Amazon Managed Service for Apache Flink (Amazon MSF) était auparavant connu sous le nom d'Amazon Kinesis Data Analytics pour Apache Flink.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Points de contrôle
Les points de contrôle sont le mécanisme utilisé par Flink pour garantir que l’état d’une application est tolérant aux pannes. Ce mécanisme permet à Flink de récupérer l’état des opérateurs en cas d’échec de la tâche et donne à l’application la même sémantique qu’une exécution sans échec. Avec le service géré pour Apache Flink, l’état d’une application est stocké dans RocksDB, un magasin de clés/valeurs intégré qui conserve son état de fonctionnement sur le disque. Lorsqu’un point de contrôle est pris, l’état est également transféré sur Amazon S3. Ainsi, même en cas de perte du disque, le point de contrôle peut être utilisé pour restaurer l’état de l’application.
Pour plus d’informations, consultez Fonctionnement des instantanés d’état
Étapes du point de contrôle
Pour une sous-tâche d’opérateur de point de contrôle dans Flink, il y a 5 étapes principales :
En attente [Délai de démarrage] : Flink utilise des barrières de point de contrôle qui sont insérées dans le flux. Ainsi, le délai à cette étape correspond au temps pendant lequel l’opérateur attend que la barrière de contrôle l’atteigne.
Alignement [Durée de l’alignement] : à cette étape, la sous-tâche a atteint une barrière, mais elle attend les barrières provenant d’autres flux d’entrée.
Point de contrôle synchrone [Durée de synchronisation] : c’est à cette étape que la sous-tâche crée réellement un instantané de l’état de l’opérateur et bloque toutes les autres activités de la sous-tâche.
Point de contrôle asynchrone [Durée asynchrone] : pendant la majeure partie de cette étape, la sous-tâche télécharge l’état vers Amazon S3. Au cours de cette étape, la sous-tâche n’est plus bloquée et peut traiter des enregistrements.
Reconnaissance — Il s'agit généralement d'une étape courte et consiste simplement à envoyer un accusé de réception aux messages de validation JobManager et à exécuter les éventuels messages de validation (par exemple avec les puits Kafka).
Chacune de ces étapes (à l’exception de la reconnaissance) correspond à une métrique de durée pour les points de contrôle, disponible dans l’interface utilisateur Web de Flink, qui peut aider à isoler la cause d’un long point de contrôle.
Pour voir une définition exacte de chacune des métriques disponibles sur les points de contrôle, rendez-vous dans l’onglet Historique
Enquête
Lorsque vous étudiez la durée prolongée d’un point de contrôle, la chose la plus importante à déterminer est le goulot d’étranglement du point de contrôle, c’est-à-dire quel opérateur et quelle sous-tâche mettent le plus de temps à atteindre le point de contrôle et quelle étape de cette sous-tâche prend le plus de temps. Cela peut être déterminé à l’aide de l’interface utilisateur Web de Flink, dans la tâche de contrôle des tâches. L’interface Web de Flink fournit des données et des informations qui aident à étudier les problèmes liés aux points de contrôle. Pour une analyse complète, consultez Surveillance des points de contrôle
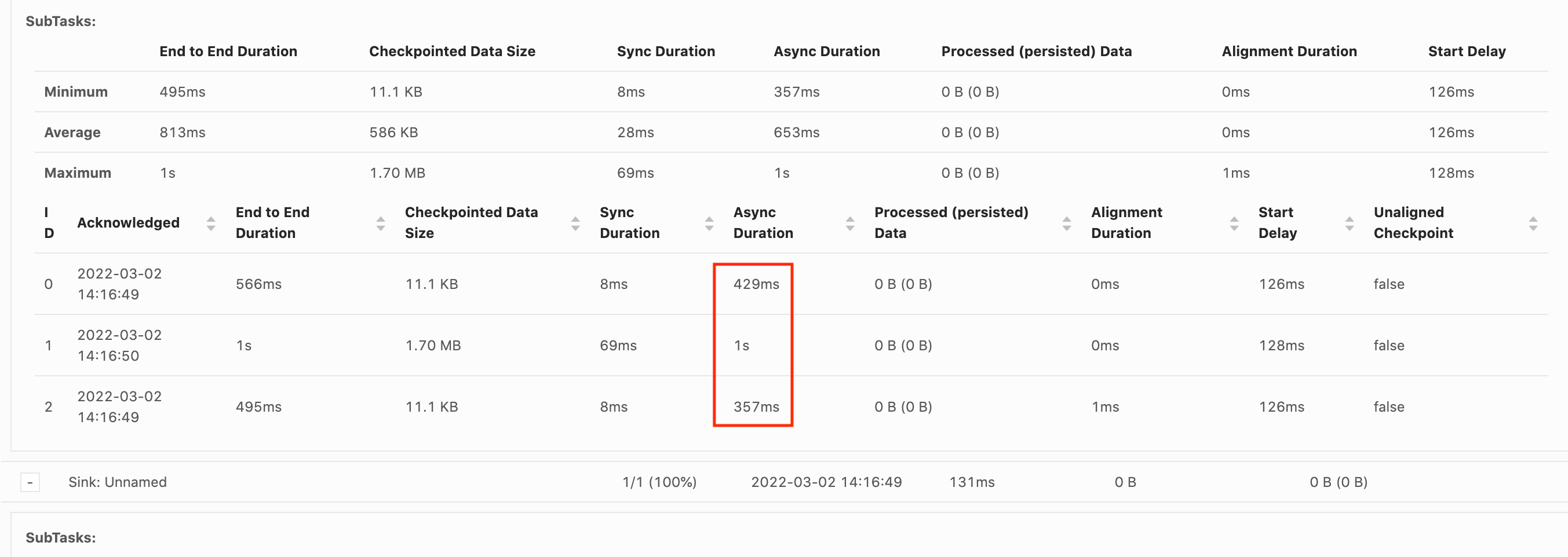
La première chose à examiner est la durée de bout en bout de chaque opérateur dans le graphique des tâches afin de déterminer quel opérateur met beaucoup de temps à effectuer un point de contrôle et mérite une enquête plus approfondie. Selon la documentation de Flink, la durée est définie comme suit :
Durée comprise entre l’horodatage du déclencheur et le dernier accusé de réception (ou n/a si aucun accusé de réception n’a encore été reçu). Cette durée de bout en bout pour un point de contrôle complet est déterminée par la dernière sous-tâche qui accuse réception du point de contrôle. Ce délai est généralement supérieur à celui dont ont besoin les sous-tâches individuelles pour effectuer un point de contrôle de l’état.
Les autres durées du point de contrôle fournissent également des informations plus précises sur l’endroit où le temps est passé.
Si la durée de synchronisation est élevée, cela indique que quelque chose se passe pendant la création de l’instantané. Au cours de cette étape, snapshotState() est appelé pour les classes qui implémentent l’interface snapshotState ; il peut s’agir de code utilisateur, donc les vidages de threads peuvent être utiles pour étudier cela.
Une longue durée asynchrone suggère que beaucoup de temps est consacré au chargement de l’état sur Amazon S3. Cela peut se produire si l’état est volumineux ou si de nombreux fichiers d’état sont en cours de chargement. Si tel est le cas, cela vaut la peine d’étudier la manière dont l’état est utilisé par l’application et de s’assurer que les structures de données natives de Flink sont utilisées dans la mesure du possible (Using Keyed State
Si le délai de démarrage est élevé, cela signifie que la majeure partie du temps est consacrée à attendre que la barrière du point de contrôle atteigne l’opérateur. Cela indique que l’application met un certain temps à traiter les enregistrements, ce qui signifie que l’obstacle traverse lentement le graphique des tâches. C’est généralement le cas si le la tâche est soumise à une contre-pression ou si un ou plusieurs opérateurs sont constamment occupés. Voici un exemple de situation dans JobGraph laquelle le deuxième KeyedProcess opérateur est occupé.
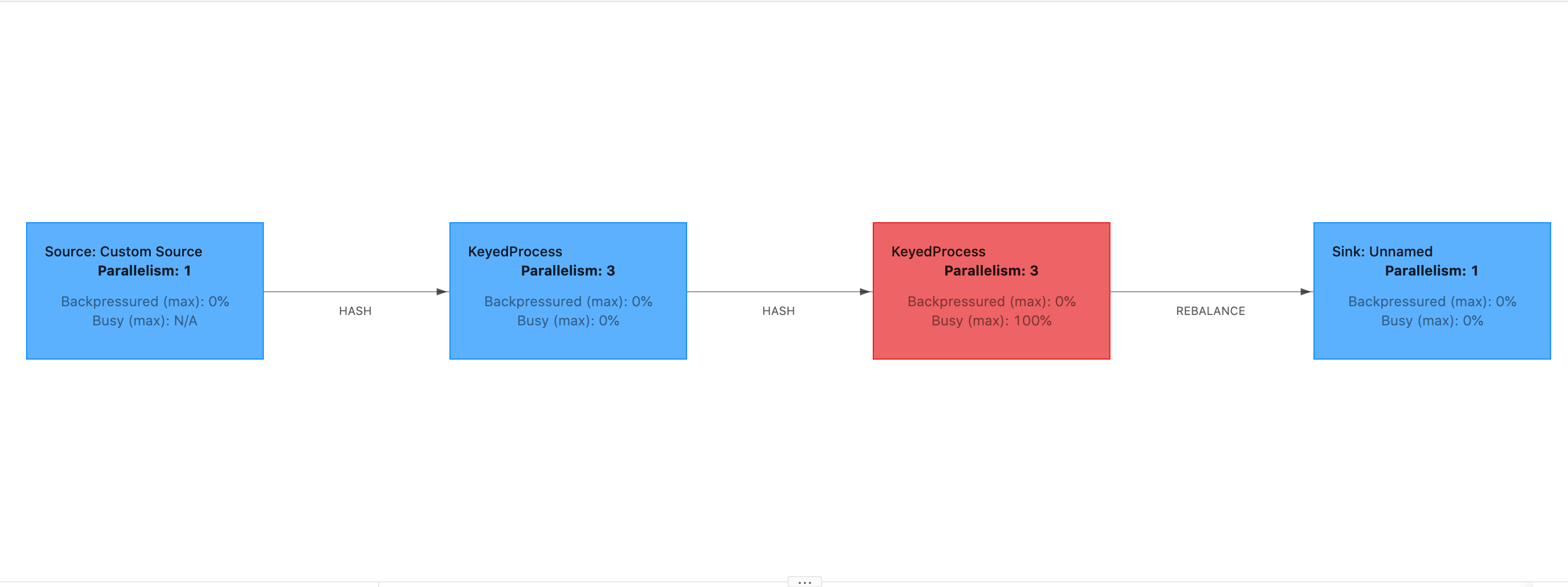
Vous pouvez étudier ce qui prend autant de temps en utilisant Flink Flame Graphs ou en utilisant des TaskManager thread dumps. Une fois que le goulot d’étranglement a été identifié, il peut être étudié plus en détail à l’aide des graphiques en flamme ou des vidages de thread.
Vidages de thread
Les vidages de thread sont un autre outil de débogage légèrement inférieur à celui des graphiques en flamme. Un vidage de thread affiche l’état d’exécution de tous les threads à un moment donné. Flink effectue un vidage de thread JVM, qui est un état d’exécution de tous les threads du processus Flink. L’état d’un thread est présenté par une trace de pile du thread ainsi que par des informations supplémentaires. Les graphiques en flamme sont en fait construits à partir de plusieurs traces de pile prises en succession rapide. Le graphique est une visualisation réalisée à partir de ces traces qui permet d’identifier facilement les chemins de code courants.
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Vous trouverez ci-dessus un extrait d’un vidage de thread issu de l’interface utilisateur de Flink pour un seul thread. La première ligne contient des informations générales sur ce thread, notamment :
Le nom du fil KeyedProcess (1/3) #0
La priorité du thread prio=5
Un identifiant de thread unique Id=1423
L’état du thread : EXÉCUTABLE
Le nom d’un thread donne généralement des informations sur son usage général. Les fils d'opérateurs peuvent être identifiés par leur nom puisque les fils d'opérateurs portent le même nom que l'opérateur, ainsi qu'une indication de la sous-tâche à laquelle ils sont liés. Par exemple, le fil KeyedProcess (1/3) #0 provient de l'KeyedProcessopérateur et provient de la première sous-tâche (sur 3).
Les threads peuvent avoir l’un des états suivants :
NOUVEAU : le thread a été créé mais n’a pas encore été traité
EXÉCUTABLE : le thread est en cours d’exécution sur le processeur
BLOQUÉ : le thread attend qu’un autre thread lève son verrou
EN ATTENTE : le thread attend à l’aide d’une méthode
wait(),join()oupark()EN ATTENTE PROGRAMMÉE : le thread attend en utilisant une méthode veille, attendre, rejoindre ou parquer, mais avec un temps d’attente maximal.
Note
Dans Flink 1.13, la profondeur maximale d’une trace de pile dans le vidage de thread est limitée à 8.
Note
Les vidages de thread doivent être le dernier recours pour résoudre les problèmes de performances dans une application Flink, car ils peuvent être difficiles à lire et nécessiter le prélèvement de plusieurs échantillons et leur analyse manuelle. Dans la mesure du possible, il est préférable d’utiliser des graphiques en flamme.
Vidages de thread dans Flink
Dans Flink, un vidage de thread peut être effectué en choisissant l’option Gestionnaires de tâches dans la barre de navigation à gauche de l’interface utilisateur de Flink, en sélectionnant un gestionnaire de tâches spécifique, puis en accédant à l’onglet Thread Dump. Le vidage de thread peut être téléchargé, copié dans votre éditeur de texte préféré (ou analyseur de vidage de thread) ou analysé directement dans l’affichage en texte de l’interface utilisateur Web de Flink (cette dernière option peut toutefois s’avérer un peu compliquée).
Pour déterminer dans quel gestionnaire de tâches, un thread dump de l'TaskManagersonglet peut être utilisé lorsqu'un opérateur particulier est sélectionné. Cela montre que l’opérateur exécute différentes sous-tâches d’un opérateur et qu’il peut s’exécuter sur différents gestionnaires de tâches.
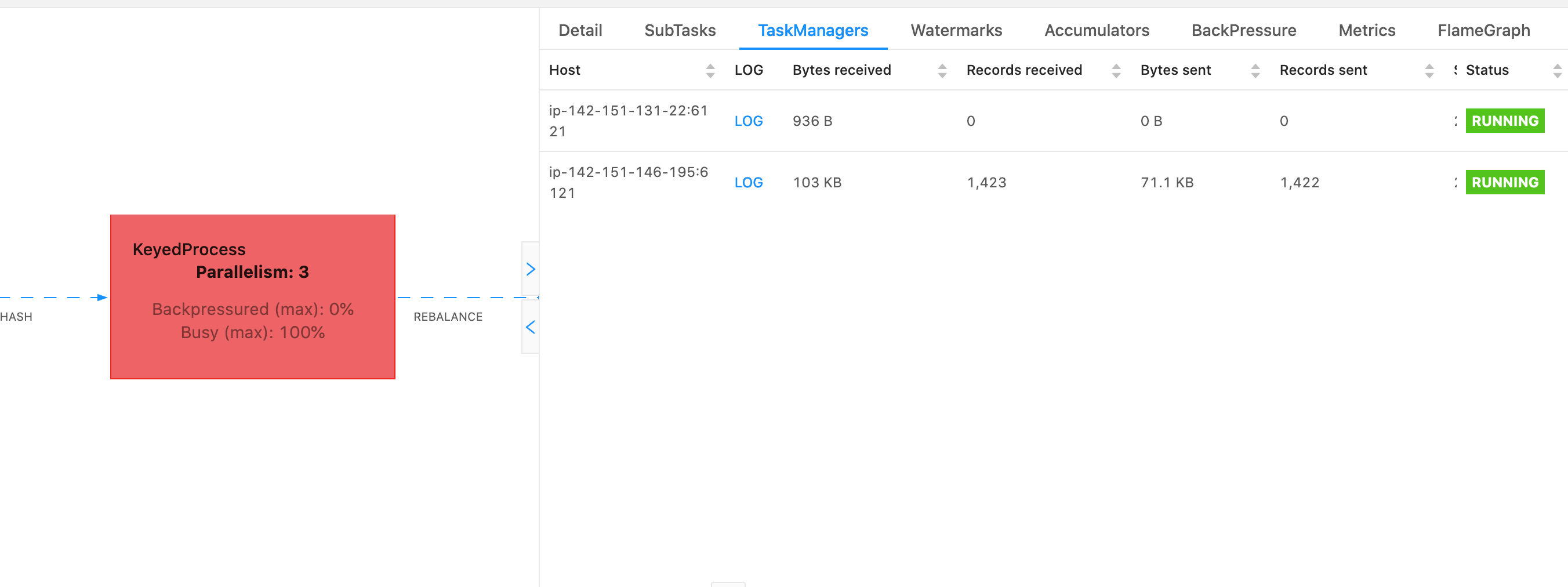
Le vidage sera composé de plusieurs traces de pile. Cependant, lors de l’enquête sur le vidage, les informations relatives à un opérateur sont les plus importantes. Elles sont faciles à trouver, puisque les threads d’opérateurs portent le même nom que l’opérateur et indiquent à quelle sous-tâche ils sont liés. Par exemple, la trace de pile suivante provient de l'KeyedProcessopérateur et constitue la première sous-tâche.
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Cela peut prêter à confusion s’il existe plusieurs opérateurs portant le même nom, mais nous pouvons nommer les opérateurs pour contourner ce problème. Par exemple :
.... .process(new ExpensiveFunction).name("Expensive function")
Graphiques en flamme
Les graphiques en flamme constituent un outil de débogage utile qui permet de visualiser les traces du code ciblé, ce qui permet d’identifier les chemins de code les plus fréquents. Ils sont créés en échantillonnant plusieurs fois des traces de pile. L’axe X d’un graphique en flamme montre les différents profils de pile, tandis que l’axe Y indique la profondeur de la pile et les appels dans la trace de pile. Un seul rectangle dans un graphique en flamme représente un cadre de pile, et la largeur d’un cadre indique la fréquence à laquelle il apparaît dans les piles. Pour plus de détails sur les graphiques en flamme et sur leur utilisation, consultez Graphiques en flamme
Dans Flink, le graphe de flamme d'un opérateur est accessible via l'interface utilisateur Web en sélectionnant un opérateur, puis en choisissant l'FlameGraphonglet. Une fois que suffisamment d’échantillons ont été prélevés, le graphique en flamme s’affiche. Voici le car il fallait ProcessFunction beaucoup de temps FlameGraph pour se rendre au point de contrôle.
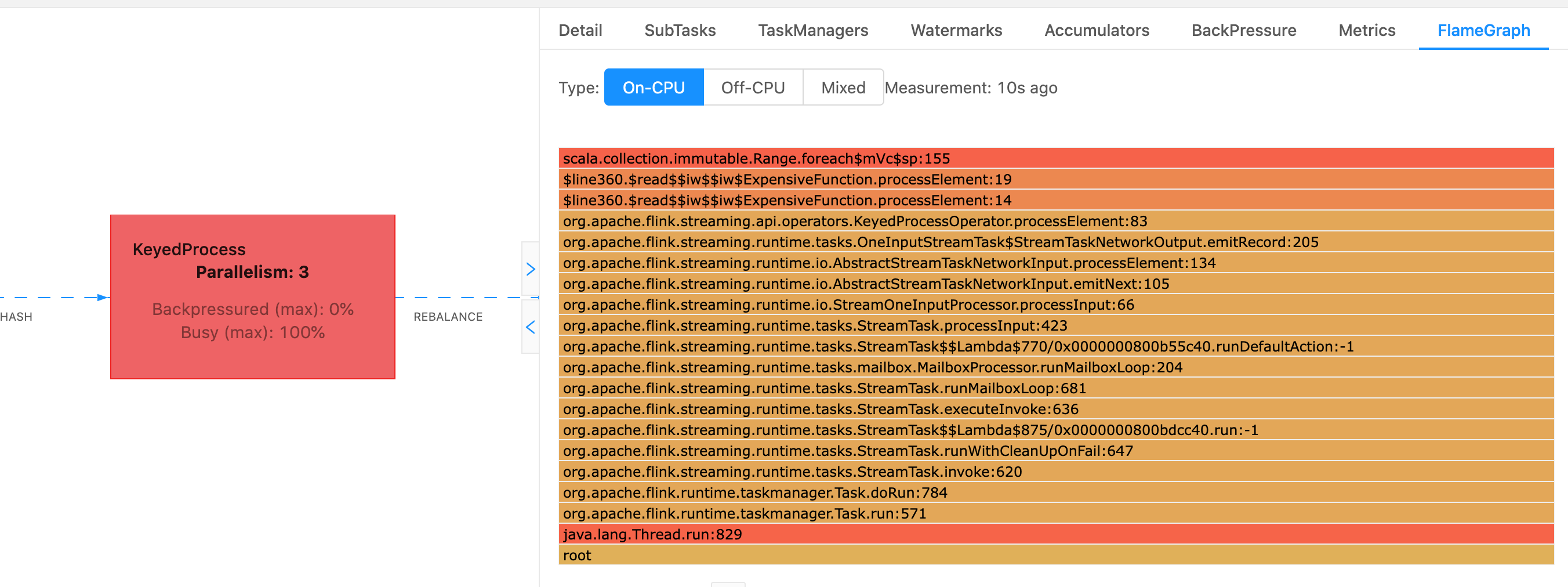
Il s'agit d'un graphique en flammes très simple qui montre que tout le temps du processeur est consacré à un seul coup processElement d'œil à l' ExpensiveFunction opérateur. Vous obtenez également le numéro de ligne qui aide à déterminer l’endroit où l’exécution du code a lieu.
