à 12$USD/month plan instead of the $5 USD/month). Vous pouvez adopter un plus grand plan en créant un nouvel instantané de votre instance, puis en créant une nouvelle instance à partir de cet instantané.
Afficher les métriques de l'instance dans la console Lightsail
Procédez comme suit pour afficher les métriques de l'instance dans la console Lightsail.
-
Connectez-vous à la console Lightsail
. -
Dans le panneau de navigation de gauche, sélectionnez Instances.
-
Choisissez le nom de l'instance dont vous souhaitez afficher les métriques.
-
Choisissez l'onglet Métriques dans la page de gestion de l'instance.
-
Choisissez la métrique que vous souhaitez afficher dans le menu déroulant sous l'en-tête Graphiques des métriques.
Le graphique affiche une représentation visuelle des points de données pour la métrique choisie.
Note
Lorsque vous consultez les graphiques des métriques d'utilisation du processeur pour vos instances dans la console Lightsail, vous verrez des zones durables et éclatables. Pour de plus amples informations sur ces zones, veuillez consulter Zones durables et extensibles d'utilisation de l'UC.
-
Vous pouvez effectuer les actions suivantes sur le graphique des métriques :
-
Modifier la vue du graphique afin d'afficher les données pendant 1 heure, 6 heures, 1 jour, 1 semaine et 2 semaines.
-
Placer votre curseur sur un point de données pour afficher des informations détaillées sur ce point de données.
-
Ajouter une alarme pour la métrique choisie afin d'être averti lorsque cette métrique franchit un seuil que vous spécifiez. Pour plus d'informations, veuillez consulter Alarmes et Création d'alarmes de métrique d'instance.
-
Étapes suivantes
Vous pouvez effectuer quelques tâches supplémentaires pour les métriques de votre instance :
-
Ajouter une alarme pour la métrique choisie afin d'être averti lorsque cette métrique franchit un seuil que vous spécifiez. Pour plus d'informations, veuillez consulter Alarmes de métrique et Création d'alarmes de métrique d'instance.
-
Lorsqu'une alarme est déclenchée, une bannière de notification s'affiche dans la console Lightsail. Pour être averti par e-mail ou SMS, vous devez ajouter votre adresse e-mail et votre numéro de téléphone portable en tant que contacts de notification dans chaque Région AWS endroit où vous souhaitez surveiller vos ressources. Pour plus d'informations, veuillez consulter Ajout de contacts de notification.
-
Pour ne plus recevoir de notifications, vous pouvez supprimer votre adresse e-mail et votre téléphone portable de Lightsail. Pour plus d'informations, veuillez consulter Suppression ou désactivation d'alarmes de métrique. Vous pouvez également désactiver ou supprimer une alarme pour cesser de recevoir des notifications pour une alarme spécifique. Pour plus d'informations, veuillez consulter Suppression ou désactivation d'alarmes de métrique.
