Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comprendre le format de données pour Amazon ML
Les données d'entrée sont les données que vous utilisez pour créer une source de données. Vous devez enregistrer vos données d'entrée au format CSV (valeurs séparées par des virgules). Chaque ligne du fichier .csv est un enregistrement de données ou une observation unique. Chaque colonne du fichier .csv contient un attribut de l'observation. Par exemple, la figure suivante illustre le contenu d'un fichier .csv qui compte quatre observations, chacune sur sa propre ligne. Chaque observation contient huit attributs, séparés par des virgules. Les attributs représentent les informations suivantes concernant chaque individu représenté par une observation : CustomerID, JoBid, éducation, logement, prêt, campagne, durée, campagne. willRespondTo

Attributs
Amazon ML nécessite un nom pour chaque attribut. Vous pouvez spécifier les noms des attributs en :
-
incluant les noms des attributs dans la première ligne (également connue sous le nom de ligne d'en-tête) du fichier .csv que vous utilisez en tant que données d'entrée ;
-
incluant les noms des attributs dans un fichier de schéma distinct qui est situé dans le même compartiment S3 que vos données d'entrée.
Pour plus d'informations sur l'utilisation des fichiers de schéma, consultez Création d'un schéma de données.
L'exemple suivant d'un fichier .csv comprend les noms des attributs dans la ligne d'en-tête.
customerId,jobId,education,housing,loan,campaign,duration,willRespondToCampaign 1,3,basic.4y,no,no,1,261,0 2,1,high.school,no,no,22,149,0 3,1,high.school,yes,no,65,226,1 4,2,basic.6y,no,no,1,151,0
Exigences en matière de format du fichier d'entrée
Le fichier .csv qui contient vos données d'entrée doit répondre aux exigences suivantes :
-
Il doit être en texte brut et utiliser un jeu de caractères tel qu'ASCII, Unicode ou EBCDIC.
-
Il est composé d'observations, une observation par ligne.
-
Pour chaque observation, les valeurs d'attribut doivent être séparées par des virgules.
-
Si une valeur d'attribut contient une virgule (délimiteur), la totalité de la valeur d'attribut doit être entre guillemets doubles.
-
Chaque observation doit être terminée par un end-of-line caractère spécial ou une séquence de caractères indiquant la fin d'une ligne.
-
Les valeurs d'attribut ne peuvent pas inclure de end-of-line caractères, même si la valeur d'attribut est placée entre guillemets.
-
Chaque observation doit avoir le même nombre d'attributs et la même séquence d'attributs.
-
Chaque observation ne doit pas dépasser 100 Ko. Amazon ML rejette toute observation supérieure à 100 Ko pendant le traitement. Si Amazon ML rejette plus de 10 000 observations, il rejette l'intégralité du fichier .csv.
Utilisation de plusieurs fichiers comme entrée de données dans Amazon ML
Vous pouvez fournir vos données à Amazon ML sous forme de fichier unique ou de collection de fichiers. Les collections doivent satisfaire les conditions suivantes :
-
Tous les fichiers doivent avoir le même schéma de données.
-
Tous les fichiers doivent résider dans le même préfixe Amazon Simple Storage Service (Amazon S3), et le chemin que vous fournissez pour la collection doit se terminer par une barre oblique («/»).
Par exemple, si vos fichiers de données sont nommés input1.csv, input2.csv et input3.csv, et que le nom de votre compartiment S3 est s3://examplebucket, les chemins de vos fichiers peuvent ressembler à :
s3 ://examplebucket/path/to/data/input1.csv
s3 ://examplebucket/path/to/data/input2.csv
s3 ://examplebucket/path/to/data/input3.csv
Vous devez fournir l'emplacement S3 suivant en entrée à Amazon ML :
's3 :///' examplebucket/path/to/data
End-of-Line Caractères au format CSV
Lorsque vous créez votre fichier .csv, chaque observation sera terminée par un end-of-line caractère spécial. Ce caractère n'est pas visible, mais il est automatiquement inclus à la fin de chaque observation lorsque vous appuyez sur votre touche Entrée ou Return. Le caractère spécial qui représente le end-of-line varie en fonction de votre système d'exploitation. Les systèmes Unix, tels que Linux ou OS X, utilisent un caractère de saut de ligne indiqué par « \n » (code ASCII 10 en notation décimale ou 0x0a en notation hexadécimale). Microsoft Windows utilise deux caractères appelés retour chariot et saut de ligne qui sont indiqués par « \r\n » (codes ASCII 13 et 10 en notation décimale, ou 0x0d et 0x0a en notation hexadécimale).
Si vous souhaitez utiliser OS X et Microsoft Excel pour créer votre fichier .csv, effectuez la procédure suivante. Veillez à choisir le format correct.
Pour enregistrer un fichier .csv si vous utilisez OS X et Excel
-
Quand vous enregistrez le fichier .csv, choisissez Format, puis choisissez CSV (Windows) (séparateur : point-virgule) (.csv).
-
Choisissez Save (Enregistrer).
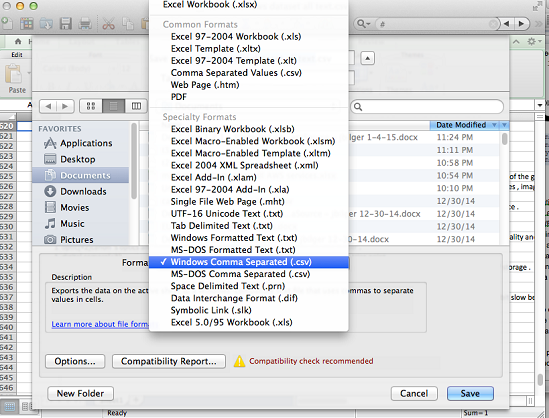
Important
N'enregistrez pas le fichier .csv en utilisant les formats valeurs séparées par des virgules (.csv) ou MS-DOS séparés par des virgules (.csv) car Amazon ML ne peut pas les lire.
