Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Détection des anomalies dans Amazon OpenSearch Service OpenSearch
La fonctionnalité de détection des anomalies d'Amazon OpenSearch OpenSearch Service détecte automatiquement et en temps quasi réel les anomalies OpenSearch présentes dans vos données OpenSearch à l'aide de l'algorithme Random Cut Forest (RCF). RCF est un algorithme de machine learning non supervisé qui modélise un croquis de votre flux de données entrant. Cet algorithme calcule une valeur anomaly grade et confidence score pour chaque point de données entrant. La fonctionnalité de détection des anomalies utilise ces valeurs pour différencier une anomalie des variations normales de vos données.
Vous pouvez jumeler le plugin de détection des anomalies avec le plugin pour vous avertir dès la détection des anomalies.
La fonctionnalité de détection des anomalies prend en charge le contrôle précis des accès, ou n'importe quelle OpenSearch version d'OpenSearch. Tous les types d’instances prennent en charge la détection des anomalies excepté t2.micro et t2.small.
Note
Cette documentation fournit un bref aperçu de la détection des anomalies dans le contexte d'Amazon OpenSearch Service. Pour une documentation complète, y compris les étapes détaillées, une référence d'API, une référence de tous les paramètres disponibles et les étapes de création de visualisations et de tableaux de bord, consultez la section Détection des anomalies
Prérequis
Les prérequis suivants s'appliquent à la fonctionnalité de détection des anomalies :
-
La fonctionnalité de détection des anomalies requiert Elasticsearch 7.4 OpenSearch ou version ultérieure.
-
La fonctionnalité de détection des anomalies prend en charge le contrôle précis des accès à partir d'Elasticsearch versions 7.9 et ultérieures, et de toutes les versions d'OpenSearch. OpenSearch Avant la version 7.9 d’Elasticsearch, seuls les utilisateurs administrateurs peuvent créer, afficher et gérer les détecteurs.
-
Si votre domaine utilise le contrôle précis des accès, les utilisateurs non administrateurs doivent être mappés au anomaly_read_access rôle anomaly_access dans OpenSearch les tableaux de bord OpenSearch afin de créer et de
anomaly_full_accessgérer les détecteurs.
Mise en route avec la détection des anomalies
Pour commencer, choisissez Anomaly Detection (Détection des anomalies) dans OpenSearch OpenSearch Dashboards.
Étape 1 : Créer un détecteur
Un détecteur est une tâche individuelle de détection d'anomalie. Vous pouvez créer plusieurs détecteurs, lesquels peuvent fonctionner simultanément, chacun d'entre eux analysant des données provenant de sources différentes.
Étape 2 : Ajouter des fonctionnalités à votre détecteur
Le terme « fonctionnalité » désigne le champ de votre index dans lequel vous recherchez les anomalies. Un détecteur peut détecter des anomalies sur une ou plusieurs fonctionnalités. Vous devez choisir une des agrégations suivantes pour chaque fonctionnalité : average(), sum(), count(), min() ou max().
Note
La méthode count() d'agrégation n'est disponible que dans OpenSearch OpenSearch et à partir de la version 7.7 d'Elasticsearch. Pour Elasticsearch version 7.4, utilisez une expression personnalisée comme celle-ci :
{ "aggregation_name": { "value_count": { "field": "field_name" } } }
La méthode d'agrégation détermine ce qui constitue une anomalie. Par exemple, si vous choisissez min(), le détecteur se concentre sur la recherche d'anomalies en se basant sur les valeurs minimales de votre fonctionnalité. Si vous choisissez average(), le détecteur détecte des anomalies en se basant sur les valeurs moyennes de votre fonctionnalité. Vous pouvez ajouter un maximum de cinq fonctionnalités par détecteur.
Vous pouvez configurer les paramètres facultatifs suivants (disponibles à partir de la version 7.7 d’Elasticsearch) :
-
Champ Catégorie : classez ou découpez vos données à l'aide d'une dimension telle que l'adresse IP, l'ID du produit, le code du pays, etc.
-
Taille de la fenêtre : définissez le nombre d'intervalles d'agrégation de votre flux de données à prendre en compte dans une fenêtre de détection.
Après avoir configuré vos fonctionnalités, prévisualisez des exemples d'anomalies et, si nécessaire, ajustez les paramètres des fonctionnalités.
Étape 3 : Observer les résultats
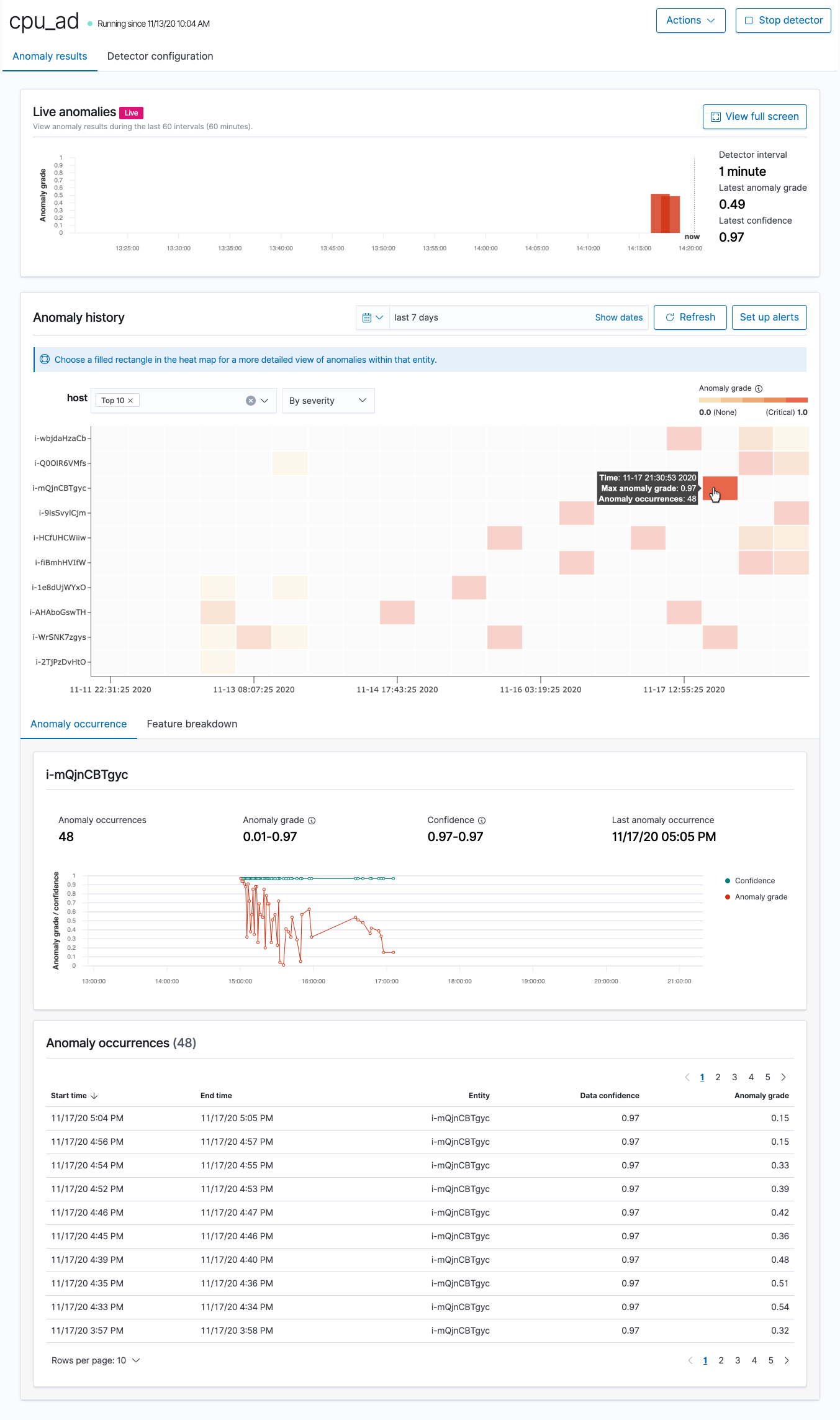
-
Anomalies en direct : affiche les résultats des anomalies en direct pour les 60 derniers intervalles. Par exemple, si l'intervalle est défini sur 10, il affiche les résultats des 600 dernières minutes. Ce graphique est mis à jour toutes les 30 secondes.
-
Historique des anomalies : représente le degré d'anomalie avec la métrique de confiance correspondante.
-
Ventilation des fonctionnalités : représente les fonctionnalités en fonction de la méthode d'agrégation. Vous pouvez faire varier la plage date-heure du détecteur.
-
Occurrences des anomalies : montre le
Start time,End time,Data confidenceetAnomaly gradepour chaque anomalie détectée.Si vous définissez le champ de catégorie, vous accédez à un graphique Carte thermique supplémentaire qui met en corrélation les résultats relatifs aux entités anormales. Choisissez un rectangle rempli pour obtenir une vue plus détaillée de l'anomalie.
Étape 4 : Configurer des alertes
Pour créer un système de suivi capable de vous envoyer des notifications lors de la détection d'anomalies, choisissez Set up alerts (Configurer les alertes). Le plug-in vous redirige vers la page Ajouter un système de suivi
