Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture de référence
Le schéma suivant montre le flux de travail une fois que vous avez appliqué la solution automatisée de ce guide à un rapport d'exploitation quotidien. Lorsque de nouveaux fichiers sont ingérés dans Amazon Simple Storage Service (Amazon S3), ils peuvent être immédiatement visualisés dans QuickSight un tableau de bord après leur traitement.
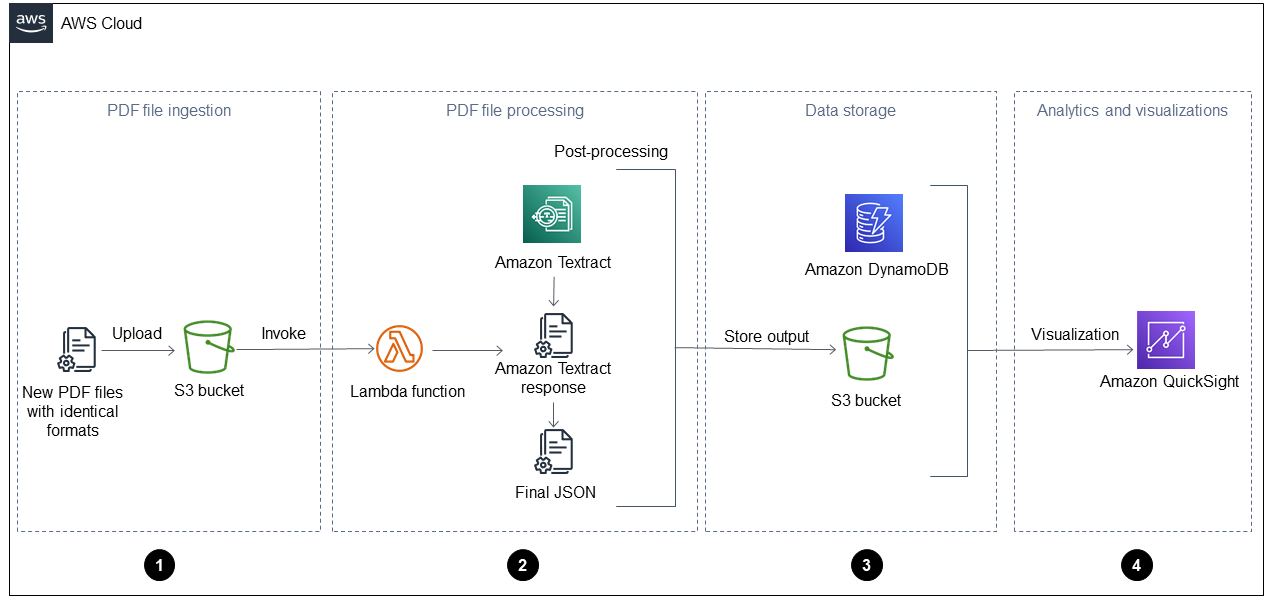
Le schéma montre les quatre phases suivantes :
-
Ingestion de fichiers PDF — Votre application ingère automatiquement les nouveaux fichiers PDF au format identique (par exemple, un rapport d'opérations quotidiennes) dans un bucket Amazon Simple Storage Service (Amazon S3). Amazon S3 lance un
ObjectCreatedévénement lorsque de nouveaux fichiers PDF sont ajoutés au compartiment, ce qui appelle une AWS Lambda fonction. Pour plus d'informations à ce sujet, consultez la section Utilisation d'un déclencheur Amazon S3 pour appeler une fonction Lambda dans la documentation Amazon S3. -
Traitement des fichiers PDF — La fonction Lambda envoie un fichier PDF à Amazon Textract, qui en extrait le contenu. Un script de post-traitement exécute et analyse la réponse d'Amazon Textract et utilise un modèle prédéfini pour ce type de fichier PDF. Ce modèle contient les attributs appropriés et permet d'extraire correctement toutes les paires clé-valeur, les tableaux et autres textes bruts. Pour plus d'informations à ce sujet, consultez le modèle Extraire automatiquement le contenu de fichiers PDF à l'aide d'Amazon Textract sur le site Web AWS Prescriptive Guidance.
-
Stockage des données : les données extraites et corrigées sont stockées dans une table Amazon DynamoDB, en plus d'un fichier JSON pour chaque fichier PDF. Les fichiers JSON sont stockés dans un compartiment S3 qui peut être utilisé par les services de traitement et d'analyse en aval, tels qu'Amazon Athena ou Amazon SageMaker AI. QuickSight
-
Analyses et visualisations : QuickSight analyse les données et crée des visualisations qui permettent de générer des informations pour tous les fichiers PDF traités. Une fois les tableaux de bord créés dans QuickSight, vous pouvez les partager avec vos utilisateurs finaux et vos équipes commerciales.
Considérations
La solution de ce guide convient au traitement de fichiers PDF au format identique et à la mise en page cohérente des formulaires et des tableaux. Cependant, vous devez définir un modèle et le modifier à l'avance pour automatiser complètement le processus et rendre les données extraites disponibles pour analyse. Ce modèle est ensuite utilisé lors du traitement avec la fonction Lambda.
Bien que cette solution puisse être appliquée simultanément à différents types de fichiers PDF, vous devez créer et définir des modèles distincts pour chaque type de fichier PDF et les stocker dans un emplacement accessible (par exemple, Amazon S3). Nous vous recommandons d'utiliser un identifiant unique pour chaque type de fichier PDF, tel qu'un nom de fichier PDF ou les différents dossiers de votre compartiment S3. La fonction Lambda peut ensuite appeler le modèle approprié lors du traitement du type de fichier PDF.
