Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Vue d'ensemble des vecteurs
Les vecteurs sont des représentations numériques qui aident les machines à comprendre et à traiter les données. Dans le domaine de l'IA générative, ils répondent à deux objectifs principaux :
-
Représentation des espaces latents qui capturent la structure des données sous forme compressée
-
Création d'intégrations pour des données telles que des mots, des phrases et des images
Les modèles d'intégration tels que Word2Vec GloVe
-
Apprenez à partir du contexte pour représenter les mots sous forme de vecteurs.
-
Placez des mots similaires plus près les uns des autres dans l'espace vectoriel.
-
Permettez aux machines de traiter les données dans un espace continu.
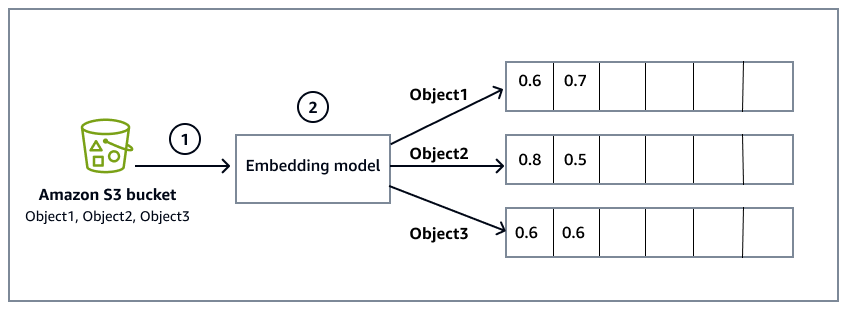
Le schéma suivant fournit une vue d'ensemble détaillée du processus d'intégration :
-
Un bucket Amazon Simple Storage Service (Amazon S3) contient des fichiers qui sont les sources de données à partir desquelles le système lit et traite les informations. Le compartiment S3 est spécifié lors de la configuration de la base de connaissances Amazon Bedrock, qui inclut également la synchronisation des données avec la base de connaissances.
-
Le modèle d'intégration convertit les données brutes des fichiers objets du compartiment S3 en intégrations vectorielles. Par exemple, Object1 est converti en un vecteur [0,6, 0,7,...], représentant son contenu dans un espace multidimensionnel.
Les intégrations de mots sont cruciales pour le traitement du langage naturel (NLP) car elles permettent :
-
Capturez les relations sémantiques entre les mots.
-
Activez la génération de texte pertinent en fonction du contexte.
-
Utilisez de grands modèles linguistiques (LLMs) pour produire des réponses semblables à celles des humains.
