Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Lacs de données modernes
Cas d'utilisation avancés dans les lacs de données modernes
Les lacs de données constituent l'une des meilleures options pour stocker des données en termes de coût, d'évolutivité et de flexibilité. Vous pouvez utiliser un lac de données pour conserver de gros volumes de données structurées et non structurées à moindre coût, et utiliser ces données pour différents types de charges de travail analytiques, qu'il s'agisse de rapports de business intelligence, de traitement de mégadonnées, d'analyses en temps réel, d'apprentissage automatique ou d'intelligence artificielle générative (IA), afin de prendre de meilleures décisions.
Malgré ces avantages, les lacs de données n'ont pas été initialement conçus avec des fonctionnalités similaires à celles des bases de données. Un lac de données ne prend pas en charge la sémantique de traitement ACID (atomicité, cohérence, isolation et durabilité), dont vous pourriez avoir besoin pour optimiser et gérer efficacement vos données à grande échelle auprès de centaines ou de milliers d'utilisateurs en utilisant une multitude de technologies différentes. Les lacs de données ne fournissent pas de support natif pour les fonctionnalités suivantes :
-
Effectuer des mises à jour et des suppressions efficaces au niveau des enregistrements à mesure que les données changent dans votre entreprise
-
Gestion des performances des requêtes lorsque les tables se transforment en millions de fichiers et en centaines de milliers de partitions
-
Garantir la cohérence des données entre plusieurs rédacteurs et lecteurs simultanés
-
Empêcher la corruption des données lorsque les opérations d'écriture échouent en cours d'opération
-
Évolution des schémas de table au fil du temps sans réécriture (partielle) des ensembles de données
Ces défis sont devenus particulièrement courants dans les cas d'utilisation tels que la gestion de la capture des données modifiées (CDC) ou les cas d'utilisation relatifs à la confidentialité, à la suppression de données et à l'ingestion de données en streaming, ce qui peut entraîner des tables sous-optimales.
Les lacs de données qui utilisent les tables au format Hive traditionnelles ne prennent en charge les opérations d'écriture que pour des fichiers entiers. Cela rend les mises à jour et les suppressions difficiles à mettre en œuvre, longues et coûteuses. En outre, les contrôles de simultanéité et les garanties proposés dans les systèmes conformes à l'ACID sont nécessaires pour garantir l'intégrité et la cohérence des données.
Pour relever ces défis, Apache Iceberg fournit des fonctionnalités supplémentaires de type base de données qui simplifient l'optimisation et les frais de gestion des lacs de données, tout en prenant en charge le stockage sur des systèmes rentables tels qu'Amazon Simple Storage Service (Amazon
Présentation d'Apache Iceberg
Apache Iceberg est un format de table open source qui fournit des fonctionnalités dans les tables de lacs de données qui n'étaient auparavant disponibles que dans les bases de données ou les entrepôts de données. Il est conçu dans un souci d'évolutivité et de performance, et convient parfaitement à la gestion de tables de plus de centaines de gigaoctets. Certaines des principales caractéristiques des tables Iceberg sont les suivantes :
-
Supprimez, mettez à jour et fusionnez.Iceberg prend en charge les commandes SQL standard pour l'entreposage de données à utiliser avec les tables de lacs de données.
-
Planification rapide des scans et filtrage avancé. Iceberg stocke des métadonnées telles que les statistiques au niveau des partitions et des colonnes qui peuvent être utilisées par les moteurs pour accélérer la planification et l'exécution des requêtes.
-
Évolution complète du schéma. Iceberg permet d'ajouter, de supprimer, de mettre à jour ou de renommer des colonnes sans effets secondaires.
-
Évolution de la partition. Vous pouvez mettre à jour la disposition de partition d'une table à mesure que le volume de données ou les modèles de requête changent. Iceberg prend en charge la modification des colonnes sur lesquelles une table est partitionnée, l'ajout de colonnes ou la suppression de colonnes dans des partitions composites.
-
Partitionnement masqué.Cette fonctionnalité empêche la lecture automatique de partitions inutiles. Les utilisateurs n'ont donc plus besoin de comprendre les détails du partitionnement de la table ou d'ajouter des filtres supplémentaires à leurs requêtes.
-
Annulation de la version. Les utilisateurs peuvent rapidement corriger les problèmes en revenant à un état antérieur à la transaction.
-
Voyage dans le temps Les utilisateurs peuvent interroger une version précédente spécifique d'une table.
-
Isolation sérialisable. Les modifications apportées aux tables sont atomiques, de sorte que les lecteurs ne voient jamais de modifications partielles ou non validées.
-
Rédacteurs concurrents. Iceberg utilise une simultanéité optimiste pour permettre à plusieurs transactions de réussir. En cas de conflit, l'un des rédacteurs doit réessayer la transaction.
-
Formats de fichiers ouverts. Iceberg prend en charge plusieurs formats de fichiers open source, notamment Apache Parquet
, Apache Avro et Apache ORC.
En résumé, les lacs de données qui utilisent le format Iceberg bénéficient de la cohérence transactionnelle, de la rapidité, de l'échelle et de l'évolution des schémas. Pour plus d'informations sur ces fonctionnalités et sur d'autres fonctionnalités d'Iceberg, consultez la documentation d'Apache Iceberg
AWS support pour Apache Iceberg
Apache Iceberg est pris en charge par des frameworks de traitement de données open source populaires, Services AWS tels qu'Amazon EMR
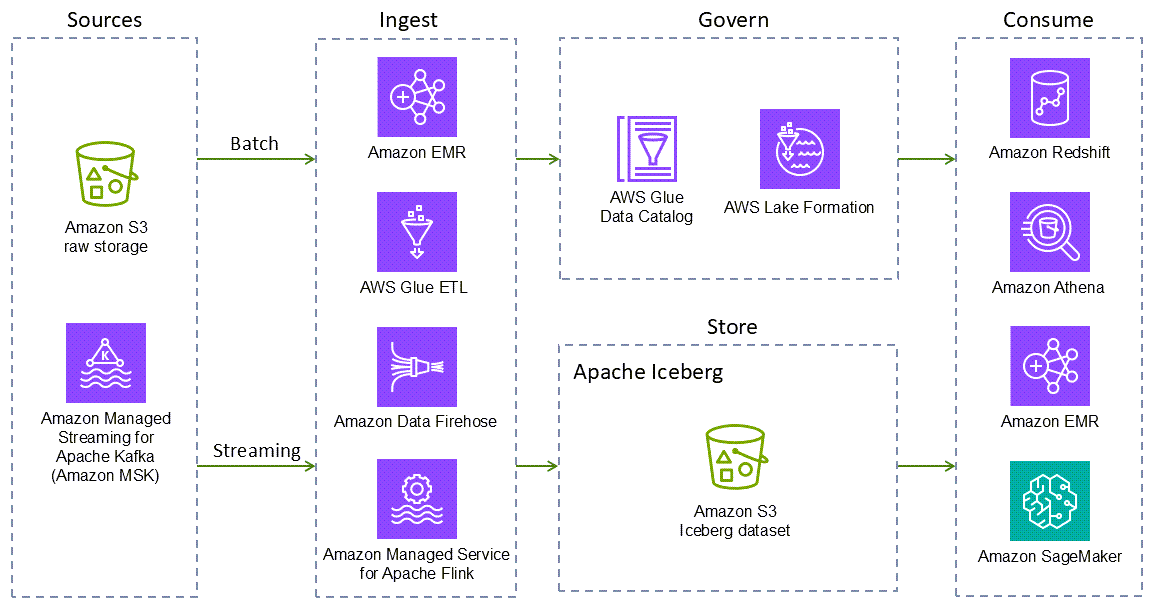
Les éléments suivants Services AWS fournissent des intégrations natives d'Iceberg. D'autres Services AWS peuvent interagir avec Iceberg, soit indirectement, soit en empaquetant les bibliothèques Iceberg.
-
Amazon S3 est le meilleur endroit pour créer des lacs de données en raison de sa durabilité, de sa disponibilité, de son évolutivité, de sa sécurité, de sa conformité et de ses fonctionnalités d'audit. Iceberg a été conçu et construit pour interagir de manière fluide avec Amazon S3 et prend en charge de nombreuses fonctionnalités d'Amazon S3 répertoriées dans la documentation d'Iceberg
. -
Amazon EMR est une solution de mégadonnées destinée au traitement de données à l'échelle du pétaoctet, à l'analyse interactive et à l'apprentissage automatique en utilisant des frameworks open source tels qu'Apache Spark, Flink, Trino et Hive. Amazon EMR peut s'exécuter sur des clusters Amazon Elastic Compute Cloud (Amazon EC2) personnalisés, Amazon Elastic Kubernetes Service (Amazon EKS) AWS Outposts ou Amazon EMR Serverless.
-
Amazon Athena est un service d'analyse interactif sans serveur basé sur des frameworks open source. Il prend en charge les formats de table ouverte et de fichier et fournit un moyen simplifié et flexible d'analyser des pétaoctets de données là où elles se trouvent. Athena fournit un support natif pour les requêtes de lecture, de voyage dans le temps, d'écriture et DDL pour Iceberg et utilise le AWS Glue Data Catalog métastore for the Iceberg.
-
Amazon Redshift est un entrepôt de données cloud de plusieurs pétaoctets qui prend en charge les options de déploiement basées sur des clusters et sans serveur. Amazon Redshift Spectrum peut interroger les tables externes enregistrées auprès AWS Glue Data Catalog d'Amazon S3 et stockées sur celui-ci. Redshift Spectrum prend également en charge le format de stockage Iceberg.
-
AWS Glueest un service d'intégration de données sans serveur qui facilite la découverte, la préparation, le déplacement et l'intégration de données provenant de sources multiples à des fins d'analyse, d'apprentissage automatique (ML) et de développement d'applications. AWS Glue Les versions 3.0 et ultérieures prennent en charge le framework Iceberg pour les lacs de données. Vous pouvez l'utiliser AWS Glue pour effectuer des opérations de lecture et d'écriture sur des tables Iceberg dans Amazon S3, ou utiliser des tables Iceberg à l'aide du. AWS Glue Data Catalog Des opérations supplémentaires telles que l'insertion, la mise à jour, les requêtes Spark et les écritures Spark sont également prises en charge.
-
AWS Glue Data Catalogfournit un service de catalogue de données compatible avec le métastore Hive qui prend en charge les tables Iceberg.
-
AWS Glue crawlerfournit des automatisations pour enregistrer les tables Iceberg dans le. AWS Glue Data Catalog
-
Amazon Data Firehose est un service entièrement géré qui fournit des données de streaming en temps réel à des destinations telles qu'Amazon S3, Amazon Redshift, Amazon Service, OpenSearch Amazon Serverless, OpenSearch Splunk, Apache Iceberg, ainsi qu'à tout point de terminaison HTTP ou HTTP personnalisé appartenant à des fournisseurs de services tiers pris en charge, notamment Datadog, Dynatrace LogicMonitor, MongoDB, New Relic, Coralogix et Elastic. Avec Firehose, vous n'avez pas besoin d'écrire d'applications ou de gérer des ressources. Vous configurez vos producteurs de données pour envoyer les données à Firehose, qui remet automatiquement les données à la destination que vous avez spécifiée. Vous pouvez également configurer Firehose pour transformer vos données avant de les remettre.
-
Amazon SageMaker AI prend en charge le stockage d'ensembles de fonctionnalités dans Amazon SageMaker AI Feature Store en utilisant le format Iceberg.
-
AWS Lake Formationfournit des autorisations de contrôle d'accès grossières et détaillées pour accéder aux données, notamment aux tables Iceberg consommées par Athena ou Amazon Redshift. Pour en savoir plus sur la prise en charge des autorisations pour les tables Iceberg, consultez la documentation de Lake Formation.
AWS propose une large gamme de services qui soutiennent Iceberg, mais la couverture de tous ces services dépasse le cadre de ce guide. Les sections suivantes traitent de Spark (streaming par lots et structuré) sur Amazon EMR et AWS Glue Amazon Athena SQL. La section suivante fournit un aperçu rapide du support d'Iceberg dans Athena SQL.
