Memory-augmented agents
Memory-augmented agents are enhanced with the ability to store, retrieve, and reason using short-term and long-term memory. This allows them to maintain context across multiple tasks, sessions, and interactions, which produces more coherent, personalized, and strategic responses.
Unlike stateless agents, memory-augmented agents adapt by referencing historical data, learn from prior outcomes, and make decisions that align with the user's goals, preferences, and environment.
Architecture
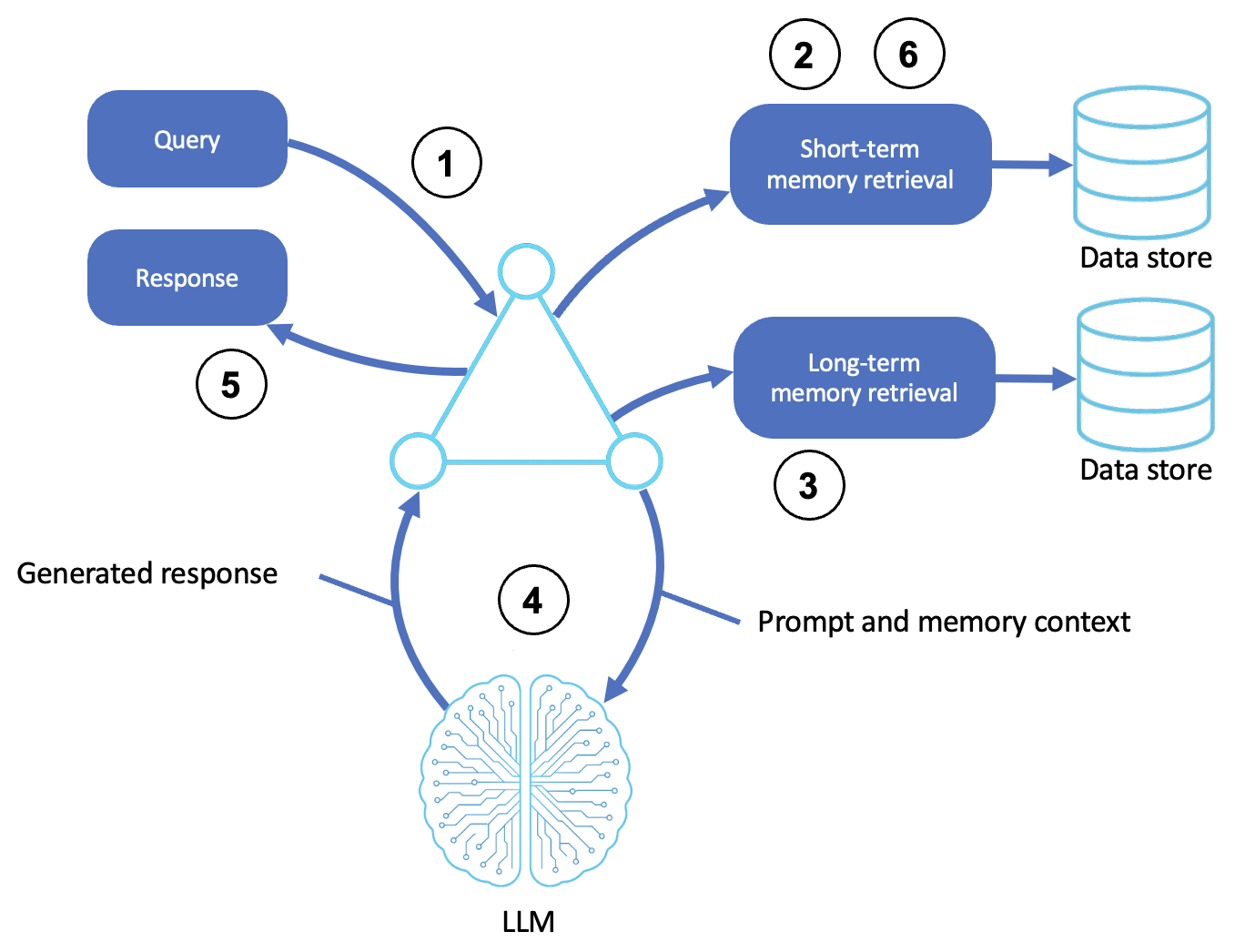
A memory-augmented agent is shown in the following diagram:
Description
-
Receives input or event
-
The agent receives a user query or system event. This may be a text, API trigger, or environmental change.
-
-
Retrieves short-term memory
-
The agent retrieves recent conversational history, task context, or the system state that's relevant to the session or workflow.
-
-
Retrieves long-term memory
-
The agent queries long-term memory (for example, vector databases and key-value stores) for historical insights, such as the following:
-
User preferences
-
Past decisions and outcomes
-
Learned concepts, summaries, or experiences
-
-
-
Reasons through the LLM
-
The memory context is embedded into the LLM prompt, allowing the agent to reason based on both current inputs and prior knowledge.
-
-
Generates outputs
-
The agent produces a contextually aware response, plan, or action that is personalized according to the task history and user's inputs.
-
-
Updates memory
-
New information, such as updated goals, success and failure signals, and structured responses, are stored for future tasks.
-
Capabilities
-
Session continuity across conversations or events
-
Goal persistence over time
-
Contextual awareness based on an evolving state
-
Adaptability informed by prior successes and failures
-
Personalization aligned with user preferences and history
Common use cases
-
Conversational copilots that remember user preferences
-
Coding agents that track codebase changes
-
Workflow agents that adapt according to task history
-
Digital twins that evolve from system knowledge
-
Research agents that avoid redundant retrievals
Implementing memory-augmented agents
Use the following tools and AWS services for memory-augmented agents:
Memory layer |
AWS service |
Purpose |
|---|---|---|
Short-term |
Amazon DynamoDB, Redis, Amazon Bedrock context |
Fast retrieval of recent interaction states |
Long-term (structured) |
Amazon Aurora, Amazon DynamoDB, Amazon Neptune |
Facts, relationships, and logs |
Long-term (semantic) |
OpenSearch, PostgreSQL, Pinecone |
Embedding-based retrieval (that is, RAG) |
Storage |
Amazon S3 |
Storing transcripts, structured memories, and files |
Orchestration |
AWS Lambda or AWS Step Functions |
Managing memory injection and update lifecycle |
Reasoning |
Amazon Bedrock |
Anthropic Claude or Mistral with memory prompts |
Implementing memory-injected prompting
To integrate memory into agent reasoning, use a combination of structured state and retrieval-augmented context injection:
-
Include the latest agent state and recent dialogue history as structured input when constructing the prompt for the language model, so it can reason with full context.
-
Use retrieval-augmented generation (RAG) to pull relevant documents or facts from long-term memory.
-
Summarize previous plans, context, and interactions for compression and relevance.
-
Inject external memory modules, such as vector stores or structured logs, during inference to guide decision making.
Summary
Memory-augmented agents maintain thought continuity by learning from experience and remembering user context. These agents surpass reactive intelligence by using long-term collaboration, personalization, and strategic reasoning. In terms of agentic AI, memory allows agents to behave more like adaptive digital counterparts and less like stateless tools.
