Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cas d’utilisation
Vous trouverez ci-dessous des cas d'utilisation de la recherche vectorielle.
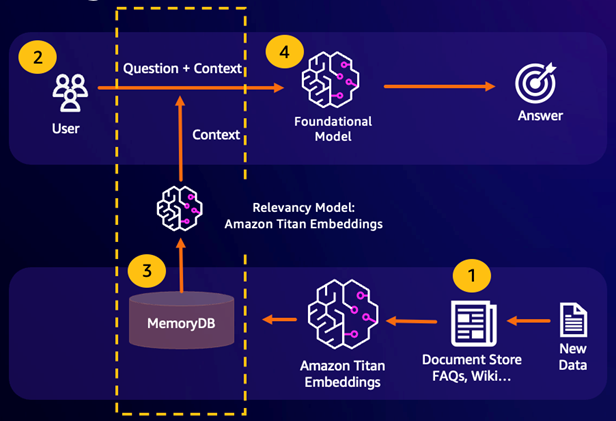
Génération augmentée de récupération (RAG)
Retrieval Augmented Generation (RAG) utilise la recherche vectorielle pour récupérer des passages pertinents à partir d'un vaste corpus de données afin d'enrichir un grand modèle de langage (LLM). Plus précisément, un encodeur intègre le contexte d'entrée et la requête de recherche dans des vecteurs, puis utilise une recherche approximative du plus proche voisin pour trouver des passages sémantiquement similaires. Ces passages récupérés sont concaténés avec le contexte d'origine pour fournir des informations pertinentes supplémentaires au LLM afin de renvoyer une réponse plus précise à l'utilisateur.
Cache sémantique durable
La mise en cache sémantique est un processus visant à réduire les coûts de calcul en stockant les résultats précédents du FM. En réutilisant les résultats précédents issus d'inférences antérieures au lieu de les recalculer, la mise en cache sémantique réduit la quantité de calcul requise lors de l'inférence via le. FMs MemoryDB permet une mise en cache sémantique durable, ce qui évite la perte de données de vos inférences passées. Cela permet à vos applications d'IA générative de répondre en quelques millisecondes à un chiffre avec des réponses à des questions sémantiquement similaires antérieures, tout en réduisant les coûts en évitant les inférences LLM inutiles.
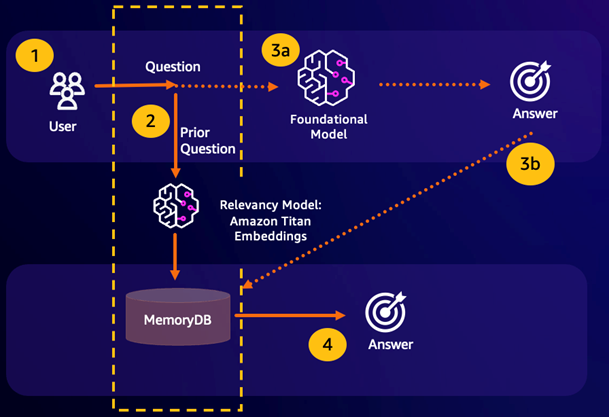
Résultat de recherche sémantique : si la requête d'un client est sémantiquement similaire sur la base d'un score de similarité défini à une question précédente, la mémoire tampon FM (MemoryDB) renverra la réponse à la question précédente à l'étape 4 et n'appellera pas le FM pendant les étapes 3. Cela permettra d'éviter la latence du modèle de base (FM) et les coûts encourus, offrant ainsi une expérience plus rapide au client.
Erreur de recherche sémantique : si la requête d'un client n'est pas sémantiquement similaire, sur la base d'un score de similarité défini, à une requête précédente, le client appellera le FM pour lui fournir une réponse à l'étape 3a. La réponse générée par le FM sera ensuite stockée sous forme de vecteur dans MemoryDB pour les futures requêtes (étape 3b) afin de minimiser les coûts du FM sur des questions sémantiquement similaires. Dans ce flux, l'étape 4 ne serait pas invoquée car il n'y avait aucune question sémantiquement similaire pour la requête d'origine.
Détection des fraudes
La détection des fraudes, une forme de détection des anomalies, représente les transactions valides sous forme de vecteurs tout en comparant les représentations vectorielles des nouvelles transactions nettes. Une fraude est détectée lorsque ces nouvelles transactions nettes présentent une faible similitude avec les vecteurs représentant les données transactionnelles valides. Cela permet de détecter la fraude en modélisant un comportement normal, plutôt que d'essayer de prévoir tous les cas de fraude possibles. MemoryDB permet aux entreprises de le faire en période de débit élevé, avec un minimum de faux positifs et une latence d'un chiffre en millisecondes.

Autres cas d’utilisation
Les moteurs de recommandation peuvent trouver des produits ou des contenus similaires aux utilisateurs en représentant les éléments sous forme de vecteurs. Les vecteurs sont créés en analysant les attributs et les modèles. Sur la base des modèles et des attributs des utilisateurs, de nouveaux éléments invisibles peuvent être recommandés aux utilisateurs en trouvant les vecteurs les plus similaires déjà notés positivement et alignés sur l'utilisateur.
Les moteurs de recherche de documents représentent les documents texte sous forme de vecteurs denses de nombres, capturant le sens sémantique. Au moment de la recherche, le moteur convertit une requête de recherche en vecteur et trouve les documents contenant les vecteurs les plus similaires à la requête en utilisant une recherche approximative du plus proche voisin. Cette approche de similarité vectorielle permet de faire correspondre les documents en fonction de leur signification plutôt que de simplement faire correspondre des mots clés.
