Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolution des problèmes liés aux OpsWorks piles
Important
Le AWS OpsWorks Stacks service a atteint sa fin de vie le 26 mai 2024 et a été désactivé tant pour les nouveaux clients que pour les clients existants. Nous recommandons vivement aux clients de migrer leurs charges de travail vers d'autres solutions dès que possible. Si vous avez des questions sur la migration, contactez l' AWS Support équipe sur AWS Re:Post
Cette section présente certains problèmes courants liés à OpsWorks Stacks et leurs solutions.
Rubriques
Les instances d'une couche échouent toutes à un test de santé d'Elastic Load Balancing
Impossible de communiquer avec un Elastic Load Balancing Load Balancer
Impossible de supprimer les groupes de sécurité OpsWorks Stacks
Suppression accidentelle d'un OpsWorks groupe de sécurité Stacks
opsworks-agent Processus en cours d'exécution sur les instances
Impossible de gérer des instances
Problème : Vous ne pouvez plus gérer une instance que vous pouviez gérer auparavant. Dans certains cas, les journaux peuvent afficher une erreur semblable à celle-ci :
Aws::CharlieInstanceService::Errors::UnrecognizedClientException - The security token included in the request is invalid.
Cause : Cela peut se produire si une ressource en dehors d' OpsWorks sur laquelle dépend l'instance a été modifiée ou supprimée. Voici des exemples de modifications de ressource qui peuvent interrompre les communications avec une instance.
-
Un utilisateur ou un rôle IAM associé à l'instance a été supprimé accidentellement, en dehors de OpsWorks Stacks. Cela entraîne un échec de communication entre l' OpsWorks agent installé sur l'instance et le service OpsWorks Stacks. L'utilisateur qui est associé à une instance est requis tout au long de la durée de vie de l'instance.
-
La modification de configurations de volume ou de stockage pendant qu'une instance est hors ligne peut rendre une instance ingérable.
-
Ajout manuel d' EC2 instances à un ELB. OpsWorks reconfigure un équilibreur de charge Elastic Load Balancing attribué chaque fois qu'une instance entre ou quitte l'état en ligne. OpsWorks considère uniquement les instances dont il sait qu'elles sont des membres valides ; les instances ajoutées en dehors de OpsWorks ou par un autre processus sont supprimées. Toute instance est supprimée.
Solution : ne supprimez pas les utilisateurs ou les rôles IAM dont dépendent vos instances. Si possible, modifiez des configurations de volume ou de stockage uniquement tant que les instances dépendantes s'exécutent. OpsWorks À utiliser pour gérer l'équilibreur de charge ou les adhésions EIP des instances. OpsWorks Lorsque vous enregistrez une instance, pour éviter les problèmes liés à la gestion des instances enregistrées en cas de suppression accidentelle de l'utilisateur, ajoutez le --use-instance-profile paramètre à votre register commande pour utiliser le profil d'instance intégré de l'instance à la place.
Après une exécution Chef, les instances ne démarrent pas
Problème : sur les piles Chef 11.10 ou antérieures qui sont configurées pour utiliser les livres de recettes personnalisés, après qu'une exécution Chef a utilisée les livres de recettes de la Communauté, les instances ne démarrent pas. Les messages des journaux peuvent établir que les recettes n'ont pas pu être compilées (« Erreur de compilation de recette ») ou n'ont pas pu être chargées, car elles ne peuvent pas trouver une dépendance.
Cause : la cause la plus probable est que le livre de recettes personnalisé ou le livre de recettes de la communauté ne prend pas en charge la version Chef qu'utilise votre pile. Certains livres populaires de la communauté, tels que apt et build-essential, ont connu des problèmes de compatibilité avec Chef 11.10.
Solution : Sur les OpsWorks piles dont le paramètre Utiliser les livres de recettes Chef personnalisés est activé, les livres de recettes personnalisés ou communautaires doivent toujours prendre en charge la version de Chef utilisée par votre pile. Epinglez les livres de recettes de la communauté avec une version (à savoir, définissez le numéro de version du livre de recettes sur une version spécifique) qui est compatible avec la version Chef configurée dans les paramètres de votre pile. Pour trouver une version du livre de recettes de la communauté prise en charge, affichez le journal des modifications d'un livre des recettes dont la compilation a échoué et utilisez uniquement la version la plus récente du livre de recettes que votre pile prendra en charge. Pour épingler une version du livre de recettes, spécifiez un numéro de version exacte dans le fichier Berksfile du référentiel de votre livre de recettes personnalisé. Par exemple, cookbook 'build-essential', '= 3.2.0'.
Les instances d'une couche échouent toutes à un test de santé d'Elastic Load Balancing
Problème : vous attachez un équilibreur de charge Elastic Load Balancing à une couche de serveur d'applications, mais le bilan de santé de toutes les instances échoue.
Cause : Lorsque vous créez un équilibreur de charge Elastic Load Balancing, vous devez spécifier le chemin ping que l'équilibreur de charge appelle pour déterminer si l'instance est saine. Assurez-vous de spécifier un chemin d'accès ping approprié pour votre application ; la valeur par défaut est/index.html. Si votre application n'inclut pas un index.html, vous devez spécifier un chemin d'accès approprié ou la vérification du statut échoue. Par exemple, l'PHPApp application Simple utilisée dans Mise en route des piles Linux Chef 11 n'utilise pas index.html ; le chemin ping approprié pour ces serveurs est /.
Solution : Modifiez le chemin d'accès ping de l'équilibreur de charge. Pour plus d'informations, consultez Elastic Load Balancing.
Impossible de communiquer avec un Elastic Load Balancing Load Balancer
Problème : vous créez un équilibreur de charge Elastic Load Balancing et vous l'associez à une couche de serveur d'applications, mais lorsque vous cliquez sur le nom DNS ou l'adresse IP de l'équilibreur de charge pour exécuter l'application, le message d'erreur suivant s'affiche : « Le serveur distant ne répond pas ».
Cause : Si votre stack s'exécute dans un VPC par défaut, lorsque vous créez un équilibreur de charge Elastic Load Balancing dans la région, vous devez spécifier un groupe de sécurité. Le groupe de sécurité doit avoir les règles de trafic entrant qui autorisent le trafic entrant à partir de votre adresse IP. Si vous spécifiez default VPC security group (groupe de sécurité VPC par défau), la règle de trafic entrant par défaut n'accepte aucun trafic entrant.
Solution : Modifiez les règles de trafic entrant du groupe de sécurité pour accepter le trafic entrant à partir des adresses IP appropriées.
-
Cliquez sur Security Groups dans le volet de navigation de la EC2 console Amazon
. -
Sélectionnez le groupe de sécurité de l'équilibreur de charge.
-
Cliquez sur Modifier sous l'onglet Entrant.
-
Ajoutez une règle de trafic entrant avec le champ Source défini avec un CIDR approprié.
Par exemple, la spécification Anywhere définit le CIDR avec la valeur 0.0.0.0/0, qui demande à l'équilibreur de charge d'accepter le trafic entrant à partir de n'importe quelle adresse IP.
Une instance locale importée n'a pas réussi à finaliser la configuration du volume après un redémarrage
Problème : vous redémarrez une EC2 instance que vous avez importée dans OpsWorks Stacks, et la console OpsWorks Stacks affiche le statut de l'instance « échec ». Cela peut se produire sur les instances Chef 11 ou Chef 12.
Cause : OpsWorks Stacks ne parvient pas à attacher un volume à votre instance pendant le processus d'installation. Une cause possible est qu' OpsWorks
Stacks remplace votre configuration de volume sur votre instance lorsque vous exécutez la commande setup.
Solution : ouvrez la page Détails de l'instance et vérifiez votre configuration de volume dans la zone Volumes. Notez que vous pouvez changer la configuration de votre volume uniquement lorsque votre instance se trouve dans l'état stopped (arrêté). N'oubliez pas que chaque volume a un nom et un point de montage spécifiés. Vérifiez que vous avez fourni le bon point de montage dans votre configuration dans OpsWorks Stacks avant de redémarrer l'instance.
Un volume EBS ne se rattache pas après un redémarrage
Problème : vous utilisez la EC2 console Amazon pour associer un volume Amazon EBS à une instance, mais lorsque vous redémarrez l'instance, le volume n'est plus attaché.
Cause : OpsWorks Stacks ne peut rattacher que les volumes Amazon EBS dont il a connaissance, qui sont limités aux volumes suivants :
-
Volumes créés par OpsWorks Stacks.
-
Volumes de votre compte que vous avez explicitement enregistrés auprès d'une pile à l'aide de la page Ressources.
Solution : Gérez vos volumes Amazon EBS uniquement à l'aide de la console, de l'API ou de la CLI OpsWorks Stacks. Si vous souhaitez utiliser l'un des volumes Amazon EBS de votre compte avec une pile, utilisez la page Ressources de la pile pour enregistrer le volume et l'associer à une instance. Pour de plus amples informations, veuillez consulter Gestion des ressources.
Impossible de supprimer les groupes de sécurité OpsWorks Stacks
Problème : une fois que vous avez supprimé une pile, il reste un certain nombre de groupes de sécurité OpsWorks Stacks qui ne peuvent pas être supprimés.
Cause : Les groupes de sécurité doivent être supprimés selon un ordre particulier.
Solution : Tout d'abord, assurez-vous qu'aucune instance n'utilise les groupes de sécurité. Puis, supprimez l'un des groupes de sécurité ci-après, s'ils existent, dans l'ordre suivant :
-
AWS- OpsWorks -Blank-Server
-
AWS- OpsWorks -Monitoring-Master-Server
-
Serveur AWS- OpsWorks -DB-Master
-
Serveur AWS- OpsWorks -Memcached-Server
-
AWS- OpsWorks -Serveur personnalisé
-
Serveur d'applications AWS- OpsWorks -NodeJS
-
Serveur d'applications AWS- OpsWorks -PHP
-
Serveur d'applications AWS- OpsWorks -Rails
-
AWS- OpsWorks -Serveur Web
-
AWS- OpsWorks -Serveur par défaut
-
Serveur AWS- OpsWorks -LB
Suppression accidentelle d'un OpsWorks groupe de sécurité Stacks
Problème : vous avez supprimé l'un des groupes de sécurité OpsWorks Stacks et vous devez le recréer.
Cause : Ces groupes de sécurité sont généralement supprimés par accident.
Solution : Le groupe recréé doit être une copie exacte de l'original, y compris la même casse pour le nom du groupe. Au lieu de recréer le groupe manuellement, l'approche par défaut consiste à ce qu' OpsWorks Stacks exécute la tâche automatiquement. Créez simplement une nouvelle pile dans la même région AWS (et un VPC, le cas échéant OpsWorks ). Stacks recréera automatiquement tous les groupes de sécurité intégrés, y compris celui que vous avez supprimé. Vous pouvez ensuite supprimer la pile si vous n'en avez plus l'utilisation ; les groupes de sécurité demeureront.
Le journal Chef se termine brutalement
Problème : Un journal Chef se termine brutalement ; la fin du journal n'indique pas une exécution réussie ni n'affiche une exception et une trace de pile.
Cause : Ce comportement est généralement dû à une mémoire insuffisante.
Solution : Créez une plus grande instance et utilisez la commande run_command de l'interface de ligne de commande de l'agent pour exécuter les recettes à nouveau. Pour de plus amples informations, veuillez consulter Exécution des recettes.
Le livre de recettes n'est pas mis à jour
Problème : Vous avez mis à jour vos livres de recettes, mais les instances de la pile exécutent toujours les anciennes recettes.
Cause : OpsWorks Stacks met en cache les livres de recettes sur chaque instance et exécute les recettes à partir du cache, et non du référentiel. Lorsque vous démarrez une nouvelle instance, OpsWorks Stacks télécharge vos livres de recettes du référentiel vers le cache de l'instance. Cependant, si vous modifiez par la suite vos livres de recettes personnalisés, OpsWorks Stacks ne met pas automatiquement à jour les caches des instances en ligne.
Solution : exécutez la commande Update Cookbooks stack pour demander explicitement à OpsWorks Stacks de mettre à jour les caches de livres de recettes de vos instances en ligne.
Les instances sont bloquées à l'état de démarrage
Problème : lorsque vous redémarrez une instance ou que la réparation automatique la redémarre, l'opération de démarrage se bloque sur l'état booting.
Cause : une cause possible de ce problème est la configuration du VPC, VPC par défaut inclus. Les instances doivent toujours être en mesure de communiquer avec le service OpsWorks Stacks, Amazon S3, ainsi qu'avec les référentiels de packages, de livres de recettes et d'applications. Si, par exemple, vous supprimez une passerelle par défaut d'un VPC par défaut, les instances perdent leur connexion au service OpsWorks Stacks. Comme OpsWorks Stacks ne peut plus communiquer avec l'agent d'instance, il considère l'instance comme défaillante et la répare automatiquement. Cependant, sans connexion, OpsWorks Stacks ne peut pas installer d'agent d'instance sur l'instance réparée. Sans agent, OpsWorks Stacks ne peut pas exécuter les recettes de configuration sur l'instance, de sorte que l'opération de démarrage ne peut pas progresser au-delà de l'état de « démarrage ».
Solution : Modifiez la configuration de votre VPC afin que les instances aient la connectivité requise.
Redémarrage inattendu des instances
Problème : une instance arrêtée redémarre de façon inattendue.
Cause 1 : si vous avez activé la réparation automatique pour vos instances, OpsWorks Stacks vérifie régulièrement l'état des EC2 instances Amazon associées et redémarre celles qui ne fonctionnent pas correctement. Si vous arrêtez ou mettez fin à une instance OpsWorks gérée par Stacks à l'aide de la EC2 console, de l'API ou de la CLI Amazon, OpsWorks Stacks n'en est pas informé. Au lieu de cela, il considère l'instance arrêtée comme défectueuse et la redémarre automatiquement.
Solution : Gérez vos instances uniquement avec la console OpsWorks Stacks, l'API ou l'interface de ligne de commande. Si vous utilisez OpsWorks Stacks pour arrêter ou supprimer une instance, elle ne sera pas redémarrée. Pour plus d’informations, consultez Démarrage, arrêt et redémarrage manuels des instances 24/7 et Supprimer des OpsWorks instances de Stacks.
Cause 2 : Les instances peuvent échouer pour un grand nombre de raisons. Si la guérison automatique est activée, OpsWorks Stacks redémarre automatiquement les instances défaillantes.
Solution : Il s'agit d'un fonctionnement normal ; il n'est pas nécessaire de faire quoi que ce soit sauf si vous ne voulez pas que OpsWorks Stacks redémarre les instances défaillantes. Dans ce cas, vous devez désactiver la réparation automatique.
opsworks-agent Processus en cours d'exécution sur les instances
Problème : Plusieurs processus opsworks-agent sont en cours d'exécution sur vos instances. Par exemple :
aws 24543 0.0 1.3 172360 53332 ? S Feb24 0:29 opsworks-agent: master 24543 aws 24545 0.1 2.0 208932 79224 ? S Feb24 22:02 opsworks-agent: keep_alive of master 24543 aws 24557 0.0 2.0 209012 79412 ? S Feb24 8:04 opsworks-agent: statistics of master 24543 aws 24559 0.0 2.2 216604 86992 ? S Feb24 4:14 opsworks-agent: process_command of master 24
Cause : il s'agit de processus légitimes qui sont obligatoires pour le fonctionnement normal de l'agent. Ils exécutent des tâches telles que la gestion des déploiements et l'envoi de messages de connexion persistante au service.
Solution : il s'agit du comportement normal. N'arrêtez pas ces processus, sinon vous compromettrez le fonctionnement de l'agent.
Commandes execute_recipes inattendue
Problème : la section Logs de la page des détails d'une instance inclut des commandes execute_recipes inattendues. Des commandes execute_recipes inattendues peuvent également apparaître sur les pages Stack et Deployments.
Cause : ce problème est souvent provoqué par des modifications d'autorisation. Lorsque vous modifiez les autorisations SSH ou sudo d'un utilisateur ou d'un groupe, OpsWorks Stacks s'exécute execute_recipes pour mettre à jour les instances de la pile et déclenche également un événement Configure. Une autre source de commandes execute_recipes inattendues est la mise à jour par OpsWorks
Stacks de l'agent de l'instance.
Solution : Il s'agit d'un fonctionnement normal ; nul besoin de faire quoi que ce soit.
Pour voir quelles actions une commande execute_recipes exécute, accédez à la page Déploiements et cliquez sur l'horodatage de la commande. La page des détails de la commande s'ouvre et affiche les principales recettes qui ont été exécutées. Par exemple, la page de détails suivante concerne une commande execute_recipes qui a lancé ssh_users pour mettre à jour les autorisations SSH.
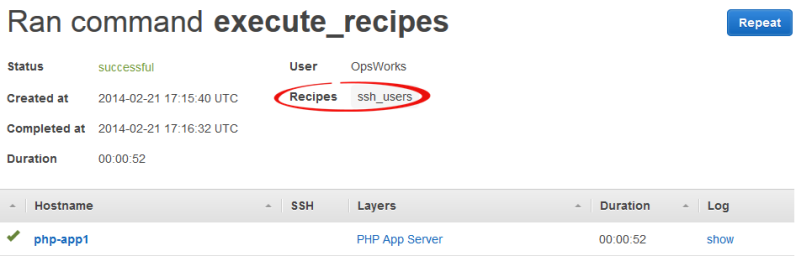
Pour voir tous les détails, cliquez sur afficher dans la colonne Journal de la commande afin d'afficher le journal Chef associé. Recherchez dans le journalRun List. OpsWorks Les recettes d'entretien des piles seront présentées ci-dessous. OpsWorks Custom Run List Par exemple, la liste suivante est la liste des exécutions de la commande execute_recipes affichée dans la capture d'écran précédente et illustre chaque recette associée à la commande.
[2014-02-21T17:16:30+00:00] INFO: OpsWorks Custom Run List: ["opsworks_stack_state_sync", "ssh_users", "test_suite", "opsworks_cleanup"]
