Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Analyse du modèle de régression
Interprétation des prédictions
La sortie d'un modèle d'apprentissage-machine de régression est une valeur numérique pour la prédiction de la cible du modèle. Par exemple, si vous effectuez une prédiction des prix de logements, la prédiction du modèle peut être une valeur telle que 254 013.
Note
La plage des prédictions peut différer de la plage de la cible dans les données de formation. Par exemple, supposons que vous effectuez des prédictions de prix de logements et que la cible dans les données de formation avait des valeurs comprises dans une plage de 0 à 450 000. La cible prédite n'est pas nécessairement dans la même plage et peut prendre n'importe quelle valeur positive (supérieure à 450 000) ou négative (inférieure à zéro). Il est important de planifier comment gérer les valeurs de prédiction qui sortent d'une plage acceptable pour votre application.
Mesure de la précision du modèle d'apprentissage-machine
Pour les tâches de régression, Amazon ML utilise la métrique d'erreur quadratique moyenne (RMSE, Root Mean Square Error) qui est un standard de l'industrie. Il s'agit d'une mesure de distance entre la cible numérique prédite et la réponse numérique réelle (vérité du terrain). Plus la valeur de la métrique RMSE est petite, meilleure est la précision du modèle. Un modèle avec des prédictions parfaitement correctes aurait une métrique RMSE de 0. L'exemple suivant montre des données d'évaluation qui contiennent N enregistrements :

RMSE de référence
Amazon ML fournit une métrique de référence pour les modèles de régression. Il s'agit de la métrique RMSE pour un modèle de régression hypothétique qui prédirait toujours la moyenne de la cible comme réponse. Par exemple, si vous essayez de prédire l'âge d'un acheteur de maison et que l'âge moyen pour les observations dans vos données de formation est 35, le modèle de référence prédira toujours la réponse 35. Vous pouvez comparer votre modèle d'apprentissage-machine à cette référence afin de valider si votre modèle d'apprentissage-machine est meilleur qu'un modèle d'apprentissage-machine qui prédit cette réponse invariable.
Utilisation de la visualisation des performances
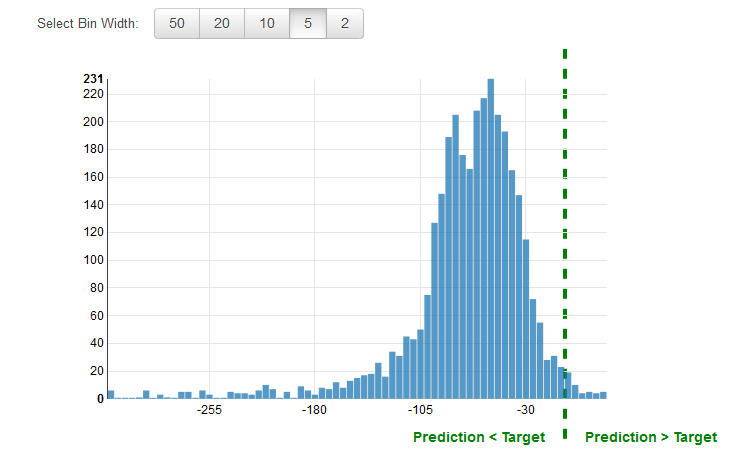
Il est usuel de passer en revue les résidus pour identifier les problèmes de régression éventuels. Un résidu pour une observation dans les données d'évaluation représente la différence entre la cible réelle et la cible prédite. Les résidus représentent la partie de la cible que le modèle n'est pas en mesure de prédire. Un résidu positif indique que le modèle sous-estime la cible (la cible réelle est supérieure à la cible prédite). Un résidu négatif indique une surestimation (la cible réelle est inférieure à la cible prédite). L'histogramme des résidus sur les données d'évaluation lors d'une distribution en forme de cloche centrée sur zéro indique que le modèle commet des erreurs d'une manière aléatoire et qu'il ne prédit pas systématiquement trop haut ou trop bas une plage particulière de valeurs cibles. Si les résidus ne constituent pas une forme en cloche centrée sur zéro, il y a une certaine structure dans l'erreur de prédiction du modèle. L'ajout de variables supplémentaires au modèle peut aider le modèle à capturer la tendance qui n'est pas capturée par le modèle actuel. L'illustration suivante montre des résidus qui ne sont pas centrés sur zéro.