Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comprendre les connecteurs
Un connecteur intègre des systèmes externes et des services Amazon à Apache Kafka en copiant en continu les données de streaming d'une source de données vers votre cluster Apache Kafka, ou en copiant en continu les données de votre cluster vers un récepteur de données. Un connecteur peut également exécuter une logique légère telle que la transformation, la conversion de format ou le filtrage des données avant de les livrer à une destination. Les connecteurs source extraient les données d'une source de données et les transmettent au cluster, tandis que les connecteurs récepteurs extraient les données du cluster et les transfèrent vers un récepteur de données.
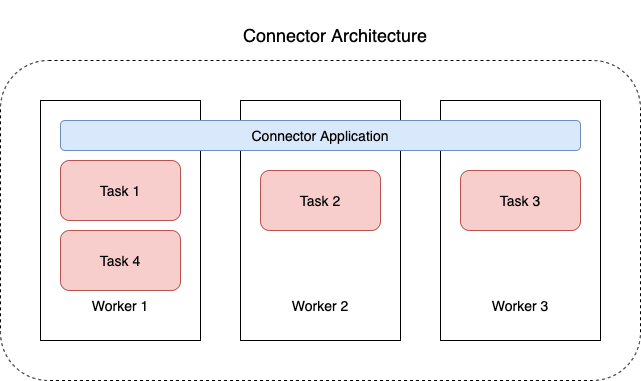
Le diagramme suivant illustre l'architecture d'un connecteur. Un worker est un processus de machine virtuelle Java (JVM) qui exécute la logique du connecteur. Chaque worker crée un ensemble de tâches qui s'exécutent dans des threads parallèles et se chargent de copier les données. Les tâches ne stockent pas l'état et peuvent donc être démarrées, arrêtées ou redémarrées à tout moment afin de fournir un pipeline de données résilient et évolutif.