Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Qu'est-ce qu'Amazon OpenSearch Serverless ?
Amazon OpenSearch Serverless est une option sans serveur à la demande pour Amazon OpenSearch Service qui élimine la complexité opérationnelle liée au provisionnement, à la configuration et au réglage des clusters. OpenSearch C'est la solution idéale pour les entreprises qui préfèrent ne pas gérer elles-mêmes leurs clusters ou qui ne disposent pas des ressources et de l'expertise nécessaires pour effectuer des déploiements à grande échelle. Avec OpenSearch Serverless, vous pouvez rechercher et analyser de gros volumes de données sans gérer l'infrastructure sous-jacente.
Une collection OpenSearch sans serveur est un groupe d' OpenSearch index qui fonctionnent ensemble pour prendre en charge une charge de travail ou un cas d'utilisation spécifique. Les collections simplifient les opérations par rapport aux OpenSearch clusters autogérés, qui nécessitent un provisionnement manuel.
Les collections utilisent le même stockage à haute capacité, distribué et hautement disponible que les domaines de OpenSearch service provisionnés, mais réduisent encore la complexité en éliminant la configuration et le réglage manuels. Les données d'une collection sont cryptées pendant le transfert. OpenSearch Serverless prend également en charge les OpenSearch tableaux de bord, fournissant une interface pour l'analyse des données.
Actuellement, les collections sans serveur exécutent la OpenSearch version 2.17.x. À mesure que de nouvelles versions sont publiées, OpenSearch Serverless met automatiquement à niveau les collections pour intégrer de nouvelles fonctionnalités, des corrections de bogues et des améliorations de performances.
OpenSearch Serverless prend en charge les mêmes opérations d'API d'ingestion et de requête que la suite OpenSearch open source, ce qui vous permet de continuer à utiliser vos clients et applications existants. Vos clients doivent être compatibles avec la OpenSearch version 2.x pour fonctionner avec OpenSearch Serverless. Pour de plus amples informations, veuillez consulter Ingestion de données dans des collections Amazon OpenSearch Serverless.
Rubriques
Cas d'utilisation du mode OpenSearch Serverless
OpenSearch Serverless prend en charge deux principaux cas d'utilisation :
-
Analyse des journaux : le segment d'analyse des journaux se concentre sur les grands volumes de données de séries temporelles semi-structurées et générées par des machines, afin d'obtenir des informations sur les opérations et le comportement des utilisateurs.
-
Recherche en texte intégral : le segment de recherche en texte intégral alimente les applications de vos réseaux internes (systèmes de gestion de contenu, documents juridiques) et les applications accessibles sur Internet, telles que la recherche de contenu sur les sites web de commerce en ligne.
Lorsque vous créez une collection, vous choisissez l'un de ces cas d'utilisation. Pour de plus amples informations, veuillez consulter Choix d'un type de collection.
Comment ça marche
Les OpenSearch clusters traditionnels possèdent un ensemble unique d'instances qui effectuent à la fois des opérations d'indexation et de recherche, et le stockage d'index est étroitement lié à la capacité de calcul. En revanche, OpenSearch Serverless utilise une architecture native pour le cloud qui sépare les composants d'indexation (ingestion) des composants de recherche (requête), Amazon S3 étant le principal stockage de données pour les index.
Cette architecture découplée vous permet de mettre à l'échelle les fonctions de recherche et d'indexation indépendamment les unes des autres et indépendamment des données indexées dans S3. L'architecture permet également d'isoler les opérations d'ingestion et de requête afin qu'elles puissent s'exécuter simultanément sans conflit de ressources.
Lorsque vous écrivez des données dans une collection, OpenSearch Serverless les distribue aux unités de calcul d'indexation. Les unités de calcul d'indexation ingèrent les données entrantes et déplacent les index vers S3. Lorsque vous effectuez une recherche sur les données de collecte, OpenSearch Serverless achemine les demandes vers les unités de calcul de recherche qui contiennent les données demandées. Les unités de calcul de recherche téléchargent les données indexées directement depuis S3 (si elles ne sont pas déjà mises en cache localement), exécutent des opérations de recherche et effectuent des regroupements.
L'image suivante illustre cette architecture découplée :

OpenSearch La capacité de calcul sans serveur pour l'ingestion, la recherche et l'interrogation de données est mesurée en unités de OpenSearch calcul ()OCUs. Chaque OCU est une combinaison de 6 Gio de mémoire et du processeur virtuel (vCPU) correspondant et crée un transfert de données vers Amazon S3. Chaque OCU comprend suffisamment de stockage éphémère à chaud pour 120 Gio de données d'index.
Lorsque vous créez votre première collection, OpenSearch Serverless en instancie deux, l'une pour l'indexation OCUs et l'autre pour la recherche. Afin de garantir une haute disponibilité, il lance également un ensemble de nœuds de secours dans une autre zone de disponibilité. À des fins de développement et de test, vous pouvez désactiver le paramètre Activer la redondance pour une collection, ce qui élimine les deux répliques de secours et n'en instancie que deux. OCUs Par défaut, les répliques actives redondantes sont activées, ce qui signifie qu'un total de quatre répliques OCUs sont instanciées pour la première collection d'un compte.
Ils OCUs existent même lorsqu'il n'y a aucune activité sur les points de terminaison de collecte. Toutes les collections suivantes les partagent OCUs. Lorsque vous créez des collections supplémentaires dans le même compte, OpenSearch Serverless en ajoute uniquement OCUs pour la recherche et l'ingestion si nécessaire pour prendre en charge les collections, conformément aux limites de capacité que vous spécifiez. La capacité diminue à mesure que votre utilisation des ressources informatiques diminue.
Pour plus d'informations sur la façon dont ces frais vous sont facturés OCUs, consultezTarification.
Choix d'un type de collection
OpenSearch Serverless prend en charge trois types de collecte principaux :
Séries chronologiques : segment d'analyse des journaux qui analyse de grands volumes de données semi-structurées générées par des machines en temps réel, fournissant des informations sur les opérations, la sécurité, le comportement des utilisateurs et les performances de l'entreprise.
Recherche : recherche en texte intégral qui active les applications des réseaux internes, telles que les systèmes de gestion de contenu et les référentiels de documents juridiques, ainsi que les applications Internet telles que la recherche sur les sites de commerce électronique et la découverte de contenu.
Recherche vectorielle — La recherche sémantique sur les intégrations vectorielles simplifie la gestion des données vectorielles et permet des expériences de recherche augmentées par le machine learning (ML). Il prend en charge les applications d'IA génératives telles que les chatbots, les assistants personnels et la détection des fraudes.
Vous choisissez un type de collection lorsque vous créez une collection pour la première fois :
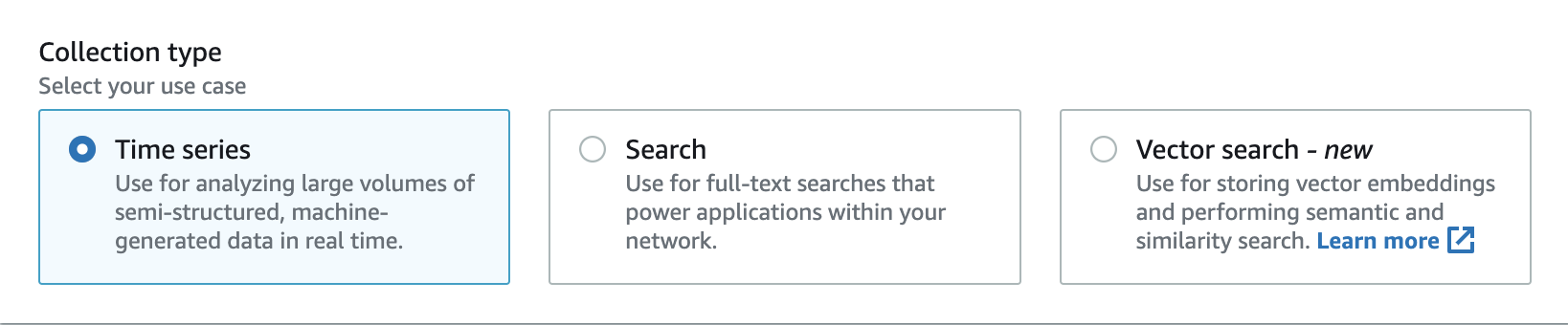
Le type de collection que vous choisissez dépend du type de données que vous prévoyez d'intégrer à la collection et de la manière dont vous allez les interroger. Vous ne pouvez pas modifier le type de la collection après l'avoir créée.
Les types de collection présentent les différences notables suivantes :
-
Pour les collections de recherche et de recherche vectorielle, toutes les données sont stockées dans un espace de stockage à chaud afin de garantir des temps de réponse rapides aux requêtes. Les collections de séries temporelles utilisent une combinaison de stockage à chaud et tiède, les données les plus récentes étant conservées dans un stockage hot afin d'optimiser les temps de réponse aux requêtes pour les données les plus fréquemment consultées.
-
Pour les séries chronologiques et les collections de recherche vectorielle, vous ne pouvez pas indexer par identifiant de document personnalisé ni mettre à jour par des requêtes upsert. Cette opération est réservée aux cas d'utilisation de recherche. Vous pouvez plutôt effectuer une mise à jour par numéro de document. Pour de plus amples informations, veuillez consulter Opérations et autorisations d' OpenSearch API prises en charge.
-
Pour les recherches et les collections de séries chronologiques, vous ne pouvez pas utiliser d'index de type K-nn.
Tarification
AWS vous facture les composants OpenSearch sans serveur suivants :
-
Calcul d'ingestion de données
-
Calcul de recherche et de requêtes
-
Stockage conservé dans Amazon S3
Une OCU comprend 6 Go de RAM, le vCPU GP3 correspondant, le stockage et le transfert de données vers Amazon S3. La plus petite unité qui peut vous être facturée est de 0,5 OCU. AWS facture OCU sur une base horaire, avec une granularité de second niveau. Dans votre relevé de compte, vous voyez une entrée pour le calcul en heures OCU avec une étiquette pour l'ingestion de données et une étiquette pour la recherche. AWS vous facture également sur une base mensuelle pour les données stockées dans Amazon S3. L'utilisation des OpenSearch tableaux de bord ne vous est pas facturée.
Lorsque vous créez une collection avec des répliques actives redondantes, un minimum de 1 OCU (0,5 OCU × 2) vous est facturé pour l'ingestion, y compris les répliques principale et de secours, et 1 OCU (0,5 OCU × 2) pour la recherche :
-
1 OCU (0,5 OCU × 2) pour l'ingestion, y compris l'unité primaire et la dose de réserve
-
1 OCU (0,5 OCU × 2) pour la recherche
Si vous désactivez les répliques actives redondantes, un minimum de 1 OCU (0,5 OCU x 2) vous sera facturé pour la première collecte enregistrée sur votre compte. Toutes les collections suivantes peuvent les partager OCUs.
OpenSearch Serverless ajoute des unités supplémentaires par incréments de 1 OCU OCUs en fonction de la puissance de calcul et du stockage nécessaires pour prendre en charge vos collections. Vous pouvez configurer un nombre maximum de OCUs pour votre compte afin de contrôler les coûts.
Note
Les collections uniques ne AWS KMS keys peuvent pas être partagées OCUs avec d'autres collections.
OpenSearch Serverless tente d'utiliser les ressources minimales requises pour tenir compte de l'évolution des charges de travail. Le nombre de OCUs fournitures fournies à tout moment peut varier et n'est pas exact. Au fil du temps, l'algorithme utilisé par OpenSearch Serverless continuera de s'améliorer afin de mieux minimiser l'utilisation du système.
Pour en savoir plus sur les tarifs, consultez les tarifs d'Amazon OpenSearch Service
Soutenu Régions AWS
OpenSearch Serverless est disponible dans un sous-ensemble de Régions AWS ce OpenSearch service disponible dans. Pour obtenir la liste des régions prises en charge, consultez la section Points OpenSearch de terminaison et quotas Amazon Service dans le Références générales AWS.
Limitations
OpenSearch Le mode Serverless présente les limites suivantes :
-
Certaines opérations OpenSearch d'API ne sont pas prises en charge. Consultez Opérations et autorisations d' OpenSearch API prises en charge.
-
Certains OpenSearch plugins ne sont pas pris en charge. Consultez OpenSearch Plugins pris en charge.
-
Il n'existe actuellement aucun moyen de migrer automatiquement vos données d'un domaine de OpenSearch service géré vers une collection sans serveur. Vous devez réindexer vos données d'un domaine vers une collection.
-
L'accès intercompte aux collections n'est pas pris en charge. Vous ne pouvez pas inclure les collections provenant d'autres comptes dans vos stratégies de chiffrement ou d'accès aux données.
-
Les OpenSearch plugins personnalisés ne sont pas pris en charge.
-
Les instantanés automatisés sont pris en charge pour les collections OpenSearch sans serveur. Les instantanés manuels ne sont pas pris en charge. Pour de plus amples informations, veuillez consulter Sauvegarde de collections à l'aide de snapshots.
-
La recherche et la réplication entre régions ne sont pas prises en charge.
-
Le nombre de ressources sans serveur que vous pouvez avoir dans un seul compte et une seule région est limité. Voir Quotas OpenSearch sans serveur.
-
L'intervalle d'actualisation des index dans les collections de recherche vectorielle est d'environ 60 secondes. L'intervalle d'actualisation des index dans les recherches et les collections de séries chronologiques est d'environ 10 secondes.
-
Le nombre de partitions, le nombre d'intervalles et l'intervalle d'actualisation ne sont pas modifiables et sont gérés par OpenSearch Serverless. La stratégie de partitionnement est basée sur le type de collecte et le trafic. Par exemple, une collection de séries chronologiques redimensionne les partitions primaires en fonction des goulots d'étranglement du trafic d'écriture.
-
Les fonctionnalités géospatiales disponibles sur OpenSearch les versions jusqu'à 2.1 sont prises en charge.
